
- Eval dataset là tập test case giúp kiểm tra hệ thống LLM có hệ thống trước khi deploy, thay thế chiến lược deploy-and-hope-for-the-best.
- Mỗi dataset item gồm 3 trường: Input (bắt buộc), Expected output và Metadata (tùy chọn).
- Langfuse giảm CLI error rate từ 25% xuống 0% chỉ bằng cách thêm một instruction rõ ràng - phát hiện nhờ dataset và experiments.
- 57% tổ chức đã có AI agents trong production (LangChain 2026), và quality là rào cản số 1 với 32% đội nhóm.
TL;DR
Trong vòng lặp AI Engineering, dataset là cầu nối giữa quan sát production (tracing, monitoring) và phát triển có cấu trúc (experiments, evaluation). Thay vì deploy thay đổi và chờ xem có gì vỡ, bạn chạy hệ thống qua một bộ test case nhất quán trước. Bài này giải thích cách thiết kế bộ dataset đó - từ cấu trúc item, chọn loại evaluator, đến nguồn dữ liệu và cạm bẫy thực tế.
Vấn đề cần giải quyết
LLM application không giống software truyền thống - output là text open-ended, không phải classification đơn giản. Không thể đo error rate theo kiểu cũ. Mỗi thay đổi prompt, swap model, hay tweak logic đều có thể ảnh hưởng chất lượng theo cách khó đoán.
57% tổ chức đã có AI agents trong production tính đến 2026 (theo LangChain State of AI Agents), và 32% coi quality là rào cản số 1 khi mở rộng. Nhiều team vẫn dùng chiến lược deploy-and-hope - đưa lên production rồi reactive khi có complaint. Eval dataset là giải pháp chủ động hơn.
Giải phẫu một dataset item
Một dataset là tập hợp các test case - mỗi test case đại diện cho một tình huống hệ thống phải xử lý được. Mỗi item có 3 trường:
- Input (bắt buộc): câu hỏi, prompt, hoặc context người dùng đưa vào
- Expected output (tùy chọn): đáp án đúng hoặc tiêu chí đánh giá
- Metadata (tùy chọn): tag, nhóm, version, hay bất kỳ context bổ sung nào
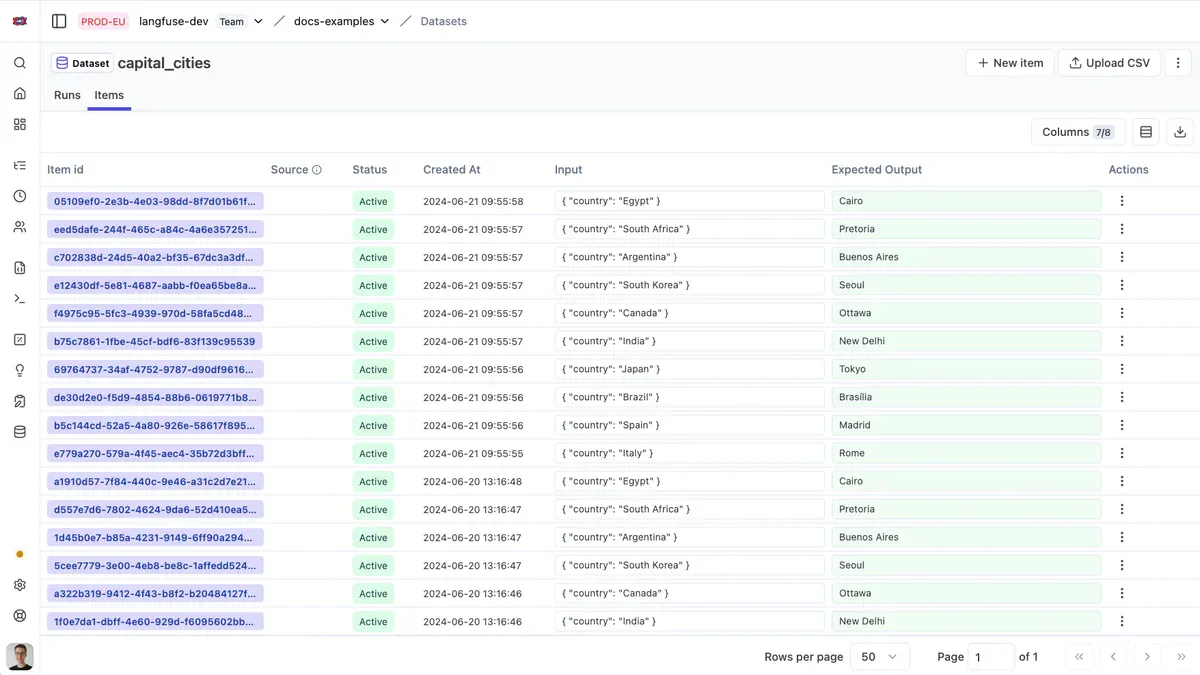
Một dataset tốt phải phản ánh đúng những gì hệ thống sẽ gặp trong thực tế. Nếu pass dataset này cho bạn cảm giác tự tin trước khi deploy, nó đang làm đúng việc.
