
- Chunkr là Document Intelligence API mã nguồn mở (Rust), xử lý 4 trang/giây trên RTX 4090, tương đương 11 triệu trang mỗi tháng chỉ với chi phí $249.
- Hỗ trợ 11+ loại segment (bảng, công thức, caption), output JSON/HTML/Markdown chuẩn cho RAG pipeline.
- Có thể self-host hoàn toàn qua Docker Compose - không cần phụ thuộc vendor.
TL;DR
Chunkr là một Document Intelligence API mã nguồn mở do Lumina AI (Y Combinator W24) phát triển. Viết bằng Rust, pipeline xử lý 4 trang/giây trên RTX 4090 - đủ để xử lý hơn 11 triệu trang mỗi tháng với chi phí tự host khoảng $249/tháng. Thay vì trả $0.003/trang như LlamaParse, bạn có thể chạy nguyên server riêng với Docker Compose hoặc Kubernetes và giữ toàn bộ dữ liệu trong VPC của mình.
Từ 600 triệu trang đến Chunkr
Ba nhà sáng lập Mehul Chadda, Ishaan Kapoor và Akhilesh Sharma ban đầu xây dựng Lumina - một AI search engine cho tài liệu khoa học. Bài toán lớn nhất họ gặp phải: phải xử lý gần 600 triệu trang tài liệu học thuật để xây RAG pipeline cho sản phẩm.
Sau khi thử đủ các giải pháp parsing trên thị trường và không cái nào đáp ứng được về hiệu năng, khả năng quan sát lẫn tính linh hoạt, họ quyết định tự xây in-house. Rồi nhận ra cái pipeline tự xây đó - sau khi chiến đấu với hàng loạt vấn đề nền tảng - mới chính là thứ thị trường đang cần. Chunkr ra đời từ quyết định pivot đó.
Khi mở cửa cho lập trình viên bên ngoài thử, phản hồi viral với hơn 400K impressions chỉ trong những tuần đầu. Hiện tại Chunkr đã phục vụ khách hàng trong các lĩnh vực healthcare, finance, nghiên cứu, chính phủ, giáo dục và phần cứng.
Chunkr hoạt động thế nào
Pipeline của Chunkr kết hợp ba lớp xử lý độc lập:
- Layout Analysis: Mô hình YOLO-based với GPU acceleration phân tích bố cục tài liệu, nhận diện 11+ loại segment bao gồm title, paragraph, table, formula, caption, image, list và nhiều hơn nữa.
- OCR: Dùng DocTR để trích xuất văn bản kèm tọa độ bounding box (x, y) cho mỗi đoạn. Hỗ trợ khoảng 100 ngôn ngữ, có hai chế độ: All (OCR toàn bộ) và Auto (kết hợp với native PDF text layer khi có).
- VLM Processing: Với các segment phức tạp mà OCR thuần không xử lý tốt - biểu đồ, công thức toán, bảng đặc biệt - Chunkr route sang Vision-Language Model để diễn giải nội dung.
