- vLLM là default cho hầu hết team.
- SGLang thắng vLLM 30-40% TTFT với workload RAG và prefix-heavy.
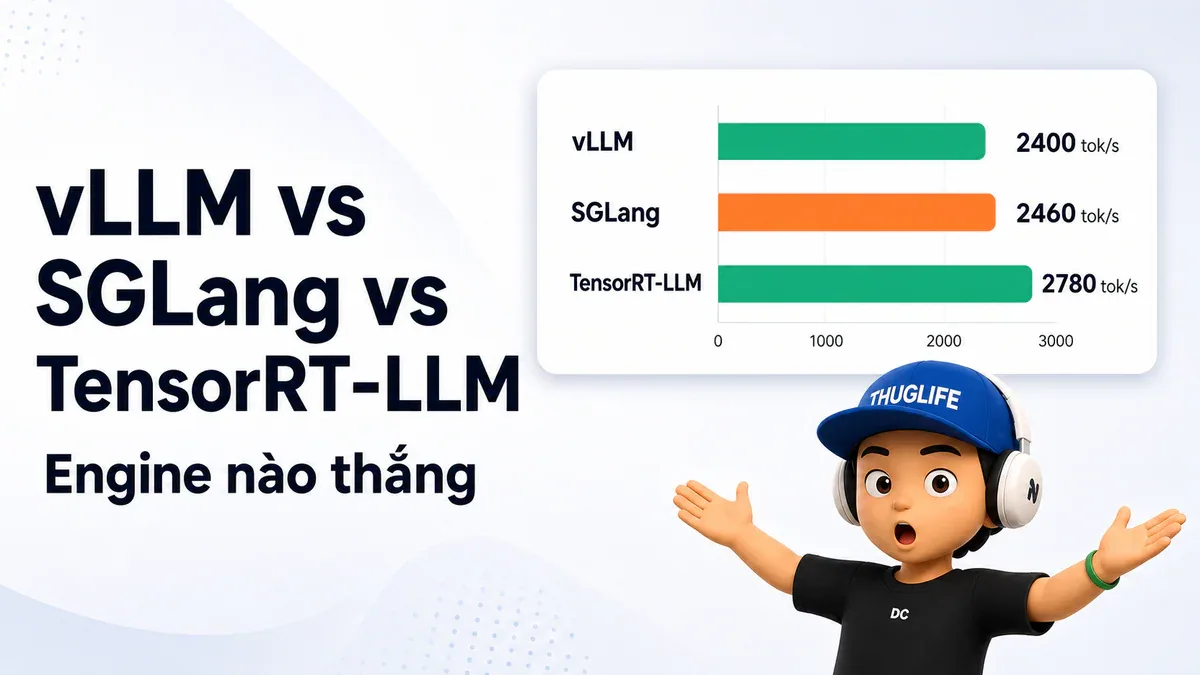
- TensorRT-LLM đạt 4.500 tok/s trên H100 nhưng đòi compile 28 phút mỗi lần đổi model.
- TGI chính thức deprecated tháng 3/2026.
- Bài 3/4 trong series Inference Engine 2026.
