
- AI Engineering Loop là vòng lặp liên tục kết nối production monitoring với development có hệ thống - dataset là mắt xích trung tâm.
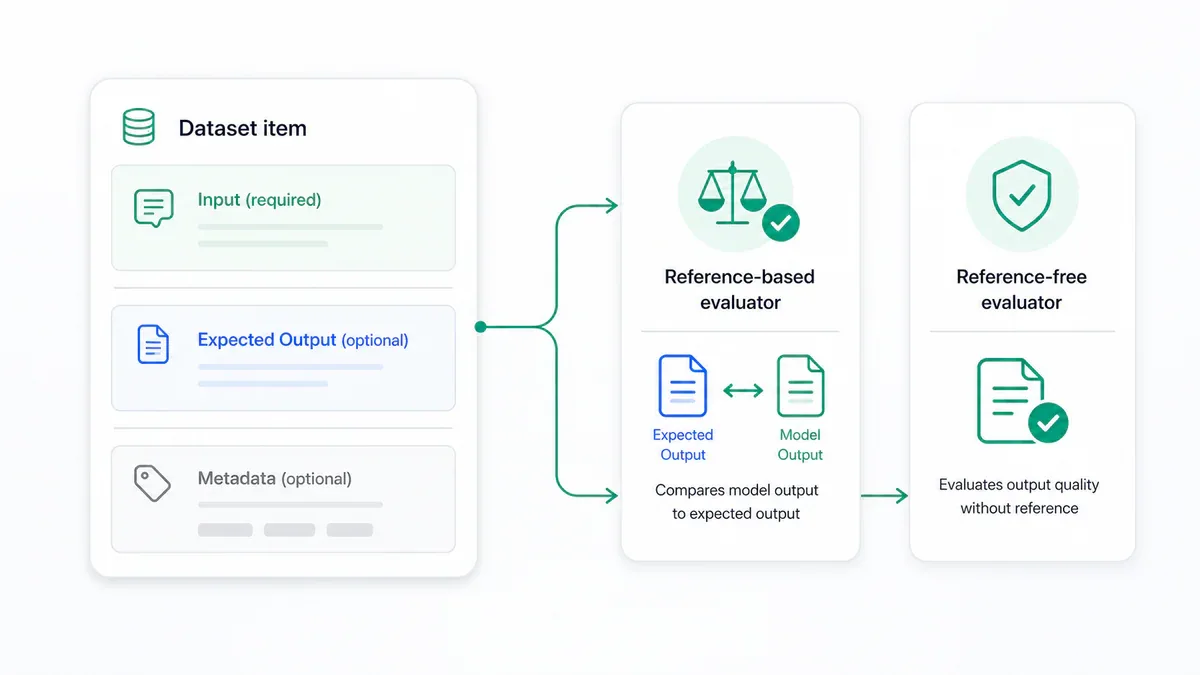
- Mỗi dataset item gồm 3 trường: Input bắt buộc, Expected output tùy chọn, và Metadata tùy chọn.
- Reference-based evaluators yêu cầu ground truth và chỉ dùng được ở offline; reference-free evaluators chạy được cả online lẫn offline.
- Hiểu đúng cấu trúc này là nền tảng để xây hệ thống eval không đoán mò.
TL;DR
Nếu bạn đang build ứng dụng LLM và vẫn đang deploy rồi cầu nguyện, bài này dành cho bạn. AI Engineering Loop là framework giúp team cải thiện hệ thống AI liên tục - và dataset là công cụ cốt lõi để test thay đổi trước khi đưa vào production. Phần 1 này tập trung vào lý thuyết nền: loop trông như thế nào, dataset item cấu trúc ra sao, và sự khác biệt quan trọng giữa reference-based và reference-free evaluators.
AI Engineering Loop là gì?
AI Engineering Loop là quy trình liên tục để team cải thiện hệ thống AI. Nó kết nối hai phần:
- Production side: tracing và monitoring - theo dõi ứng dụng đang làm gì trong thực tế
- Development side: datasets, experiments, evaluation - lặp lại có hệ thống để cải thiện
Mỗi lần ship một cải tiến, hệ thống tạo ra dữ liệu mới. Team dùng dữ liệu đó để phát hiện vấn đề tiếp theo, rồi lại cải thiện. Vòng lặp không bao giờ dừng.