Reference-based vs. Reference-free: chọn cái nào?
Câu trả lời phụ thuộc vào loại evaluator bạn dùng:
Reference-based - so output với ground truth đã định sẵn:
- Exact match: output phải khớp chính xác (ví dụ: classification task với label
"billing_inquiry", hoặc extraction task với entities["Paris", "Thursday"]) - Reference answer: so sánh semantic similarity hoặc key points với một gold-standard response
- Evaluation criteria: danh sách điều kiện cần thỏa mãn, ví dụ "phải đề cập refund policy", "phải có link help center"
Reference-free - đánh giá output mà không cần ground truth:
- Tone có professional không?
- Response có safe không?
- Output có đúng format yêu cầu không?
Nhiều dataset item có thể kết hợp cả hai - chạy nhiều evaluator khác nhau trên cùng một item, vì expectedOutput là JSON field có thể chứa nhiều kiểu reference data.
Bắt đầu từ đâu?
Nguyên tắc: bắt đầu từ ví dụ cụ thể nhất bạn đang có, mở rộng dần sau khi đã rõ cần test gì.
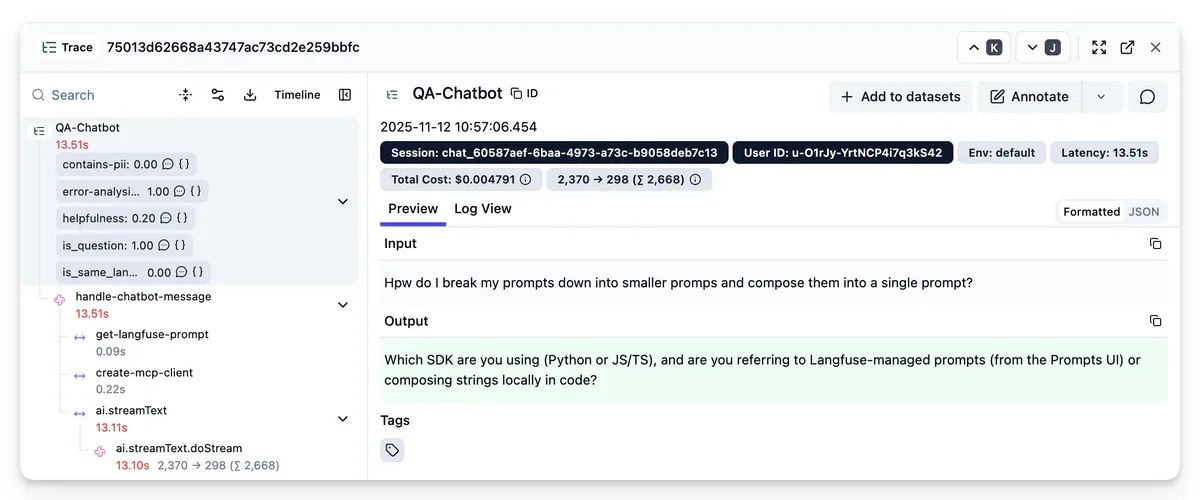
1. Kéo từ production traces - nguồn thực tế nhất. Lọc các trace mà hệ thống không xử lý tốt, thêm expected output, dùng làm test case cho lần sau. Langfuse chatbot ví dụ đã tích lũy 19,000 user queries trong một năm - kho dữ liệu lý tưởng để bootstrap.
2. Viết tay edge case - dựa trên requirements định sẵn, behavior agent phải xử lý đúng (prompt injection, content policy violation, câu hỏi bẫy logic), hoặc scenario bạn biết hệ thống dễ fail.
3. Generate synthetic bằng AI - khi muốn scale nhanh. Dùng LLM generate query variations (bao gồm adversarial), các thư viện như RAGAS (cho RAG grounded trên documents cụ thể), DeepEval (Synthesizer class), hoặc Torque (declarative typesafe DSL cho multi-turn conversations phức tạp).
Dataset cũng cần đúng kích thước cho workflow: dataset nhỏ đủ nhanh để chạy trên mỗi push CI/CD; dataset lớn hơn dùng cho review định kỳ khi không cần chạy mỗi minor change.
Pitfalls thực tế
Bài học từ Langfuse khi dùng eval dataset để test AI agent dùng CLI:
- Lần đầu chạy: lỗi CLI trên 90% test case. Trace review cho thấy agent hallucinate CLI resource, đôi khi bỏ qua skill hoàn toàn.
- Fix: thêm instruction rõ ràng để agent luôn dùng
--helptrước khi gọi command. Kết quả: error rate giảm từ 25% xuống 0%. - Bài học: the devil is in the details. Một từ "optional" thay vì "mandatory" trong comment gây fail nhất quán trên toàn bộ test suite. Manual trace review - dù tốn thời gian - là cách duy nhất để hiểu tại sao metric báo lỗi.
Thách thức lớn nhất với automated evaluator (LLM-as-a-judge): cần validate trên human-labeled test set, đạt TPR > 90% và TNR > 90% thì mới đủ tin cậy. Automated evaluator có thể drift, bias, và fail theo cách bất ngờ - không thể tin hoàn toàn mà không calibrate liên tục với human judgment.
