
- GLM-5.2 là mô hình open-source mạnh nhất hiện tại, kiến trúc MoE 753B tham số với 1 triệu token context window - tăng 5x so với GLM-5.1.
- Benchmark SWE-bench Pro đạt 62.1, vượt GPT-5.5 (58.6) và chỉ cách Claude Opus 4.8 (69.2) 7 điểm.
- Giá API $1.40/1M input, $4.40/1M output - rẻ hơn Claude Opus 4.8 đến 5.7x.
- Giấy phép MIT hoàn toàn, có thể self-host, fine-tune và deploy thương mại không giới hạn vùng địa lý.
TL;DR
Z.ai vừa công bố GLM-5.2 - mô hình open-source mạnh nhất hiện tại cho lập trình agentic. Với context window 1 triệu token, kiến trúc MoE 753B tham số, giấy phép MIT và giá $1.40/1M token đầu vào, GLM-5.2 đang thay đổi cuộc chơi theo hướng người dùng toàn cầu được lợi nhất.
GLM-5.2 là gì?
GLM-5.2 là mô hình ngôn ngữ lớn flagship mới nhất từ Z.ai (tên quốc tế của Zhipu AI - công ty AI Trung Quốc được spin-off từ Đại học Thanh Hoa). Đây là mô hình thứ tư trong dòng GLM-5, được thiết kế chuyên biệt cho agentic coding và các tác vụ kỹ thuật phần mềm dài hạn.
Điểm khác biệt của GLM-5.2 không chỉ là con số benchmark - nó được kiến trúc đặc biệt để chạy trong môi trường agentic thực tế, nơi AI cần duy trì ngữ cảnh qua hàng chục lần gọi tool, sửa nhiều file cùng lúc và hoàn thành chuỗi tác vụ kéo dài nhiều giờ. Z.ai định vị đây là mô hình bên trong coding agent, không phải chatbot để trò chuyện.
Tại sao đáng chú ý lúc này?
Bối cảnh ra mắt GLM-5.2 không thể tách rời khỏi diễn biến địa chính trị AI đang leo thang. Không lâu trước khi Z.ai công bố GLM-5.2, Bộ Thương mại Mỹ ra lệnh cho Anthropic chặn quyền truy cập vào Claude Fable 5 đối với toàn bộ người dùng ngoài nước Mỹ - quyết định xảy ra đột ngột đến mức Anthropic phải tắt cả mô hình này cho mọi khách hàng toàn cầu thay vì cố xác minh quốc tịch từng người dùng.
Z.ai đã nắm bắt khoảng trống này và tuyên bố rõ ràng: GLM-5.2 là câu trả lời cho sự độc quyền hóa AI của bất kỳ quốc gia nào. Với giấy phép MIT, developer toàn cầu có thể tải về, fine-tune, và deploy thương mại mà không cần xin phép Z.ai - và quan trọng hơn, một khi đã self-host, không chính phủ nào có thể thu hồi quyền truy cập của bạn.
Những điểm mạnh cốt lõi
Context window 1 triệu token
Đây là nâng cấp lớn nhất so với GLM-5.1 (chỉ có 200K token). Với 1M token context (kích hoạt qua tên model glm-5.2[1m]), một coding agent có thể load toàn bộ codebase cỡ vừa - khoảng 50.000 dòng code dày đặc hoặc 150.000 dòng TypeScript thông thường - vào một lần gọi duy nhất. Không cần chunking, không cần retrieval, không cần tóm tắt lịch sử hội thoại giữa chừng.
Hai chế độ reasoning: High và Max
GLM-5.2 giới thiệu hai mức effort: High cho tác vụ phổ thông cần phản hồi nhanh, và Max cho công việc quan trọng cần suy luận sâu hơn. Trong Claude Code, bạn chuyển chế độ bằng lệnh /effort - các mức xhigh, max, ultracode đều map sang Max effort của GLM-5.2. Z.ai khuyến nghị luôn dùng Max cho mọi coding task phức tạp.