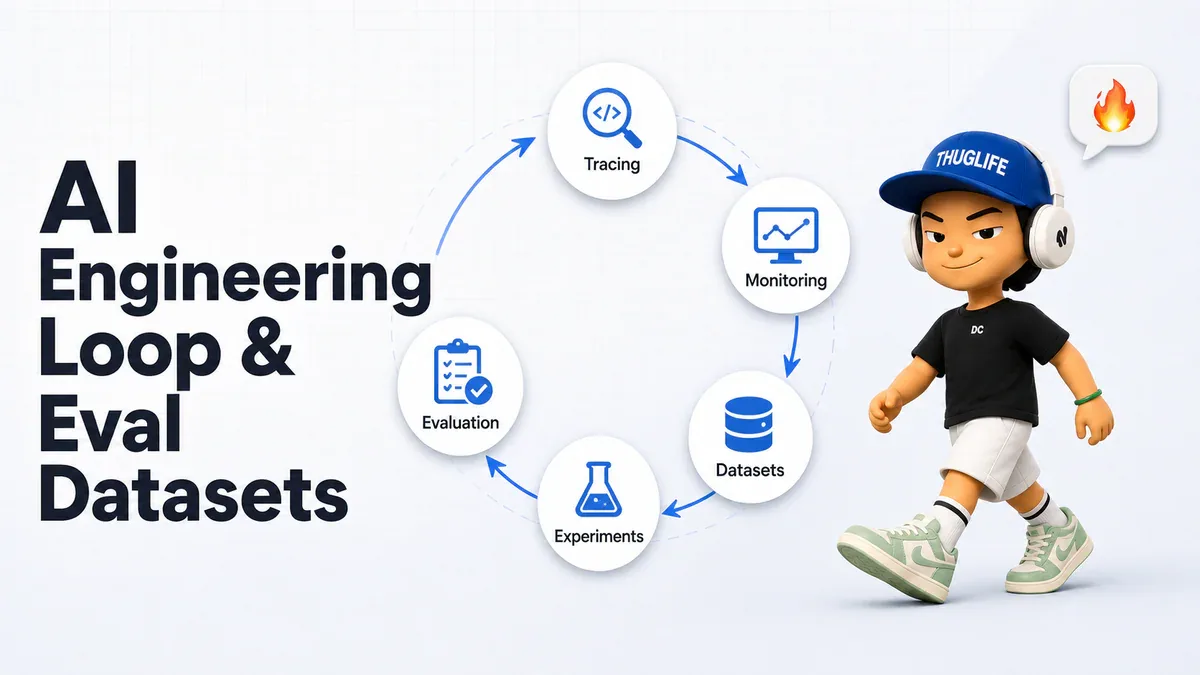
Trong series Langfuse Academy của Lotte Verheyden, hai bước đầu của loop (tracing và monitoring) cho bạn khả năng quan sát - bạn thấy hệ thống đang làm gì. Nhưng khi bạn phát hiện điều gì đó cần cải thiện, câu hỏi tiếp theo là: làm sao test thay đổi trước khi deploy? Đây là lúc dataset đóng vai trò trung tâm.
Dataset là gì và tại sao cần?
Một dataset đơn giản là tập hợp test case mà bạn chạy ứng dụng qua mỗi khi có thay đổi - gọi là "experiment". Thay vì deploy và hy vọng mọi thứ ổn, bạn có một kiểm tra lặp đi lặp lại trên tập input đại diện cho usage thực tế.
Lấy ví dụ cụ thể: bạn tweak prompt để xử lý một edge case. Với dataset, bạn chạy lại ngay và thấy ngay thay đổi đó ảnh hưởng thế nào đến toàn bộ hành vi của hệ thống - không chỉ edge case đó mà cả những case khác. Đây là sự khác biệt giữa eval có hệ thống và đoán mò.
Cấu trúc một Dataset Item
Dataset được tạo thành từ các item, mỗi item đại diện cho một test case. Về cơ bản, một item có 3 trường:
- Input (bắt buộc): query, message, hoặc context mà ứng dụng sẽ nhận
- Expected output (tùy chọn): kết quả mong đợi - có thể có hoặc không tùy vào loại evaluator
- Metadata (tùy chọn): thông tin bổ sung như category, source, difficulty level
Điều quan trọng cần nhớ: Expected output là JSON field. Điều này có nghĩa bạn có thể lưu nhiều loại reference data khác nhau trong cùng một item - rất tiện khi cần chạy combination evaluators.
Reference-based vs Reference-free Evaluators
Đây là phần nhiều người nhầm lẫn nhất. Việc bạn có cần expected_output hay không phụ thuộc hoàn toàn vào loại evaluator bạn dùng.
Reference-based evaluators so sánh output của model với một ground truth đã định sẵn. Có 3 dạng expected output phổ biến:
- Exact match: câu trả lời đúng là một giá trị cụ thể. Ví dụ: classification task với label
"billing_inquiry", hoặc extraction task với entities["Paris", "Thursday"]. - Reference answer: một gold-standard response. Evaluator so sánh semantic similarity hoặc kiểm tra key points có khớp không.
- Evaluation criteria: danh sách checklist. Ví dụ: "phải đề cập refund policy", "phải có link đến help center". Evaluator kiểm tra từng tiêu chí.
Reference-based evaluators chỉ dùng được cho offline evaluation (pre-deployment testing) vì chúng cần curated dataset với expected answers.
Reference-free evaluators đánh giá chất lượng output mà không cần ground truth. Chúng phù hợp để check:
- Tone: có professional không?
- Safety: có safe không?
- Format: có đúng JSON structure không?
- Coherence: có nhất quán không?
Ưu điểm lớn của reference-free evaluators là chúng hoạt động được cho cả offline lẫn online (production monitoring theo thời gian thực) - vì không cần expected answer.
Và bạn hoàn toàn có thể kết hợp cả hai: chạy reference-based check cho accuracy và reference-free check cho tone trên cùng một dataset item.
Tổng kết Phần 1
AI Engineering Loop không phải magic - đó là quy trình: quan sát production, phát hiện vấn đề, test có hệ thống, cải thiện, lặp lại. Dataset là công cụ biến "test có hệ thống" từ ý tưởng thành thực tế.
Hiểu cấu trúc dataset item (Input / Expected output / Metadata) và biết khi nào dùng reference-based vs reference-free evaluator là nền tảng không thể thiếu.