
- Microsoft công bố SkillOpt, framework treat file SKILL.md như trainable parameter của frozen LLM agent.
- Trên GPT-5.5, SkillOpt cộng +23.5 điểm accuracy trong direct chat, +24.8 trong Codex và +19.1 trong Claude Code.
- Best hoặc tied trên cả 52/52 cell (model x benchmark x harness).
- Skill artifact 300-2000 token, MIT license, không tốn thêm inference call lúc deploy.
TL;DR
Microsoft Research vừa open source SkillOpt, một text-space optimizer treat file Markdown skill như trainable parameter của một frozen LLM agent. Optimizer model phân tích trajectory, đề xuất edit add/delete/replace có giới hạn token (textual learning rate), chỉ accept khi pass validation gate trên held-out split. Kết quả: trên GPT-5.5, average no-skill accuracy nhảy +23.5 điểm trong direct chat, +24.8 điểm trong Codex agentic loop, và +19.1 điểm trong Claude Code. Best hoặc tied trên cả 52/52 cell (model, benchmark, harness) via arxiv 2605.23904.

SkillOpt là gì
Trong các agent frozen-model phổ biến hôm nay (Codex, Claude Code, agent dùng GPT-5.5), "skill" thường được viết tay hoặc generate one-shot bằng LLM. Cách tiếp cận đó không có metric, không có validation, không cách nào so sánh hai bản skill khác nhau ngoài cảm tính.
SkillOpt đưa kỷ luật của weight-space optimization vào không gian văn bản. Skill document trở thành parameter. Trajectory-derived edits trở thành gradient direction. Edit budget trở thành learning rate. Held-out split trở thành validation check. Output cuối cùng là một file best_skill.md dài 300-2000 token, plug vào agent là dùng, không tốn thêm inference-time call via repo microsoft/SkillOpt.
Vòng lặp 4 pha
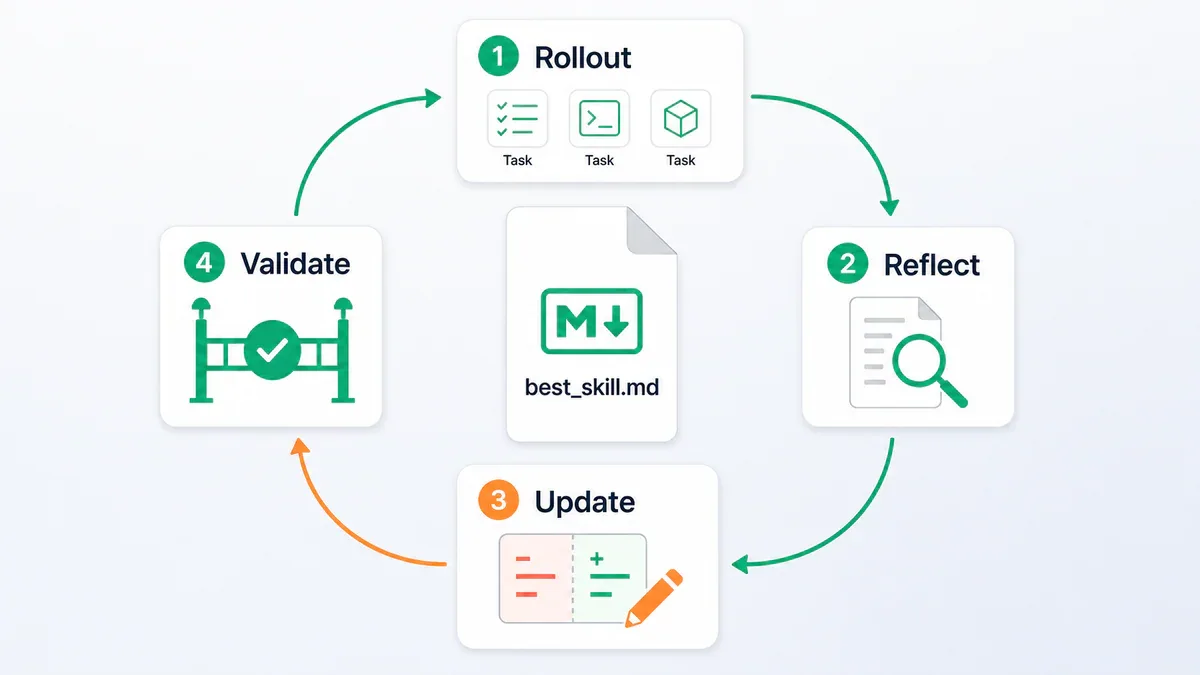
- Rollout - Target model chạy task trong minibatch với skill hiện tại, sinh ra scored trajectory.
