
- Foundations of Large Language Models là sách học thuật 247 trang, miễn phí trên arXiv, bao phủ 5 trụ cột kỹ thuật từ pre-training đến inference.
- Tác giả Tong Xiao và Jingbo Zhu dùng ký hiệu toán học chuẩn với Q/K/V matrices, KL divergence, RLHF formal derivations.
- Chương 5 gồm inference-time scaling kiểu o1 - rare trong sách giáo khoa foundational.
- License CC BY-NC 4.0, tải PDF miễn phí tại arxiv.org/abs/2501.09223.
TL;DR
Tong Xiao và Jingbo Zhu từ NLP Lab Northeastern University vừa cập nhật phiên bản v2 (tháng 6/2025) của cuốn "Foundations of Large Language Models" - sách học thuật 247 trang bao phủ toàn bộ kỹ thuật nền tảng LLM: pre-training, generative models, prompting, alignment và inference. Miễn phí hoàn toàn, có mặt trên arXiv dưới license CC BY-NC 4.0. Nếu bạn muốn hiểu LLM ở cấp độ toán học thay vì chỉ "dùng được", đây là tài nguyên hiếm có.
Cuốn sách này là gì
"Foundations of Large Language Models" (arXiv:2501.09223) là sản phẩm của nhóm nghiên cứu NiuTrans - một trong những lab NLP lâu đời nhất tại Trung Quốc. Sách được trích xuất và mở rộng từ dự án NiuTrans NLPBook (github.com/NiuTrans/NLPBook), một nguồn giảng dạy NLP toàn diện được xây dựng từ 2021.
Điều phân biệt cuốn sách này với hầu hết tài liệu LLM hiện có: nó không phải survey liệt kê mọi thứ, cũng không phải coding tutorial. Nó nằm ở vị trí giữa - lý thuyết nghiêm ngặt với ký hiệu toán học đầy đủ, nhưng vẫn self-contained đủ để đọc từng chương độc lập. Preface của sách phát biểu thẳng: tập trung vào foundational aspects, không phải comprehensive coverage.
LaTeX source có sẵn trên arXiv - giáo viên có thể adapt trực tiếp cho khóa học của mình.
Kiến trúc 5 chương
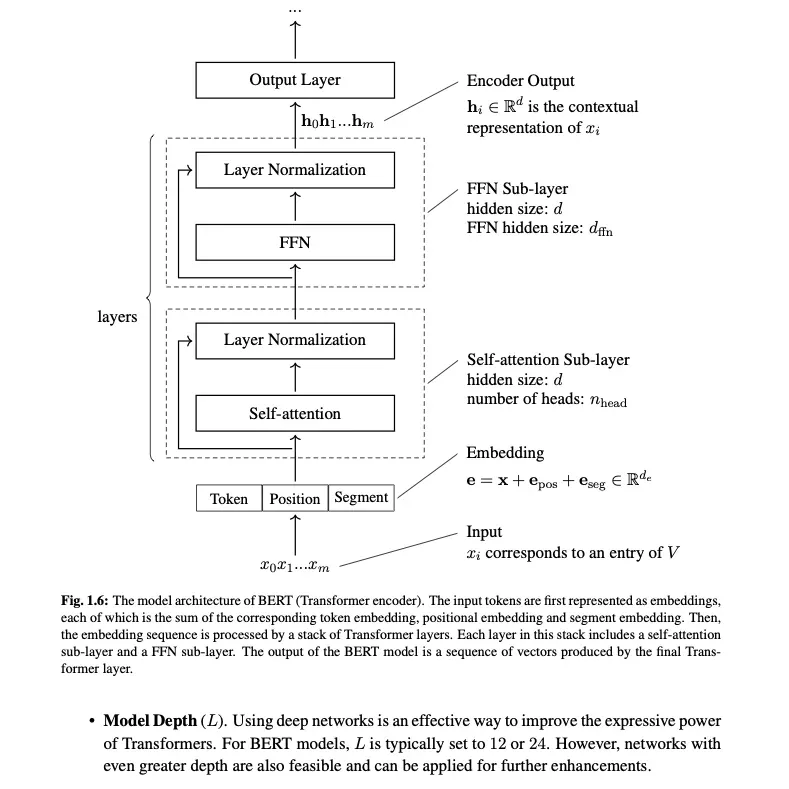
Sách chia làm 5 chương, mỗi chương là một trụ cột kỹ thuật:
- Ch.1 - Pre-training (tr. 1-35): Self-supervised learning, masked language modeling, BERT case study chi tiết (standard, larger, efficient variants, multilingual), decoder-only / encoder-only / encoder-decoder pre-training.