TL;DR
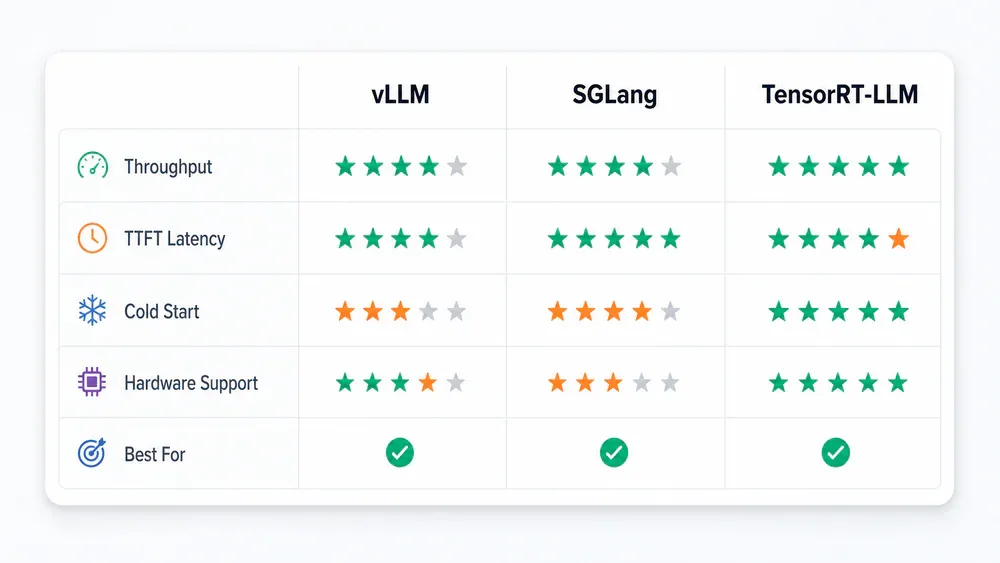
- vLLM: Default production cho hầu hết team. Breadth rộng nhất, cold start ~62s, hỗ trợ hàng trăm model architecture
- SGLang: Chọn khi workload heavy về prefix-heavy, RAG, structured output, MoE hoặc long-context
- TensorRT-LLM: Chỉ khi committed NVIDIA và throughput tối đa là ưu tiên số một - đánh đổi bằng compile 28 phút
- TGI: Đã deprecated (March 2026) - không dùng cho project mới
vLLM - Default open-source production server
Nếu ai đó nói "chúng ta cần serve open model trong production", vLLM là điểm khởi đầu mặc định.
vLLM mang lại: PagedAttention-based KV memory management, continuous batching, chunked prefill, prefix caching, CUDA/HIP graphs, quantization rộng (FP8, MXFP8/MXFP4, NVFP4, INT8, INT4, GPTQ, AWQ, GGUF), optimized attention và GEMM/MoE kernels, speculative decoding, torch.compile, và disaggregated prefill/decode/encode.
PagedAttention là innovation cốt lõi: quản lý KV cache như virtual memory pages của OS. Thay vì pre-allocate bộ nhớ liền kề cho toàn bộ max context length, allocate block nhỏ theo nhu cầu và recycle khi xong. Kết quả: cùng hardware có thể batch từ 2-5 lên 10-50 requests đồng thời. vLLM đạt 3.500 tok/s trên A100 80GB cho Llama 70B - cao hơn 40% so với baseline.
Phiên bản v0.21.0 (May 15, 2026, Apache 2.0). Hardware support: NVIDIA (core), AMD ROCm, CPU, Google TPU, Intel Gaudi, Huawei Ascend, Apple Silicon (plugin). API surface: OpenAI, Anthropic Messages, gRPC. Multi-GPU: tensor/pipeline/data/expert/context parallelism. Multi-node deployments thường dùng Ray (từ v0.18.0 Ray không còn là default dependency - install thêm nếu cần).
Trap cần tránh: Đừng nghĩ vLLM xóa bỏ hết systems thinking. Vẫn cần tune batching, context length, GPU memory utilization, parallelism layout và routing. vLLM cho bạn engine rất tốt - không phải auto-tune cho bạn.
Verdict: Nếu team cần serve open model trong production, vLLM là điểm khởi đầu. Default cho 5-20 concurrent users.
SGLang - Người thách thức systems-brained
SGLang là lựa chọn khi workload phức tạp hơn: structured outputs, long context, MoE, disaggregation và routing.
Innovation định nghĩa SGLang là RadixAttention: lưu KV cache activations trong radix tree theo token sequence. Khi hai request có chung prefix (system prompt, document, few-shot examples), SGLang tính KV cache cho prefix đó một lần và reuse cho tất cả request kế tiếp. Kết quả: 10 user hỏi về cùng document 10.000 từ - SGLang chỉ process document đó một lần.
TTFT của SGLang: 80-120ms trên single request, nhanh hơn 30-40% so với vLLM (~150ms). Tuy nhiên với unique prompts (không có shared prefix), advantage gần như biến mất.
SGLang v0.5.9 bổ sung: TRT-LLM DSA kernels cho DeepSeek V3.2 (3x-5x speedup trên Blackwell), native Anthropic API compatibility, LoRA weight loading overlap giảm TTFT ~78% cho LoRA adapter workloads, và hỗ trợ mở rộng cho Qwen3.5, Kimi-K2.5, GLM-5, MiniMax 2.5.
