
- Inference engine không phải là model - nó là lớp phần mềm quyết định latency, chi phí và khả năng mở rộng.
- Prefill là compute-bound, decode là memory bandwidth-bound, và 5 bottleneck thực sự không liên quan gì đến thông số GPU bạn thường xem.
- Bài đầu trong series 4 phần về Self-hosted LLM 2026.
TL;DR
Bạn không chọn inference engine trước. Bạn chọn hardware strategy, workload shape, và serving model. Engine đi theo sau. Đây là nguyên tắc số một của bài viết này - và của toàn bộ series.
- Laptop/edge/hardware lạ → llama.cpp
- Mac-first → MLX / MLX-LM
- Một RTX local → ExLlamaV2
- 2-4+ NVIDIA GPU → ExLlamaV3
- Production serving phổ thông → vLLM
- Long-context / MoE / routing phức tạp → SGLang
- Hiệu năng NVIDIA tối đa → TensorRT-LLM
- Orchestration cụm máy → NVIDIA Dynamo
Inference Engine không phải là model
Một sai lầm phổ biến: nghĩ rằng chọn engine là chuyện phụ, chọn model mới quan trọng. Thực tế ngược lại. Model định nghĩa trí tuệ của ứng dụng. Engine quyết định latency, chi phí và khả năng mở rộng.
Hãy hình dung inference engine như một hệ thống điều phối: nó vừa là traffic cop (quyết định request nào vào batch), vừa là memory manager (phân bổ VRAM cho weights và KV cache), vừa là kernel dispatcher (chọn kernel CUDA tối ưu theo hardware), vừa là scheduler (ưu tiên request nào xử lý trước), vừa là API surface (endpoint OpenAI-compatible cho app kết nối).

Các engine phục vụ những mục đích rất khác nhau và ở các tầng khác nhau: portability local, consumer CUDA, Apple unified-memory, quantized inference, production serving, distributed orchestration, và vendor-optimized datacenter execution. Engine tốt nhất là engine khớp với memory hierarchy, interconnect, quantization format, latency và throughput target, kiến trúc model, và độ trưởng thành vận hành của bạn.
Hai giai đoạn: Prefill và Decode
Mọi LLM inference đều có hai phase với đặc tính hoàn toàn khác nhau.
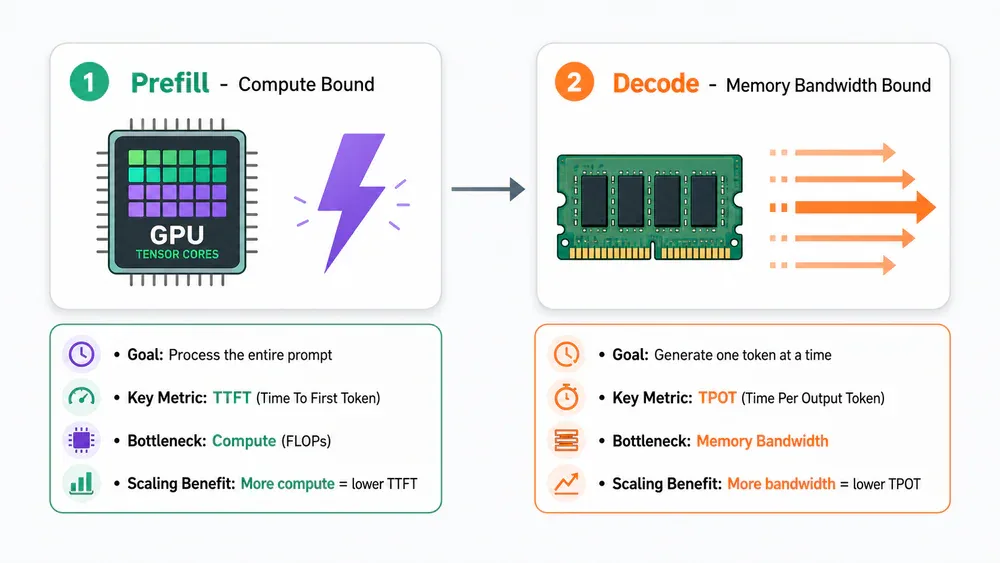
Prefill đọc toàn bộ prompt và xây dựng KV cache ban đầu. Đây là giai đoạn compute-bound - tận dụng tối đa tensor cores của GPU. Một prompt 10.000 token mất khoảng 200-400ms trên H100. Metric đo: Time to First Token (TTFT).
Decode sinh từng token một, lặp đi lặp lại đọc weights và KV cache. Đây là giai đoạn memory-bandwidth-bound - tốc độ decode bám theo memory bandwidth, không phải peak compute. Metric đo: Time Per Output Token (TPOT), thường 30-150 tok/s mỗi request.
