
- Firecrawl Agent endpoint cho phép truyền URL + câu hỏi tự nhiên và nhận về grounded answer ngay lập tức - không cần scrape, chunk, embed hay vector DB.
- Agent chạy với 2 model: spark-1-mini (giảm 60% chi phí) và spark-1-pro cho nghiên cứu phức tạp.
- Pricing: Free 1,000 credits/tháng; Standard $83/tháng với 100,000 credits và 500 req/min.
- Đang ở Preview stage với 5 lượt chạy miễn phí mỗi ngày.
TL;DR
Firecrawl vừa ra mắt tính năng Agent endpoint cho phép bạn bỏ qua hoàn toàn pipeline RAG truyền thống. Thay vì scrape → chunk → embed → retrieve, bạn chỉ cần truyền URL + câu hỏi bằng ngôn ngữ tự nhiên - agent tự lo phần còn lại và trả về câu trả lời có nguồn gốc rõ ràng.
Vấn Đề với Pipeline RAG Truyền Thống
Khi xây dựng AI agent cần đọc thông tin từ web, developer thường phải đi qua chuỗi bước phức tạp:
- Scrape trang web về
- Chunk nội dung thành các đoạn ~1,000 ký tự
- Embed từng chunk bằng embedding model
- Lưu vào vector database
- Retrieve chunk phù hợp khi có câu hỏi
- Generate câu trả lời từ context đã retrieve
Cả pipeline này đòi hỏi infrastructure riêng, latency cao, và phức tạp để maintain. Với câu hỏi đơn giản như "Rate limit là bao nhiêu?" từ một trang docs, độ phức tạp này là không cần thiết.
Firecrawl Agent Hoạt Động Thế Nào
Firecrawl Agent endpoint hoạt động theo mô hình ReAct (Reasoning + Acting): khi bạn đặt câu hỏi, agent tự lý luận cần làm gì, tìm kiếm và điều hướng web, quan sát kết quả, rồi lặp lại cho đến khi có đủ thông tin để trả lời.
Thay vì bạn phải xây dựng cả pipeline, chỉ cần 1 API call:
POST /agent
{
"prompt": "What's the rate limit for the /scrape endpoint?",
"urls": ["https://docs.firecrawl.dev/rate-limits"]
}Và nhận về grounded answer kèm source attribution - không hallucination, không cần vector DB.
Use Cases Thực Tế
Ba use case điển hình mà Firecrawl đề xuất:
- 🔍 "What's the rate limit?" - từ trang API docs của bất kỳ service nào
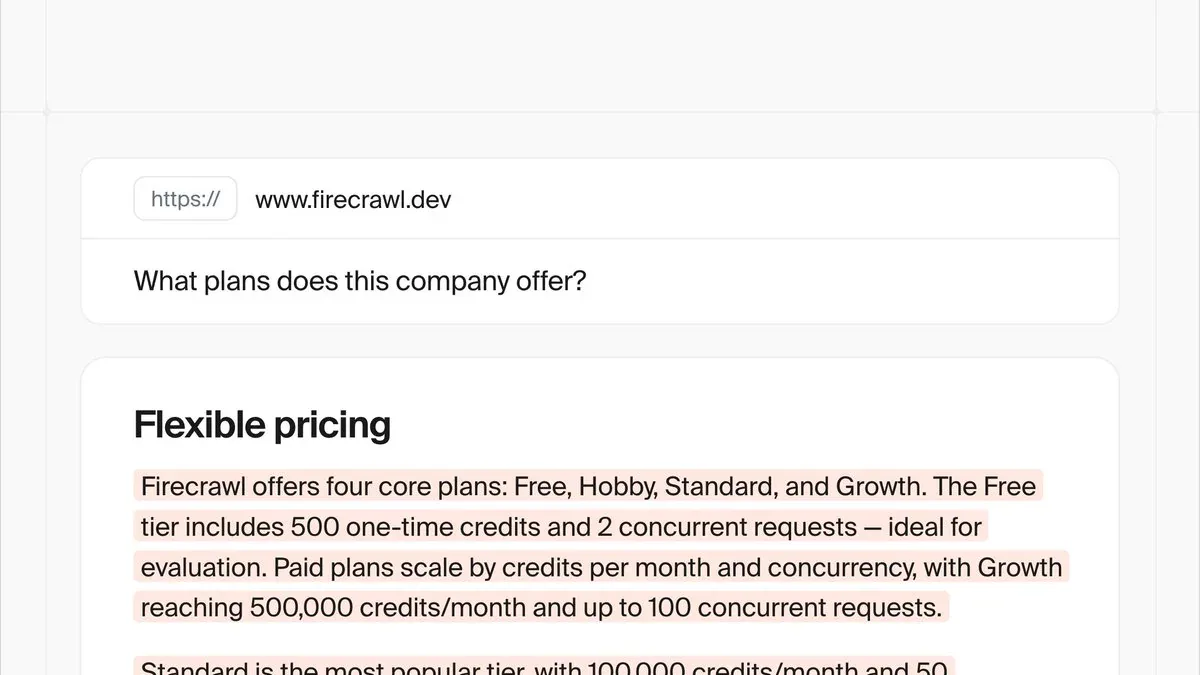
- 💰 "What plans does this company offer?" - từ trang pricing
- 📋 "What's the support SLA?" - từ trang vendor hoặc terms of service