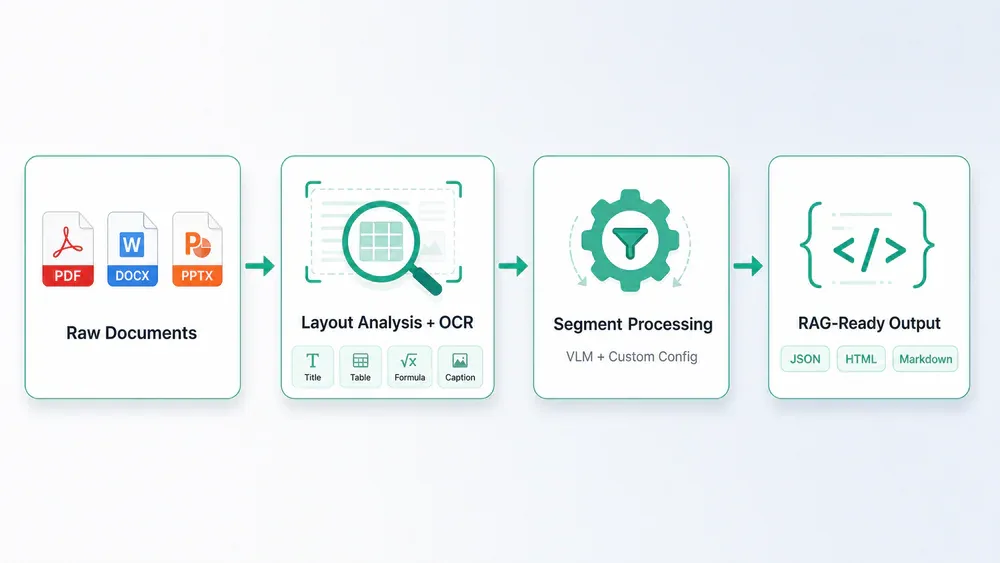
Điểm đặc biệt so với các công cụ khác là Chunkr làm việc ở cấp độ segment. Thay vì áp một cấu hình duy nhất cho toàn bộ tài liệu, bạn có thể cấu hình riêng cho từng loại segment:
- Text thông thường: fast OCR, không cần VLM
- Công thức, bảng phức tạp: dùng VLM với prompt tùy chỉnh
- Biểu đồ: crop high-res + prompt để chuyển thành dạng table
- Trang cụ thể: chỉ xử lý phần bạn cần, bỏ qua phần còn lại
Triết lý thiết kế của Chunkr là cho lập trình viên những "nút điều chỉnh" để cân bằng giữa tốc độ, chất lượng và tính năng - "như một công cụ tự xây, không có cái đau đầu của việc tự xây" theo lời nhóm sáng lập.
Tech stack và tính năng chính
Backend viết hoàn toàn bằng Rust (43.6% codebase) với Actix-Web, frontend TypeScript. Storage layer dùng MinIO cho object, PostgreSQL cho metadata và Redis cho job queue. Các tác vụ nặng như chuyển đổi ảnh, song song hóa theo trang, xác định reading order, xử lý lỗi và batching đều được tích hợp sẵn.
Tóm tắt thông số kỹ thuật:
| Thông số | Giá trị |
|---|---|
| Tốc độ xử lý | ~4 trang/giây (RTX 4090) |
| Công suất tháng | 11+ triệu trang (self-host) |
| Segment types | 11+ loại |
| Ngôn ngữ OCR | ~100 ngôn ngữ |
| Định dạng input | PDF, DOCX, PPTX, PNG, JPEG, TIFF (XLSX chỉ ở Cloud/Enterprise) |
| Định dạng output | JSON, HTML (semantic markup), Markdown |
| Deployment | Docker Compose (GPU/CPU/Mac ARM M1-M3), Kubernetes, Cloud API |
| LLM routing | OpenAI, Gemini, OpenRouter, vLLM, Ollama (bất kỳ OpenAI-compatible endpoint) |
| Compliance | SOC 2, HIPAA |
| License | AGPL-3.0 (open-source); commercial license riêng cho SaaS |
Một ưu điểm thực tế: vì dùng models.yaml để route LLM, bạn không bị lock vào bất kỳ nhà cung cấp AI nào. Khi VLM thế hệ mới ra đời, chỉ cần cập nhật config.
So sánh với LlamaParse, Docling và Unstructured
Chunkr vs LlamaParse: Đây là so sánh được quan tâm nhất. LlamaParse xử lý 90+ định dạng tài liệu với khả năng multimodal cho biểu đồ và bảng nhúng, đồng thời tích hợp sâu vào ecosystem LlamaIndex. Nhưng về kinh tế học: LlamaParse tính $0.003/trang, trong khi Chunkr self-host trên RTX 4090 thuê ở Runpod chỉ tốn khoảng $249/tháng cho 11 triệu trang. Với volume cao và yêu cầu data sovereignty, Chunkr thắng áp đảo về chi phí.
Chunkr vs Docling: Cả hai đều open-source, nhưng Docling dùng MIT license (không hạn chế thương mại) trong khi Chunkr dùng AGPL-3.0. Nếu bạn muốn nhúng Chunkr vào sản phẩm SaaS proprietary, bạn cần mua commercial license. Docling được IBM Research và Linux Foundation hậu thuẫn, Red Hat đã tích hợp vào infrastructure core - mức độ enterprise validation mà Chunkr chưa có. Chunkr bù lại bằng semantic chunking tối ưu hơn cho RAG và cộng đồng YC.