Sự phân biệt này giải thích gần như tất cả:
- Prompt ngắn, output dài: decode chiếm ưu thế → memory bandwidth và batching quan trọng hơn
- Prompt dài, output ngắn: prefill chiếm ưu thế → attention kernels và chunked prefill quan trọng
- Nhiều user đồng thời: scheduler quality là chìa khóa → continuous batching, cache paging
- Long context: KV cache chiếm chủ đạo → paged attention, KV quantization
- Mô hình MoE: expert routing chi phối → expert parallelism, interconnect, grouped GEMMs
- Multi-node: interconnect chi phối → NVLink, RDMA, pipeline parallelism
PagedAttention giải quyết bài toán phân mảnh KV cache. FlashAttention dùng IO-aware tiling để giảm traffic HBM. Speculative decoding sinh token nháp rẻ rồi verify song song. Chủ đề lặp đi lặp lại: hiệu năng inference = quản lý memory movement + scheduling.
5 bottleneck thực sự
Khi đánh giá hay debug một hệ thống inference, 5 thứ sau đây mới là nơi mọi vấn đề xuất phát:
1. Memory bandwidth, không chỉ VRAM size. VRAM xác định model có fit vào không. Bandwidth xác định tốc độ decode. Apple M3 Ultra đạt 819 GB/s unified-memory bandwidth. NVIDIA H100 SXM đạt 3,35 TB/s GPU memory bandwidth. Unified memory cho phép fit model to hơn. HBM cho phép serve nhanh hơn khi model đã fit. Fit không đồng nghĩa nhanh - capacity không phải bandwidth.
2. KV cache growth. KV cache tăng theo batch size và context length. Với model 70B và context 200.000 token, KV cache có thể chiếm 40-80 GB VRAM - gần hết 80 GB của một H100 - chưa kể weights. PagedAttention chia KV cache thành các block nhỏ, tăng utilization và hỗ trợ batch lớn hơn.
3. Interconnect. Khi model vượt qua ranh giới GPU (multi-GPU), bạn phải trả chi phí communication. Tensor parallelism cần all-reduce collectives thường xuyên. Pipeline parallelism giao tiếp tại stage boundaries. Expert parallelism cần all-to-all traffic cho MoE. Không có NVLink: pipeline parallelism thường thắng tensor parallelism.
4. Scheduler quality. Scheduler tốt quyết định request nào vào batch, prefill và decode chia sẻ accelerator thế nào, prompt dài có block decode ngắn không, và tránh starvation ra sao. Có hỗ trợ batching và hoạt động như production scheduler là hai chuyện khác nhau hoàn toàn.
5. Runtime overhead. CUDA graphs, kernel fusion, sampling overhead, tokenizer overhead, HTTP overhead, LoRA switching và structured decoding đều có chi phí. Ở quy mô lớn, những overhead 2% này cộng lại thành vấn đề đáng kể. Stacking FP8 + Flash Attention 3 + continuous batching + speculative decoding trên H100 mang lại hiệu quả chi phí cao hơn 5-8 lần so với FP16 inference với static batching thông thường.
Bộ câu hỏi quyết định
Trước khi chọn bất kỳ engine nào, hãy trả lời những câu hỏi này:
- Hardware thực tế tôi có là gì?
- Model có fit trong fast memory không, hay chỉ fit trong system/unified memory?
- Decode hay prefill là bottleneck chính?
- Context length và concurrency mục tiêu là bao nhiêu?
- Prompt có đủ chung để dùng prefix caching không?
- Model dense, MoE, multimodal hay hybrid?
- Tôi cần local convenience, production serving hay fleet orchestration?
- Quantization format nào có optimized kernels trên engine mục tiêu?
- Interconnect của tôi là PCIe, NVLink, NVSwitch, Ethernet, RDMA hay Thunderbolt?
- Tôi đang tối ưu latency, throughput, chi phí, privacy, portability hay tốc độ phát triển?
Engine đi theo sau câu trả lời - không bao giờ ngược lại.
Kết: Series 4 phần về Inference Engine 2026
Bài này là nền tảng lý thuyết. Ba bài tiếp theo đi sâu vào từng nhóm engine:
- Phần 2: Bộ 4 engine local - llama.cpp, MLX, ExLlamaV2 và ExLlamaV3
- Phần 3: Production engines - vLLM, SGLang, TensorRT-LLM và phần còn lại của thị trường
- Phần 4: Hardware recipes theo từng setup, benchmark đúng cách và 10 sai lầm hay gặp
Series này dựa trên phân tích của Ahmad Osman - Phần 3 trong series Self-hosted LLMs / Local AI 2026 của ông, kết hợp với benchmark thực tế từ Spheron và phân tích từ BIZON.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