
- Liquid AI phát hành tutorial fine-tune LFM2.5-VL-450M trên ảnh vệ tinh, đạt 81.28 trên RefCOCO-M grounding benchmark.
- Chỉ cần $30 Modal credits, không cần GPU cá nhân, training trên H100.
- Model chạy được trực tiếp trên vệ tinh (edge hardware), xử lý ảnh 512x512 trong 242ms trên Jetson Orin.
TL;DR
Bạn có thể fine-tune một Vision-Language Model (VLM) 450 triệu tham số để hiểu ảnh vệ tinh - với 3 khả năng: trả lời câu hỏi, phát hiện vật thể, và tự động caption. Công cụ: leap-finetune của Liquid AI + Modal (serverless GPU cloud). Chi phí: $30 credits miễn phí từ Modal account mới là đủ.
Tại sao cần model nhỏ chạy trực tiếp trên vệ tinh?
Frontier model như GPT-5 hay Gemini hoàn toàn có thể hiểu ảnh vệ tinh - nhưng chúng phải chạy trên server dưới mặt đất. Để sử dụng, vệ tinh phải downlink ảnh thô xuống Trái Đất, đợi phản hồi, rồi mới hành động.
Đây là bài toán băng thông nghiêm trọng: ảnh vệ tinh có kích thước lớn (ma trận pixel đa chiều, đa kênh), nhân với hàng trăm lần chụp mỗi quỹ đạo. Truyền tất cả dữ liệu đó xuống đất = tắc nghẽn thực sự.
LFM2.5-VL-450M giải quyết vấn đề này: 450M tham số đủ nhỏ để chạy ngay trên phần cứng edge của vệ tinh. Inference xảy ra trong quỹ đạo - không cần downlink từng frame. Trên Jetson Orin, model xử lý ảnh 512x512 trong 242ms, đủ nhanh để cover mọi frame của video 4 FPS.
Tại sao phải fine-tune thay vì dùng thẳng?
LFM2.5-VL-450M là model đa năng, pre-trained trên 28 nghìn tỷ tokens. Nhưng ảnh vệ tinh là một distribution hoàn toàn khác: góc nhìn từ trên xuống (overhead), tỉ lệ vật thể xa lạ, vocabulary chuyên ngành.
Với 450M tham số, không thể kỳ vọng model cover tốt hàng nghìn domain cùng lúc. Fine-tuning giúp tập trung toàn bộ capacity vào đúng domain cần thiết - đây là cách để "vắt" tối đa tín hiệu từ một model nhỏ.
Một điểm kỹ thuật quan trọng: tutorial không dùng LoRA. LoRA chỉ áp dụng cho language backbone, bỏ qua vision encoder. Khi ảnh satellite khác xa pre-training data, cần fine-tune cả vision encoder lẫn language backbone mới đủ để model học domain mới.
Bộ công cụ & dataset
Tutorial dùng 3 thành phần chính:
- LFM2.5-VL-450M - model nền, có sẵn miễn phí trên Hugging Face và LEAP platform
- leap-finetune - thư viện open-source của Liquid AI, chỉ cần viết YAML config là chạy được
- Modal - serverless GPU cloud, pay-per-second. Account mới được $30 credits miễn phí - đủ để chạy toàn bộ ví dụ này
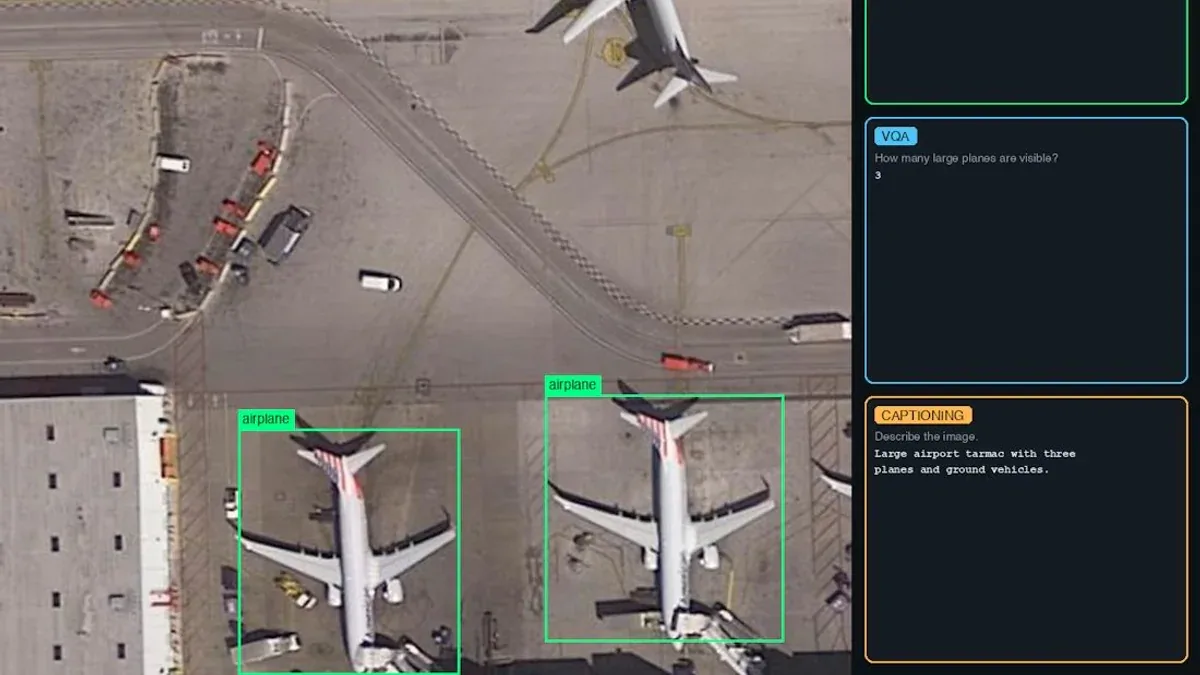
Dataset: VRSBench (NeurIPS 2024) - bộ dữ liệu remote sensing vision-language với 3 task:
| Task | Số mẫu | Ví dụ |
|---|---|---|
| Visual Question Answering | 123K cặp QA | "How many aircraft are at the terminal?" |
