- OpenBMB's VoxCPM 2 turns a plain-text description into a voice — no reference audio, no preset list.
- 2B params, 30 languages, 48 kHz, Apache-2.0.
- Here is why it changes the TTS game.
TL;DR
OpenBMB just shipped VoxCPM 2 — a 2-billion-parameter, tokenizer-free text-to-speech model that builds a voice from a natural-language description. No preset list. No reference clip. You type "raspy old man, tired" and it synthesizes that voice at 48 kHz studio quality across 30 languages plus 9 Chinese dialects. Weights and code are Apache-2.0, free for commercial use, and run on ~8 GB of VRAM at roughly real-time on an RTX 4090.

What's new
Traditional TTS pipelines hand you a drop-down: Matthew, Joanna, Brian. Clone a specific speaker and you need a reference clip plus consent. VoxCPM 2 collapses both flows into one idea — Voice Design — where the voice is a prompt:
- "Little girl, excited, end of a birthday party"
- "Pirate captain in a storm"
- "Soft-spoken, breathy female voice, ASMR"
- "Mid-40s gravel voice, documentary narrator"
The model generates that voice from scratch, with zero reference audio, and still supports controllable cloning when you do have a reference clip and want to tweak emotion, pace, or expression while keeping the original timbre.
Why it matters
Voice casting used to be a procurement problem — find an actor, license the voice, re-record when the script changes. With describable voice, casting becomes a prompt. Game studios can spin up NPC variants on demand. Audiobook producers can prototype narrators in minutes. Localization teams can hit 30 languages without a vendor network. Because VoxCPM 2 runs locally under Apache-2.0, teams that can't send audio to a third-party API (healthcare, legal, privacy-sensitive agents) finally have a 48 kHz studio-grade option on their own hardware.
Technical facts
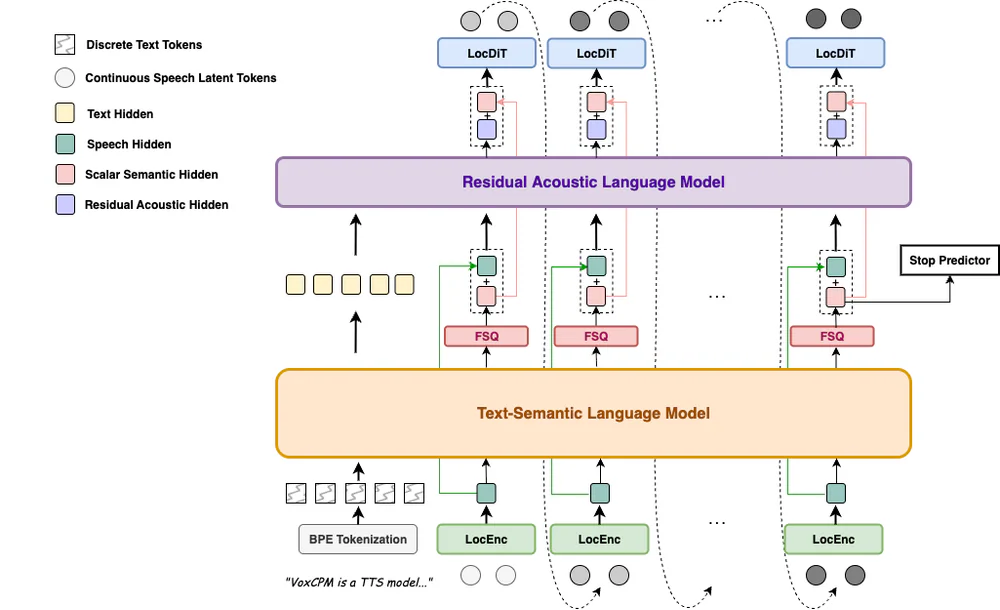
VoxCPM 2 is tokenizer-free — instead of quantizing speech into discrete tokens, it runs an end-to-end diffusion autoregressive pipeline directly on continuous speech representations. Four stages, built on the MiniCPM-4 backbone: LocEnc → TSLM → RALM → LocDiT.
| Property | Value |
|---|---|
| Parameters | 2B (MiniCPM-4 backbone, bfloat16) |
| Training data | 2M+ hours multilingual speech |
| Audio out | 48 kHz (AudioVAE V2, 16 kHz ref in → 48 kHz out) |
| LM token rate | 6.25 Hz |
| Max sequence | 8192 tokens |
| VRAM | ~8 GB (RTX 4090) |
| RTF | ~0.30 standard · ~0.13 with Nano-vLLM |
| Inference steps | 10 (configurable) |
On Seed-TTS-eval, VoxCPM 2 posts 1.84% English WER, 3.65% Chinese CER, and 8.55% on the hard subset. On an internal 30-language ASR benchmark the average error rate is 1.68% — 0.42% for English, 0.92% for Chinese. Voice Design scores on InstructTTSEval land at 85.2% APS / 71.5% DSD / 60.8% RP in Chinese and 84.2% / 83.2% / 71.4% in English.
Comparison
| Model | Params | Type | Notes |
|---|---|---|---|
| VoxCPM 2 | 2B | Open · Apache-2.0 | 30 langs, 48 kHz, describable voice, local |
| Fish Audio S2 | 4B | Open | 2× the params, matched or beaten on several metrics |
| Qwen3-TTS | 1.7B | Open | Smaller, lower quality baseline |
| CosyVoice 3 | 1.5B | Open | Strong but no native describable-voice mode |
| ElevenLabs | closed | API | Commercial leader — VoxCPM 2 wins on similarity |
| MiniMax-Speech · Seed-TTS | closed | API | Frontier closed models |
The real differentiator is not a WER decimal. ElevenLabs still does not ship an open "describe-a-voice" mode, and every closed API forces your audio through someone else's servers. VoxCPM 2 is the first model to combine all three: describable voice, fully local, free for commercial use.
Use cases
- Audiobooks & podcasts — cast a narrator by description, not by availability.
- Games & animation — batch-generate NPC VO variants, iterate on dialogue as code.
- Localization — one model, 30 languages, preserved timbre via controllable cloning.
- AI agents & assistants — local 48 kHz TTS with no cloud round-trip.
- Accessibility & education — read-aloud in the learner's language at studio quality.
- ASMR, meditation, creator content — style prompts ("breathy", "whispered", "excited") shape delivery directly.
Limitations & pricing
Price is the easy part: $0. Apache-2.0 weights on Hugging Face and GitHub, free for commercial use.
The honest caveats: Voice Design outputs vary between runs — the docs explicitly recommend generating 1–3 times to land the voice you want. Language quality is uneven — English and Chinese dominate the training set, long-tail languages get thinner coverage. Very long or hyper-expressive inputs can still produce instability. And OpenBMB is blunt on misuse: impersonation, fraud, and disinformation are strictly forbidden, and AI-generated content must be labelled. Runtime needs Python 3.10+ (<3.13), PyTorch ≥ 2.5, CUDA ≥ 12.0.
What's next
The VoxCPM 2 technical report is forthcoming. On the roadmap: tighter controllability consistency (fewer re-rolls to hit a voice) and language coverage beyond the current 30 — though new languages still require fine-tuning today. Production serving is already solid: Nano-vLLM-VoxCPM for async batched requests, and vLLM-Omni with an OpenAI-compatible /v1/audio/speech endpoint so existing clients drop in with minimal glue.
Nguồn: OpenBMB/VoxCPM, Hugging Face model card, official demo page.



