
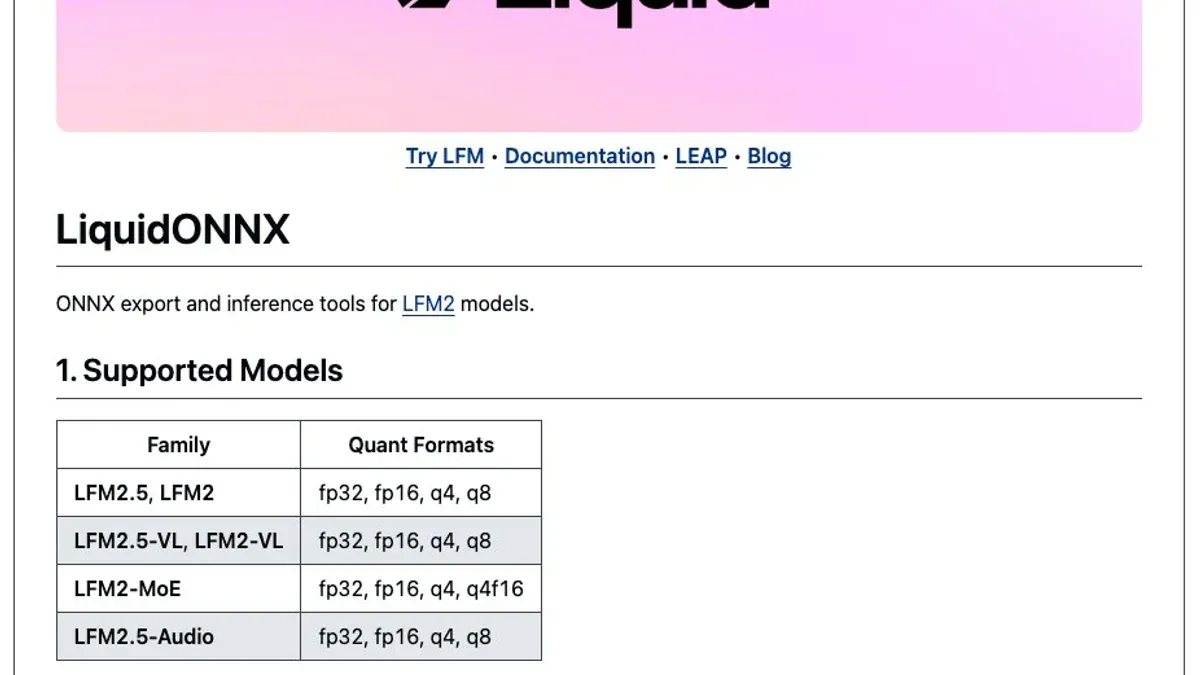
- LiquidONNX cho phép export LFM2/LFM2.5 sang ONNX và chạy 100% client-side trong browser qua WebGPU - không server, không API key.
- Transformers.js v3 với WebGPU nhanh hơn WASM tới 100x; benchmark Segment Anything encoder đạt 19x speedup trên RTX 3060.
- Model 8.3B param (LFM2-MoE) chạy được trong một browser tab thông thường với q4 ~900MB.
- Hỗ trợ text, vision-language, audio (ASR+TTS), và MoE - tất cả chạy trực tiếp trên GPU của user.
TL;DR
Bạn có thể export Small Language Models sang ONNX và chạy chúng trực tiếp trong trình duyệt bằng WebGPU - không cần server, không cần API key, không tốn tiền mỗi request. Liquid AI vừa open-source LiquidONNX, bộ tool chính thức để export LFM2/LFM2.5 sang ONNX và chạy inference trên web, edge, và thiết bị đầu cuối. Hỗ trợ đầy đủ text, vision-language, audio, và Mixture-of-Experts.
Vấn đề với cloud API
Phần lớn AI engineer hiện tại đang build theo pattern quen thuộc: gửi request lên API - nhận kết quả về - render cho user. Pattern này hoạt động tốt... cho đến khi gặp những ràng buộc thực tế:
- Data nhạy cảm không thể rời thiết bị: y tế, pháp lý, tài chính - nhiều use case không thể gửi dữ liệu lên server bên thứ ba
- Chi phí scale theo user: mỗi inference là một lần billing, margin ăn dần khi lượng request tăng
- Latency không kiểm soát được: network round-trip + queue time của provider = trải nghiệm khó đoán
- Rate limit chặn throughput: burst traffic gặp 429, phải xử lý retry logic phức tạp
- Offline là không thể: mất internet đồng nghĩa mất tính năng
Câu trả lời không phải là build thêm server - mà là chuyển inference hoàn toàn sang GPU của chính user, ngay trong tab trình duyệt.