Chunkr vs Unstructured: Unstructured gọi được $65M Series B và có hơn 60 connectors cho các nguồn dữ liệu khác nhau. Nếu bạn cần ETL phức tạp với nhiều nguồn tích hợp và compliance GDPR, Unstructured mạnh hơn nhiều. Chunkr tập trung hẹp hơn: tối ưu cho RAG pipeline với độ trễ thấp và khả năng self-host không vendor lock-in.
Cách bắt đầu với Chunkr
Chunkr có ba cách triển khai:
- Cloud API (chunkr.ai): Free tier 200 trang, không cần thẻ ngân hàng. Dùng proprietary model của Lumina AI cho độ chính xác cao hơn bản open-source.
- Self-host: Clone repo, cấu hình LLM qua
models.yaml, chạy vớidocker compose up. Hỗ trợ GPU (CUDA), CPU-only và Mac ARM (M1/M2/M3). Web UI tạilocalhost:5173, API tạilocalhost:8000. - Enterprise: Triển khai on-premises hoặc trong VPC với model tùy chỉnh và hỗ trợ trực tiếp từ founding team.
Cài đặt Python client:
pip install chunkr-aiGọi API cơ bản:
from chunkr_ai import Chunkr
client = Chunkr(api_key="your_key")
task = client.upload("document.pdf")
result = task.poll() # chờ xử lý xong
# Duyệt qua từng chunk
for chunk in result.chunks:
print(chunk.text, chunk.segment_type, chunk.bbox)Output mỗi segment bao gồm: text đã trích xuất, loại segment, tọa độ bounding box (x, y, width, height), số trang và định dạng HTML/Markdown tương ứng.
Hạn chế cần biết
Chunkr không phải giải pháp phù hợp cho mọi trường hợp. Một số điểm hạn chế rõ ràng:
- Excel chỉ ở Cloud/Enterprise: Bản open-source không hỗ trợ XLSX. Với RAG pipeline cần dữ liệu bảng tính, đây là giới hạn quan trọng.
- AGPL-3.0 license: Nếu nhúng Chunkr vào sản phẩm thương mại proprietary, bạn phải mua commercial license (liên hệ [email protected]). Khác hoàn toàn với MIT hay Apache 2.0.
- Ít định dạng hơn đối thủ: Chỉ hỗ trợ core formats, không có 90+ định dạng như LlamaParse.
- Chưa có GDPR: Compliance hiện tại là SOC 2 và HIPAA. Các tổ chức cần GDPR phải tự đảm bảo khi self-host hoặc chọn giải pháp khác.
- Startup 5 người: Độ trưởng thành enterprise chưa bằng IBM (Docling) hay các công ty $65M+ (Unstructured).
Ai nên dùng Chunkr
Chunkr phù hợp nhất khi bạn cần:
- Volume cao với budget cố định: Xử lý hàng triệu trang mỗi tháng với chi phí dự đoán được thay vì trả theo trang.
- Data sovereignty tuyệt đối: Toàn bộ pipeline chạy trong VPC của bạn, không có byte dữ liệu nào rời khỏi hệ thống.
- RAG pipeline tùy chỉnh sâu: Cần control từng bước - segment nào dùng OCR, segment nào cần VLM, chunk strategy ra sao.
- Healthcare, finance hoặc nghiên cứu: Nơi tài liệu phức tạp (công thức, bảng kỹ thuật, biểu đồ khoa học) là norm, không phải ngoại lệ.
Nếu bạn cần hỗ trợ 90+ định dạng, multimodal processing phức tạp, hoặc không muốn manage infrastructure - LlamaParse Cloud vẫn là lựa chọn tốt hơn. Nếu cần ETL quy mô lớn với hàng chục connector - Unstructured phù hợp hơn. Nếu muốn open-source thuần không ràng buộc thương mại - Docling với MIT license là lựa chọn thực tế hơn.
Nhưng nếu câu hỏi là "làm sao xử lý tài liệu phức tạp ở quy mô lớn, tự kiểm soát hoàn toàn, chi phí thấp nhất có thể" - Chunkr đang ở vị trí khó có đối thủ nào beat được trong bộ thông số đó.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