Những câu hỏi này xuất hiện liên tục trong quá trình AI agent làm competitive research, vendor evaluation, hay tự động hóa sales intelligence. Trước đây mỗi câu hỏi tốn hàng chục bước; giờ chỉ còn 1 call.
Hai Model cho Hai Loại Nhiệm Vụ
Agent endpoint cung cấp 2 model để cân bằng chi phí và chất lượng:
| Model | Dùng cho | Chi phí |
|---|---|---|
spark-1-mini (default) | Câu hỏi đơn giản, single-page lookup | Giảm 60% so với pro |
spark-1-pro | Multi-site research, so sánh phức tạp, accuracy-critical | Standard pricing |
Ngoài ra, agent hỗ trợ Pydantic schema để nhận output có cấu trúc dạng JSON - tiện cho pipeline downstream mà không cần thêm parsing step.
Pricing & Rate Limits
Agent endpoint đang ở Preview stage với 5 lượt chạy miễn phí mỗi ngày, dynamic pricing sau đó. Rate limits theo plan:
| Plan | Giá | Credits/tháng | Agent req/min | Concurrent |
|---|---|---|---|---|
| Free | $0 | 1,000 | 10 | 2 |
| Hobby | $16/tháng | 5,000 | 100 | 5 |
| Standard | $83/tháng | 100,000 | 500 | 50 |
| Growth | $333/tháng | 500,000 | 1,000 | 100 |
| Enterprise | Custom | Custom | Custom | Custom + SLA |
Lưu ý: Hobby và Standard không có SLA guarantee. Chỉ Enterprise mới có dedicated SLA - quan trọng nếu bạn chạy production workload.
Ai Nên Dùng Ngay
Firecrawl Agent phù hợp nhất với:
- AI agent builders cần đọc thông tin web động mà không muốn maintain vector pipeline
- Sales/competitive intelligence tools cần extract pricing, features, SLA từ competitor sites
- Developer tools cần auto-answer câu hỏi về docs của third-party services
- Prototype nhanh - 5 free daily runs đủ để test ý tưởng
Chưa phù hợp với team cần SLA guarantee (dưới Enterprise tier) hoặc workload volume cao với predictable pricing (agent vẫn là Preview, dynamic pricing chưa stable).
Tiếp Theo
Firecrawl đang định vị lại mình từ "web scraper" thành "web data infrastructure for AI" - với MCP server integration, CLI agent skill, và Agent endpoint là những bước đầu tiên. Agent endpoint preview cho thấy hướng đi rõ ràng: AI agents cần web data theo cách on-demand, câu hỏi-trả lời, không phải batch-index-query.
Nguồn: @firecrawl on X, Firecrawl Rate Limits, Firecrawl Pricing.