Cơ chế hoạt động
Stack hoàn chỉnh gồm 3 lớp phối hợp với nhau:
- LiquidONNX - export LFM2/LFM2.5 (text, VL, audio, MoE) sang định dạng ONNX với nhiều mức quantization: fp32, fp16, q4, q8. Tool tự kiểm tra ONNX export so với PyTorch reference để đảm bảo accuracy
- ONNX Runtime Web v1.17+ - JavaScript runtime với WebGPU Execution Provider (EP). Dùng compute shaders để tận dụng GPU song song; hỗ trợ IO Binding (giữ tensor trên GPU xuyên suốt inference chain, tránh copy CPU-GPU tốn kém)
- Transformers.js v3 - abstraction layer phổ biến nhất, WebGPU acceleration mặc định, fallback tự động về WASM nếu browser không hỗ trợ
Khi user mở app lần đầu, model ONNX download về và cache vào IndexedDB hoặc Cache API. Các lần sau load tức thì. Inference chạy trong Web Worker tách biệt khỏi main UI thread - UI không bị đơ dù model đang xử lý.
Những gì bạn có thể làm
Tất cả chạy 100% client-side, không cần backend:
| Modality | Model ví dụ | Kích thước (q4) |
|---|---|---|
| Text generation | LFM2-1.2B-ONNX | ~600MB |
| Vision-Language | LFM2.5-VL-1.6B-ONNX | ~900MB |
| Audio (ASR + TTS) | LFM2.5-Audio-1.5B-ONNX | ~900MB |
| MoE (8.3B tổng, 1.5B active) | LFM2-8B-A1B-ONNX | ~2GB |
Ngoài ra có các variant fine-tuned cho task cụ thể: RAG, Math, Tool-calling, dịch EN-JP. Toàn bộ đã được pre-export sẵn trên HuggingFace từ LiquidAI và onnx-community - không cần tự export nếu chỉ muốn dùng.
Browser vs Cloud API: So sánh thẳng
| Tiêu chí | WebGPU Browser | Cloud API |
|---|---|---|
| Data privacy | 100% on-device | Gửi lên server ngoài |
| Latency | Không có network round-trip | Overhead mỗi request |
| Chi phí inference | $0 sau khi download | Per-request billing |
| Offline | Hoạt động sau khi cache | Cần internet ổn định |
| Rate limit | Chỉ giới hạn bởi GPU user | API quota, 429 errors |
Số liệu benchmark thực tế: WebGPU nhanh hơn WASM tới 100x (Transformers.js v3). Đo trực tiếp trên Segment Anything với RTX 3060 + Core i9: encoder nhanh 19x, decoder nhanh 3.8x. Stable Diffusion Turbo generate ảnh dưới 1 giây trên RTX 4090 - hoàn toàn trong trình duyệt.
Bắt đầu thế nào
Cách nhanh nhất dùng Transformers.js (WebGPU tích hợp sẵn):
npm install @huggingface/transformersimport { pipeline } from '@huggingface/transformers';
const generator = await pipeline(
'text-generation',
'onnx-community/LFM2-1.2B-ONNX',
{ device: 'webgpu' }
);
const result = await generator('Giải thích WebGPU cho tôi.');Nếu muốn dùng ONNX Runtime Web trực tiếp, chỉ cần đổi import:
// Thay vì: import * as ort from 'onnxruntime-web';
import * as ort from 'onnxruntime-web/webgpu';
const session = await ort.InferenceSession.create(modelPath, {
executionProviders: ['webgpu', 'wasm'] // fallback tự động
});Để tự export model bằng LiquidONNX:
pip install liquidonnx
python -m liquidonnx export --model LiquidAI/LFM2-1.2B --quantization q4Deploy app trên Vercel hoặc Netlify (không phải GitHub Pages). Cần set 2 CORS headers để bật SharedArrayBuffer: Cross-Origin-Embedder-Policy: require-corp và Cross-Origin-Opener-Policy: same-origin.
Giới hạn cần biết
- Browser support hẹp hơn: Chrome 113+ hoặc Edge 113+ (FP16 yêu cầu v121+). Firefox và Safari còn experimental
- Q8 không chạy trong browser: chỉ hỗ trợ Q4 và FP16; Q8 chỉ dùng được trên server CPU/GPU
- Download lần đầu lớn: model Q4 từ 600MB tới 2GB tùy size - user cần kết nối tốt lần đầu
- Phần cứng tối thiểu: cần GPU tươm tất để có tốc độ hợp lý; máy yếu fallback về WASM, chậm hơn nhiều
- GitHub Pages không tương thích: cần platform hỗ trợ custom CORS headers (Vercel, Netlify, HuggingFace Spaces)
Thử ngay - không cần cài gì
Liquid AI đã deploy live demos trên HuggingFace Spaces, mở Chrome lên là chạy được:
- LFM2 WebGPU Chat - text generation trong browser
- LFM2-MoE 8.3B WebGPU - model 8.3B param chạy ngay trong browser tab
- LFM2.5 Vision - vision-language model trong browser
- LFM2.5 Audio - speech-to-text và text-to-speech trong browser
Nguồn: github.com/Liquid4All/onnx-export, Liquid Docs, Microsoft Open Source Blog.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