- Reflect - Một optimizer model riêng phân tích success và failure, đề xuất edit dạng add/delete/replace có cấu trúc, rank chúng dưới một budget cap (chính là textual learning rate).
- Update - Aggregate các edit thắng cuộc, apply lên skill doc.
- Validate - Test skill mới trên held-out split. Nếu strictly improve thì accept; ngược lại reject và lưu vào buffer để optimizer không lặp lại lỗi cũ.
Default config trong repo: epochs=4, batch_size=40, workers=8. Epoch-wise slow/meta update giữ training ổn định, tương tự momentum/LR schedule trong weight training.
Kết quả benchmark
Paper đánh giá trên 52 cell (model x benchmark x harness) gồm SearchQA, ALFWorld, DocVQA, LiveMathematicianBench, SpreadsheetBench và OfficeQA. SkillOpt best hoặc tied trên cả 52/52 cell và beat từng competitor per-cell, gồm human-written skill, one-shot LLM-generated, Trace2Skill, TextGrad, GEPA, EvoSkill.
Con số nổi bật nhất nằm ở GPT-5.5:
- Direct chat: +23.5 điểm accuracy so với no-skill baseline.
- Codex agentic loop: +24.8 điểm.
- Claude Code: +19.1 điểm.
Skill artifact giữ giá trị khi transfer cross-model scale, di chuyển giữa Codex và Claude Code harness, và sang một math benchmark gần kề mà không cần optimize lại - signal cho thấy rule học được không overfit vào một harness cụ thể via mager.co.
Ý tưởng song song: Hermes Agent
SkillOpt không phải team duy nhất nhìn ra leverage này. Hermes Agent đi đến cùng kết luận qua bộ skill_manage + Curator + một optimization loop có tên GEPA - score, mutate, promote skill document qua các run. Akshay Pachaar gọi đây là tín hiệu hội tụ: hai team, hai kiến trúc, cùng một câu trả lời rằng file skill là thứ leverage cao nhất để optimize trong một frozen-model agent.
Khi nào nên thử
- Bạn đang chạy coding agent (Codex hoặc Claude Code) và muốn ép accuracy lên 15-25 điểm mà không động vào trọng số model.
- Bạn có một bộ task với scoring function rõ ràng và có thể chia held-out split.
- Bạn không có budget fine-tune model lớn nhưng muốn có quy trình version-controllable cho "prompt engineering" của mình.
- Bạn cần skill artifact đem share/transfer giữa các môi trường thực thi khác nhau.
Repo MIT, Python 3.10+, hỗ trợ Azure OpenAI, OpenAI API, Anthropic Claude và Qwen qua local vLLM. Cài đặt bằng pip install -e . sau khi clone.
Hạn chế
- Cần evaluator/scoring function rõ ràng. Domain open-ended như viết creative chưa có lời giải tự nhiên.
- Optimizer model nên thuộc tier mạnh (paper dùng frontier model làm optimizer) - chi phí API rollout + optimize không nhỏ.
- Chất lượng skill cuối cùng vẫn phụ thuộc chất lượng tập task và held-out split - tập task nghèo thì skill học ra cũng nghèo.
- Số liệu trên paper đo bằng GPT-5.5; với model nhỏ hơn, mức gain có thể giảm dù xu hướng tổng thể vẫn dương.
Kết
SkillOpt là một bước đi gọn gàng để biến "prompt engineering" từ nghệ thuật thành kỹ thuật có epoch, batch, learning rate và validation gate. Với người đang sống trong Codex hoặc Claude Code mỗi ngày, +19 đến +25 điểm accuracy bằng cách training một file Markdown là con số khó bỏ qua. Bài học rộng hơn: trong kỷ nguyên frozen model, file skill có lẽ chính là layer kế tiếp đáng để "train".