
- Cheat sheet so sánh training vs.
- inference complexity của 10 ML algorithms phổ biến trong 1 bảng duy nhất.
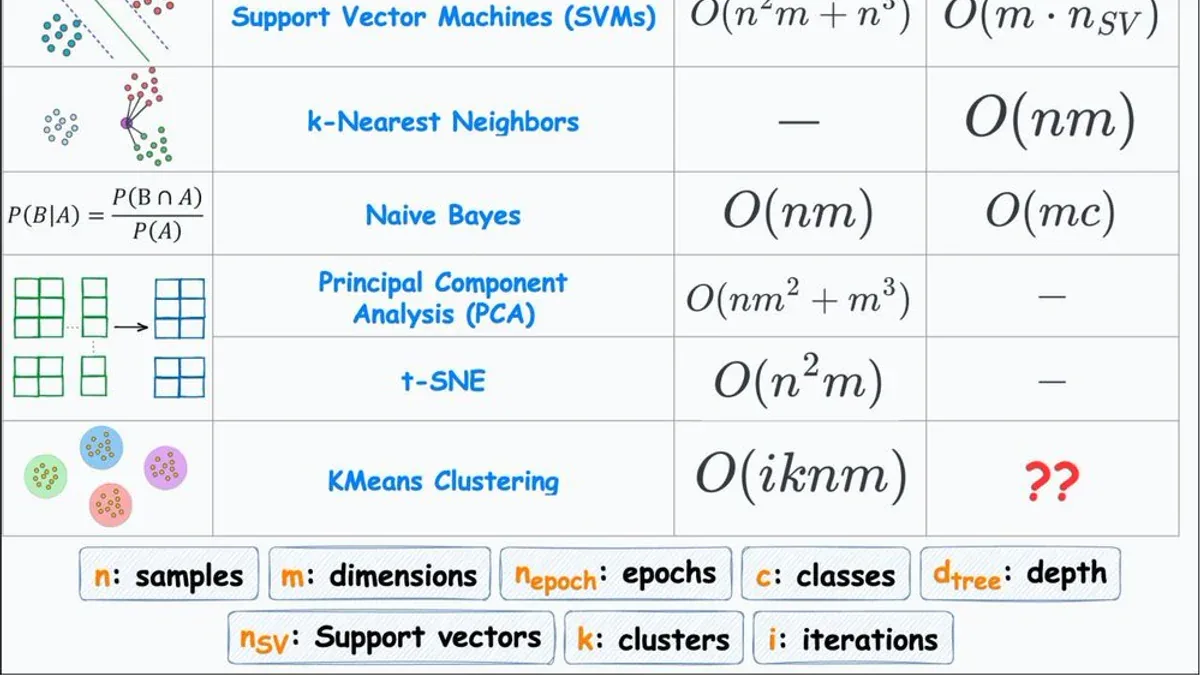
- KNN không có training cost nhưng inference là O(nm) - chậm nhất trong nhóm.
- SVM training O(n²m + n³) giải thích tại sao nó 'chết' trên dataset lớn.
- KMeans training là O(iknm), còn inference là '??' - câu đố mà tác giả cố tình để ngỏ.
TL;DR
Avi Chawla (Daily Dose of DS) tổng hợp training và inference time complexity của 10 ML algorithms phổ biến trong một visual duy nhất. Điểm nổi bật: KMeans training là O(iknm) nhưng inference được ghi là ?? - cố tình để ngỏ như một câu đố cho người đọc. Bài này giải đáp câu hỏi đó và phân tích toàn bộ bảng.
Cái Bẫy Của Hai Dòng Code
Scikit-learn quá dễ dùng. Chỉ 2-3 dòng là chạy được bất kỳ thuật toán nào. Vấn đề là chính sự tiện lợi đó khiến nhiều practitioner bỏ qua câu hỏi quan trọng nhất: thuật toán này scale như thế nào với data của mình?
Một số ví dụ thực tế về hậu quả của việc bỏ qua complexity:
- Chạy SVM trên dataset 1 triệu samples: training là O(n³) - tức là 10¹⁸ operations. Không bao giờ xong.
- Dùng t-SNE để visualize 500k điểm: O(n²m) - quadratic với n - memory và time đều nổ.