- Ch.2 - Generative Models (tr. 36-94): Decoder-only Transformers, training + fine-tuning + aligning LLMs, long sequence modeling - RoPE, ALiBi, KV cache, position extrapolation/interpolation.
- Ch.3 - Prompting (tr. 96-153): In-context learning, chain-of-thought, self-refinement, problem decomposition, ensembling, RAG, tool use, soft prompts, prompt optimization.
- Ch.4 - Alignment (tr. 155-201): Instruction fine-tuning (SFT), RLHF với reward modeling đầy đủ, DPO, automatic preference data generation, step-by-step alignment, inference-time alignment.
- Ch.5 - Inference (tr. 203-245): Prefilling & decoding, continuous batching, KV cache nâng cao, parallelization, và đặc biệt - inference-time scaling (context scaling, search scaling, output ensembling, generating & verifying thinking paths).
Toàn bộ sách dùng ký hiệu chuẩn hóa: Q, K, V matrices, ∂L/∂θ (gradient), KL(p||q), Pr(a|b), h_t (hidden state). Phương trình đánh số và cross-referenced xuyên suốt.
Tại sao đáng đọc
Vào đầu 2025, khi community AI tràn ngập tutorials "build chatbot trong 5 phút", một cuốn sách dám đặt ký hiệu toán học ở trang đầu tiên là điều hiếm gặp. Ba lý do cụ thể:
- Chapter 5 về Inference-time scaling - đây là kỹ thuật đằng sau o1-style models (generating & verifying thinking paths). Rất ít textbook foundational nào cover topic này vì nó còn quá mới tính tới đầu 2025.
- Alignment formal derivations - RLHF không chỉ giải thích conceptually mà có đầy đủ: RL basics, reward model training, policy training, DPO derivation. Đủ để researcher mới vào lĩnh vực bắt đầu implement.
- Long-context modeling trong Ch.2 - RoPE, ALiBi, position interpolation được trình bày đồng thời với KV cache optimization - hiếm thấy được đặt cạnh nhau như vậy trong một resource duy nhất.
Cộng đồng Hacker News đón nhận cuốn sách này khi phát hành v1 và có một thread thảo luận sôi nổi (news.ycombinator.com/item?id=42799629). Một số người dùng ngay bằng cách prompt ChatGPT tạo lecture 2 tiếng từ PDF - điều đó nói lên rằng sách đủ structured để serve như giáo trình.
Ai nên đọc ngay
Cuốn sách tự định vị cho 3 nhóm, và thực tế phù hợp với cả 5:
- Sinh viên / nghiên cứu sinh CS-AI-NLP: các chương self-contained, phù hợp làm reading list cho graduate course. Giáo viên có thể dùng LaTeX source để customize.
- NLP practitioners chuyển sang LLM: Ch.1 bridge rõ ràng từ classical pre-training (word embeddings, ELMo) sang Transformer paradigm.
- ML engineers triển khai LLM: Ch.5 thực tiễn - continuous batching, KV caching, parallelization đều ở đây.
- Alignment researchers mới vào: Ch.4 có RLHF + DPO formal, đủ để bắt đầu research.
- Builders RAG / prompting systems: Ch.3 chain-of-thought, self-refinement, RAG, tool use, soft prompts - rất applicable cho production systems.
Giới hạn cần biết
Trước khi đọc, nên biết những điều này:
- Chưa peer-reviewed: là arXiv preprint, không qua formal academic review.
- Không bao phủ multimodal, code LLMs, hay agent frameworks: scope giới hạn ở text-based language models.
- Nhanh lỗi thời một phần: v2 cover đến late 2024; các model như o3, DeepSeek R2, Claude 3.7 extended thinking chưa có trong sách.
- License CC BY-NC 4.0: không dùng thương mại (ví dụ trong khóa học trả phí) mà không xin phép tác giả.
Tải về và tài nguyên
Toàn bộ tài nguyên miễn phí:
- PDF: arxiv.org/pdf/2501.09223
- arXiv page: arxiv.org/abs/2501.09223
- Parent NLPBook project: github.com/NiuTrans/NLPBook
- LaTeX source: có sẵn trên arXiv (tải source.tar.gz)
Nguồn: arXiv 2501.09223, HuggingFace Papers, Hacker News discussion.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