| Visual Grounding | 52K references | "Detect the large white ship" + bounding box |
| Captioning | 29K mô tả | "An aerial view of an airport terminal with multiple parked aircraft" |
Các bước thực hiện
Toàn bộ compute nặng chạy trên cloud, local chỉ cần submit job và stream log:
- Chuẩn bị data: Script
prepare_vrsbench.pydownload ~12 GB từ HuggingFace, convert sang JSONL format màleap-finetuneyêu cầu. Bounding box được normalize về tọa độ [x1, y1, x2, y2] trong khoảng 0-1. Chạy trên Modal CPU container, không cần GPU. - Fine-tuning: Viết YAML config (không cần code), submit job lên Modal H100. Checkpoint tự lưu vào Modal volume. Có thể monitor trên Weights & Biases hoặc Trackio.
- Lấy checkpoint: Pull về local bằng
modal volume get.
# Quickstart
uv run prepare_vrsbench.py --modal # download + convert data
leap-finetune submit satellite.yaml # kick off training on H100Benchmark & so sanh
LFM2.5-VL-450M cải thiện lớn so với phiên bản trước và vượt SmolVLM2-500M (HuggingFace) dù ít tham số hơn:
| Benchmark | LFM2.5-VL-450M | LFM2-VL-450M | SmolVLM2-500M |
|---|---|---|---|
| RefCOCO-M (grounding) | 81.28 | 0 | - |
| MMBench (vision) | 60.91 | 56.27 | 52.32 |
| RealWorldQA | 58.43 | 52.03 | 49.90 |
| MM-IFEval (instruction) | 45.00 | 32.93 | 11.27 |
| CountBench | 73.31 | 47.64 | 61.81 |
Về edge latency trên Jetson Orin: 233ms (256x256) / 242ms (512x512) - đủ để xử lý stream 4 FPS full vision-language.
Ứng dụng thực tế
Fine-tune VLM nhỏ cho satellite mở ra nhiều ứng dụng high-impact:
- Xử lý trong quỹ đạo: Vệ tinh tự phân tích ảnh, chỉ gửi structured data xuống đất - tiết kiệm hàng chục lần băng thông
- Quản lý thảm họa: Phát hiện cháy rừng, lũ lụt, thiệt hại công trình theo thời gian thực
- Giám sát môi trường: Theo dõi phá rừng, biến đổi sử dụng đất, ước tính sinh khối
- Quy hoạch đô thị: Phát hiện mở rộng đô thị, xây dựng mới, thay đổi cơ sở hạ tầng
- Nông nghiệp chính xác: Giám sát mùa vụ, ước tính sản lượng
Cùng model này cũng phù hợp cho edge deployment phi vũ trụ: kho logistics (theo dõi forklift, worker, hàng hóa), camera an ninh, thiết bị đeo - mọi use case cần privacy-preserving, on-device visual reasoning.
Tiếp theo
Tutorial này là starting point chính thức của AI in Space Hackathon - cuộc thi online toàn cầu 4 tuần do DPhi Space x Liquid AI tổ chức, mở cửa cho builders khắp thế giới. Task: xây dựng real-world app từ ảnh vệ tinh + VLM.
Model LFM2.5-VL-450M hiện có sẵn trên Hugging Face, LEAP platform, và Liquid Playground. Full tutorial tại docs.liquid.ai.
Nguon: Liquid AI Docs, Liquid AI Blog, Pau Labarta Bajo.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