- Dùng PCA khi data có 50,000 features: O(nm² + m³) với m lớn - m³ sẽ giết chết server.
- Deploy KNN cho real-time recommendation: inference O(nm) tức mỗi request phải so sánh với toàn bộ training set.
Tất cả đều là lỗi phổ biến. Tất cả đều có thể tránh được nếu nhớ bảng Big-O dưới đây.
Bảng Big-O Đầy Đủ
Variables: n = samples, m = dimensions/features, k = clusters, i = iterations, c = classes, nSV = support vectors, dtree = tree depth, ntrees = số cây.
| Algorithm | Training | Inference |
|---|---|---|
| Linear Regression (OLS) | O(nm² + m³) | O(m) |
| Linear Regression (SGD) | O(n_epoch * nm) | O(m) |
| Logistic Regression (Binary) | O(n_epoch * nm) | O(m) |
| Logistic Regression (Multiclass) | O(n_epoch * nmc) | O(mc) |
| Decision Tree | O(n*log(n)*m) / O(n²m) worst | O(d_tree) |
| Random Forest | O(n_trees * n*log(n)*m) | O(n_trees * d_tree) |
| SVM | O(n²m + n³) | O(m * n_SV) |
| k-Nearest Neighbors (KNN) | - (không có) | O(nm) |
| Naive Bayes | O(nm) | O(mc) |
| PCA | O(nm² + m³) | - |
| t-SNE | O(n²m) | - |
| KMeans | O(iknm) | ?? |
Một vài quan sát thú vị từ bảng: KNN và SVM là cặp đối lập hoàn hảo - KNN training gần như miễn phí nhưng inference rất chậm, trong khi SVM training cực đắt nhưng inference chỉ phụ thuộc vào số support vectors. Linear models thắng tuyệt đối về inference speed: chỉ O(m), tức là tốc độ chỉ phụ thuộc vào số features, không phụ thuộc n.
Giải Đáp Bí Ẩn KMeans Inference
Avi Chawla cố tình để ?? cho KMeans inference như một câu đố. Câu trả lời không khó nếu hiểu cách KMeans hoạt động:
Khi có model đã train xong (tức đã có k centroids), để assign một điểm mới vào cluster, ta cần:
- Tính khoảng cách từ điểm đó đến mỗi centroid (
kcentroids) - Mỗi phép tính khoảng cách qua m dimensions
- Chọn centroid gần nhất
Vậy inference complexity của KMeans là: O(km) cho một sample, hoặc O(nkm) cho n samples mới.
So sánh với training O(iknm): inference không có factor i (iterations) vì không cần lặp - chỉ cần một lần tính khoảng cách đến k centroids. Đây là lý do KMeans sau khi train xong khá hiệu quả cho inference.
Chọn Thuật Toán Nào Cho Dataset Của Bạn?
Từ bảng trên, quy tắc chọn nhanh:
- Dataset lớn (n lớn), cần production-ready: Linear/Logistic Regression - inference
O(m), không phụ thuộc n. - Cần accuracy cao, chấp nhận train lâu: Random Forest - inference
O(n_trees * d_tree)vẫn ổn nếu giới hạn số cây. - Dataset nhỏ, nhiều features, cần high accuracy: SVM - tránh khi n lớn vì
O(n³). - Text classification, cần nhanh: Naive Bayes - training
O(nm), inferenceO(mc)- cực kỳ nhẹ. - Không cần real-time, dataset nhỏ: KNN - zero training cost nhưng inference
O(nm). - Dimensionality reduction: PCA khi m vừa phải (
O(m³)), tránh t-SNE khi n lớn (O(n²m)). - Unsupervised clustering: KMeans - inference
O(km)sau khi train.
Takeaway
Hiểu Big-O complexity không chỉ là lý thuyết - đây là kỹ năng engineering quyết định hệ thống của bạn có survive production hay không. Lần tới trước khi model.fit(X), hãy hỏi: "n và m của mình là bao nhiêu, và complexity scale như thế nào?"
Câu trả lời cho câu đố KMeans inference: O(km) per sample - đơn giản hơn training nhiều vì không cần iterate.