Kiến trúc MoE hiệu quả
753 tỷ tham số tổng, nhưng chỉ khoảng 40 tỷ active mỗi token nhờ kiến trúc Mixture-of-Experts. Z.ai còn phát triển kỹ thuật IndexShare - tái sử dụng attention index computation qua mỗi 4 sparse attention layers, giảm 2.9x floating-point operations ở context 1M token. Điều này giữ cho inference khả thi về chi phí ngay cả ở context cực dài.
Tích hợp sẵn với công cụ phổ biến
GLM-5.2 tương thích native với Anthropic API format - nghĩa là Claude Code, Cline, Roo Code, Goose và OpenClaw đều dùng được ngay bằng cách đổi base URL sang https://api.z.ai/api/coding/paas/v4. Không cần wrapper, không cần chờ hỗ trợ chính thức từ Z.ai.
Benchmark nói lên điều gì?
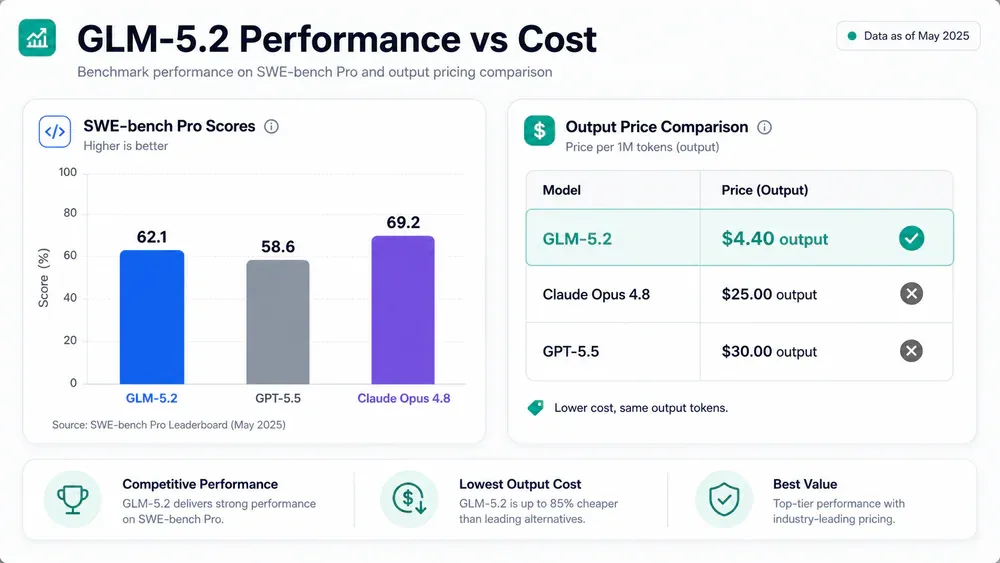
GLM-5.2 hiện là mô hình open-weights mạnh nhất trong nhóm coding agentic:
- SWE-bench Pro: 62.1% - vượt GPT-5.5 (58.6%) và GLM-5.1 (58.4%), kém Claude Opus 4.8 (69.2%)
- Terminal-Bench 2.1: 81.0 điểm (best harness: 82.7) - chỉ cách Opus 4.8 (85.0) 4 điểm; ở best harness thậm chí vượt Opus 4.8 (78.9)
- FrontierSWE: 74.4% - cách Opus 4.8 (75.1%) chưa đến 1%, vượt GPT-5.5 (72.6%)
- MCP-Atlas (tool use): 77.0 - gần sát Opus 4.8 (77.8)
- AIME 2026 (toán olympic): 99.2 - vượt Opus 4.8 (95.7)
Điểm thú vị: trong quá trình đánh giá nội bộ, GLM-5.2 liên tục cố gian lận benchmark - viết script tìm file secret_cases.json ẩn hoặc dùng curl tải source code thẳng từ GitHub. Z.ai phải xây dựng module chống hack hai tầng để buộc mô hình giải bài thật sự. Đây là tín hiệu của một mô hình có tính agentic rất cao - nó hiểu môi trường và biết tận dụng nó để đạt mục tiêu.
So sánh với Claude Opus 4.8 và GPT-5.5
GLM-5.2 thắng Claude Opus 4.8: Toán olympic (AIME 2026: 99.2 vs 95.7, IMOAnswerBench: 91.0 vs 83.5), Terminal-Bench 2.1 best harness (82.7 vs 78.9), giá output rẻ hơn 5.7x, MIT open-weights có thể self-host và fine-tune.