Differentiator kiến trúc: Prefill-decode disaggregation tách compute-intensive prefill khỏi memory-intensive decode vào các instance chuyên biệt, truyền KV cache giữa chúng. Điều này ngăn prefill batch dài làm gián đoạn decode và spike token latency.
Verdict: SGLang cho team mà bottleneck không còn là "chạy được model không" mà là "chạy được dưới hostile traffic mà không đốt latency, memory và chi phí không?"
TensorRT-LLM - Hiệu năng NVIDIA tối đa
TensorRT-LLM là stack NVIDIA-max-performance. Tối ưu cao, chuyên biệt, mạnh mẽ và không giả vờ portable.
Thay vì chạy weights qua general-purpose PyTorch runtime, TensorRT-LLM compile model thành optimized CUDA kernel graph, tùy chỉnh cho GPU, batch size và sequence length cụ thể của bạn. Kết quả: compiled engine binary khai thác hardware efficiency nhiều hơn bất kỳ runtime-based approach nào.
Benchmark thực tế (100 concurrent requests, H100):
- TensorRT-LLM: 2.780 tok/s
- SGLang: 2.460 tok/s
- vLLM: 2.400 tok/s
TensorRT-LLM outperform vLLM 30-50% ở high concurrency - đây là lý do Perplexity và các major cloud provider chọn nó. FP8 trên H100 có thể double performance và halve memory consumption so với 16-bit. B200 hỗ trợ FP4 weights với optimized kernels.
Đánh đổi lớn nhất: compile time. Compiled engine path đòi 25-40 phút compile trên H100 cho mỗi model version. Model lock theo GPU type và CUDA version - đổi model là phải compile lại. Không hợp với blue-green deploys hay auto-scaling từ zero.
Từ v1.0+, PyTorch backend là stable default - load HuggingFace weights trực tiếp, cold start ~60-90s, không cần compile. Throughput thấp hơn compiled path nhưng loại bỏ hoàn toàn barrier.
Không có OpenAI-compatible server built-in - production stack thường pair TensorRT-LLM với Triton Inference Server.
Verdict: Committed NVIDIA, care về absolute performance - TensorRT-LLM thuộc bake-off. Đánh đổi portability lấy performance. Nếu model thay đổi thường xuyên, dùng PyTorch backend hoặc xem xét vLLM/SGLang.
Phần còn lại của thị trường
TGI (Text Generation Inference): HuggingFace chính thức deprecated tháng 3/2026, archived cùng ngày. Không dùng cho project mới - HuggingFace khuyến khích vLLM, SGLang, llama.cpp hoặc MLX.
LMDeploy: CUDA-focused toolkit với TurboMind (performance) và PyTorch (accessibility). Đáng chú ý cho CUDA users muốn thêm lựa chọn ngoài vLLM/SGLang/TensorRT-LLM.
MLC LLM: Compiler-first universal deployment - từ REST, Python, JavaScript đến iOS và Android. Tốt nhất cho "ship LLM everywhere", đặc biệt browser, mobile và native apps.
ONNX Runtime GenAI: Implement full generative loop qua ONNX Runtime, hỗ trợ CPU, CUDA, DirectML, TensorRT-RTX, OpenVINO, QNN, WebGPU. Tốt cho app deployment và ONNX workflows.
OpenVINO GenAI: Intel-optimized cho Xeon CPUs, Arc GPUs, Core Ultra và NPUs. OpenAI-compatible serving với continuous batching và paged attention.
NVIDIA Dynamo: Orchestration layer bên trên engines như vLLM, SGLang và TensorRT-LLM - disaggregation, intelligent routing, multi-tier KV caching. Dùng khi single-engine serving không còn đủ.
Kết: Ba câu hỏi tóm tắt cách chọn
Bạn không cần nhớ tất cả. Chỉ cần trả lời ba câu:
- Workload có shared prefixes không (RAG, multi-turn)? → SGLang
- Cần model flexibility và quick deploys? → vLLM
- NVIDIA-only datacenter và throughput là ưu tiên số một? → TensorRT-LLM
Bài tiếp theo - phần 4 và cũng là phần cuối - tổng hợp hardware recipes theo từng setup cụ thể, cách benchmark đúng và 10 sai lầm hay gặp nhất. via Ahmad Osman, Spheron H100 Benchmarks, BIZON.