Tiếp theo: Experiments và CI/CD
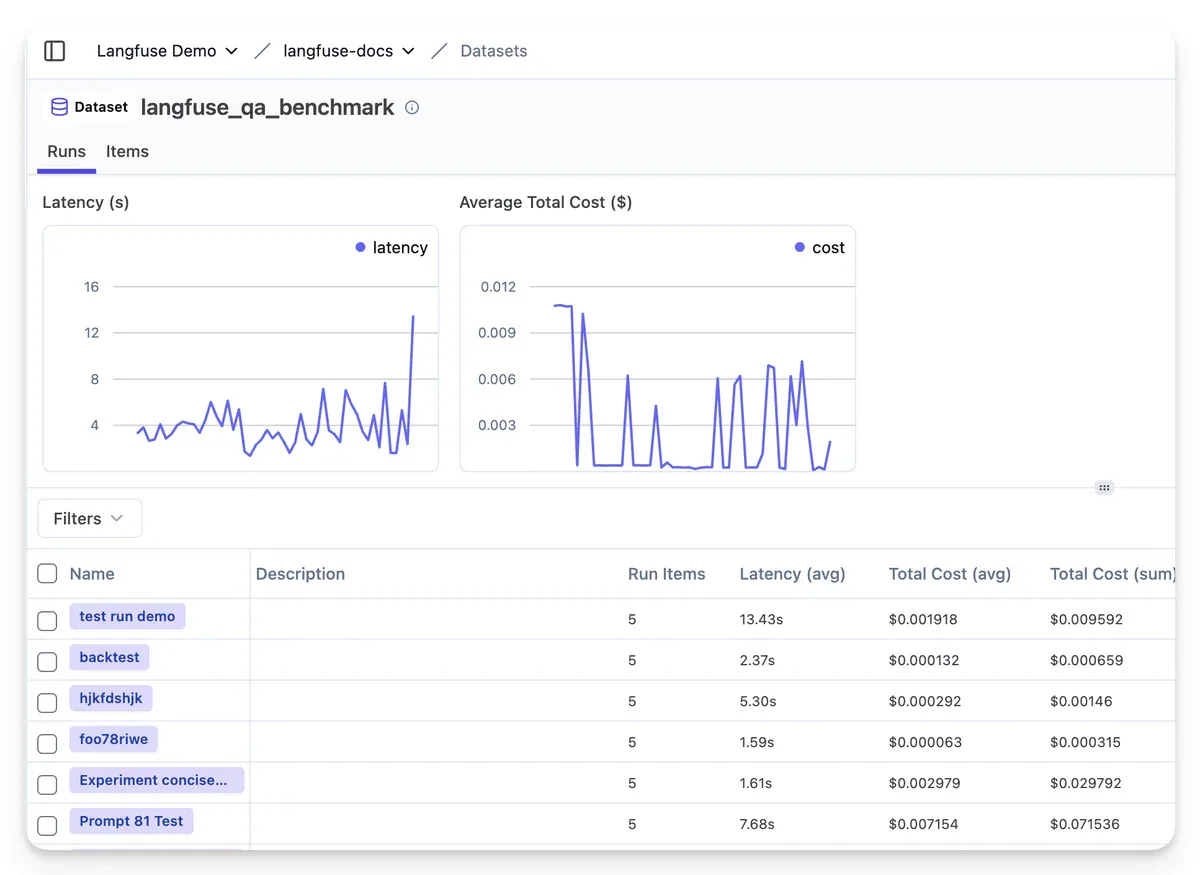
Dataset là điểm khởi đầu. Bước kế tiếp là experiments - chạy hệ thống qua dataset để đo impact của từng thay đổi (prompt, model, logic). Experiments cho phép so sánh nhiều variant, phân tích tại sao variant B tốt hơn 10%, và link ngược về error patterns trong traces.
Mục tiêu cuối là tích hợp vào CI/CD pipeline: mỗi code change tự động trigger eval run trên golden dataset. Automated evaluator score các run, báo ngay nếu thay đổi gây regression. Thay thế hoàn toàn manual annotation trong deployment loop.
Ngành đang chuyển dần sang specialized eval models (như Galileo AI's Luna dùng ChainPoll) - nhỏ hơn, rẻ hơn, đủ để sample 100% production traffic thay vì phải sampling ngẫu nhiên như hiện tại.
Kết
Eval dataset không phải one-time setup - là artifact sống cùng với hệ thống. Bắt đầu nhỏ với production traces thực tế, mở rộng bằng hand-written edge case, scale bằng synthetic data khi đã rõ cần cover gì. Dataset tốt là dataset khiến bạn tự tin deploy - không phải dataset lớn nhất.
Series Langfuse Academy còn nhiều phần về experiments, evaluation methods, và CI/CD integration. via Evaluating LLM Applications: A Comprehensive Roadmap - Langfuse | Eval engineering: The missing piece of agentic AI governance - SiliconANGLE
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