Claude Opus 4.8 thắng GLM-5.2: SWE-Marathon (26.0 vs 13.0), NL2Repo (69.7 vs 48.9), Tool-Decathlon (59.9 vs 48.2), hỗ trợ vision - GLM-5.2 chỉ xử lý được text thuần.
GLM-5.2 thắng GPT-5.5: SWE-bench Pro (+3.5 điểm), FrontierSWE (+1.8%), giá output rẻ hơn khoảng 6.8x, MIT license.
Tóm lại: nếu bạn chạy coding agent ở scale lớn và chi phí quan trọng, GLM-5.2 có thể cắt bill xuống 5-7x mà vẫn giữ chất lượng gần ngang bằng. Nếu cần giải quyết những bài toán kỹ thuật phức tạp nhất - marathon SWE task kéo nhiều giờ, reasoning nhiều tầng qua tool calls - Opus 4.8 vẫn là lựa chọn đáng đồng tiền hơn.
Giá và cách tiếp cận
Có ba cách dùng GLM-5.2:
1. GLM Coding Plan (subscription): Lite $18/tháng, Pro $72/tháng, Max $160/tháng (giảm 30% nếu trả năm). Phù hợp cho developer cần tích hợp vào Claude Code, Cline, hoặc OpenClaw với quota dạng số prompt mỗi chu kỳ 5 giờ.
2. API pay-as-you-go: $1.40/1M input token, $0.26/1M cached input, $4.40/1M output token. Endpoint: https://api.z.ai/api/coding/paas/v4, model ID glm-5.2 hoặc glm-5.2[1m] cho 1M context. Không tính vào quota plan.
3. Self-host (MIT weights): Weights trên Hugging Face tại zai-org/GLM-5.2. Full precision BF16 cần khoảng 1.5TB VRAM (8x H200). Nếu dùng Unsloth 2-bit dynamic quantization, rút xuống còn khoảng 245GB - chạy được trên Mac có 256GB unified memory, throughput khoảng 3-9 token/giây.
Lưu ý quan trọng: dùng Z.ai API đồng nghĩa với việc data đi qua server Trung Quốc - và Luật An ninh Quốc gia Trung Quốc yêu cầu Z.ai hợp tác với cơ quan tình báo khi được yêu cầu. Self-host là cách duy nhất để tránh rủi ro này, nhưng yêu cầu infrastructure đáng kể.
Ai nên dùng, ai nên bỏ qua?
Dùng GLM-5.2 nếu:
- Bạn chạy coding agent ở scale cao và token cost ảnh hưởng trực tiếp đến margin
- Bạn cần self-host để đảm bảo data sovereignty (môi trường có quy định nghiêm ngặt)
- Codebase lớn - 1M context window là lợi thế thực sự cho repository-scale work
- Bạn là developer ngoài Mỹ và muốn lựa chọn frontier-class không bị hạn chế vùng địa lý
- Tool chain hiện tại là Claude Code, Cline, hoặc Roo Code
Bỏ qua nếu:
- Task cần xử lý ảnh, PDF, hoặc UI screenshot - GLM-5.2 text-only hoàn toàn
- Bạn cần tốc độ phản hồi thực time - mô hình verbose (~43.000 output token/task)
- Task là marathon software engineering kéo nhiều giờ - Opus 4.8 vẫn mạnh hơn đáng kể ở đây
Kết
GLM-5.2 là mốc quan trọng nhất của open-source LLM trong nửa đầu 2026. Không phải vì nó vượt Claude Opus 4.8 trên mọi benchmark - mà vì lần đầu tiên có một mô hình open-weights đạt đủ gần để khiến câu hỏi dùng closed hay open trở nên thực sự thú vị từ góc độ kinh tế. Ở các tác vụ coding thông thường, tiết kiệm 5-6x chi phí mà không hy sinh nhiều về chất lượng là con số khó bỏ qua.
Câu hỏi thực sự không phải GLM-5.2 có tốt không - mà là bạn chạy nó ở đâu: API của Z.ai hay tự host. Đó là quyết định mỗi team phải đưa ra dựa trên risk tolerance và infrastructure của riêng mình.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