
- Target cache hit ratio trên 85% với 3 lớp: Edge CDN, Redis Application Cache, và Query Result Cache - chỉ khi full miss mới chạm tới database.
- Bốn golden signals (Latency, Traffic, Errors, Saturation) phải được monitor từ ngày 1, không đợi production sập.
- Transactional Outbox và Saga Pattern thay thế 2PC - eventual consistency là trade-off đúng ở scale này.
- mTLS giữa mọi service và chaos engineering định kỳ là bắt buộc.
TL;DR
Phần 2 của blueprint backend 1 triệu users. Nếu chưa đọc Phần 1, hãy bắt đầu từ đó - foundation, Scale Cube, edge layer, và database strategy là prerequisite của phần này. Ở đây chúng ta đi vào 5 lớp còn lại: caching, observability, data consistency, security, và kiến trúc hoàn chỉnh assembled lại.
Bước 6: Multi-layer Caching
Caching là đòn bẩy chi phí lớn nhất trong hệ thống high-scale. Target cache hit ratio trên 85% - có nghĩa là ít nhất 85% request không bao giờ chạm tới database.
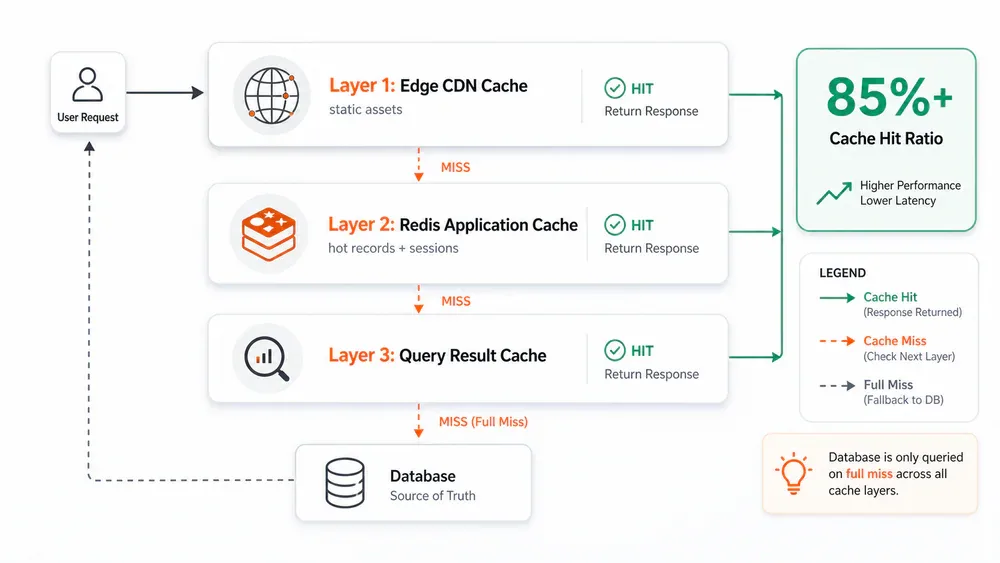
Kiến trúc 3 lớp:
- Lớp 1 - Edge CDN Cache: Static assets và response có thể cache publicly không bao giờ chạm tới origin. Cloudflare hoặc Fastly xử lý tại điểm gần user nhất.
- Lớp 2 - Redis Application Cache: Computed results, session data, và hot records sống ở đây. Đây là workhorse của hệ thống caching.
- Lớp 3 - Query Result Cache: Expensive database reads được cache tại query layer.
Chỉ khi full cache miss ở cả 3 lớp thì request mới chạm tới database.
Invalidation: Dùng event-driven invalidation qua Kafka. Khi user profile update, một event phải lập tức invalidate các cache key liên quan. TTL alone không đủ tin cậy cho critical data - một record sai có thể tồn tại suốt TTL window trước khi bị refresh.
Lưu ý về expiration policy: TTL quá ngắn - hệ thống liên tục query database. TTL quá dài - users thấy stale data. Điểm cân bằng phụ thuộc vào từng loại data; không có công thức chung.
Bước 7: Observability
Bạn không thể debug những gì bạn không thể nhìn thấy. Ở scale này, cần full observability từ ngày đầu - không phải sau khi production sập lúc 2 giờ sáng.
Stack chuẩn:
- Prometheus: metrics collection
- Jaeger: distributed tracing
- Loki: log aggregation
- OpenTelemetry: instrumentation layer thống nhất
- Grafana: dashboard tập trung
- Alertmanager → PagerDuty: routing alert cho on-call
Bốn golden signals - instrument trên mọi service:
- Latency: request mất bao lâu
- Traffic: bao nhiêu request đang đến
- Errors: tỉ lệ request thất bại
- Saturation: resource đang gần limit đến mức nào
Định nghĩa SLO cụ thể và track error budget. Alert trước khi users nhận ra vấn đề - không phải sau. Observability không phải nice-to-have; ở scale này đây là điều kiện cần thiết để operate.
Bước 8: Data Consistency và Idempotency
Distributed systems fail theo những cách partial và không thể đoán trước. Design cho điều này từ đầu - không phải sau khi incident xảy ra.
Transactional Outbox Pattern. Ghi event vào một bảng database trong cùng transaction với business logic. Một background process đọc và publish chúng. Event không bao giờ bị mất, kể cả khi message broker down. Pattern này thêm khoảng 10-50ms latency (polling interval) - trade-off hoàn toàn chấp nhận được so với việc mất event.
Điểm quan trọng: message relay có thể publish một message hơn một lần (crash sau khi publish nhưng trước khi ghi nhận). Consumer phải idempotent - phải xử lý duplicate gracefully.
Saga Pattern. Cho transaction span nhiều service, dùng chuỗi compensating action thay vì two-phase commit (2PC). Mỗi bước có rollback định nghĩa sẵn nếu bước downstream fail. 2PC không viable trong distributed system thực tế - coupling giữa database và message broker quá lớn, và nhiều database không support 2PC.
Idempotency Keys. Mọi mutating operation phải chấp nhận một unique request ID. Nếu cùng request đến hai lần, trả về kết quả gốc. Consumers duy trì inbox table lưu processed message ID trong window 24-72 giờ. Đây là cách duy nhất an toàn để handle retry trên network không đáng tin cậy.
Eventual consistency không phải điểm yếu ở scale này - đây là trade-off kiến trúc đúng đắn. Strong consistency cho mọi thứ sẽ tạo ra bottleneck serialization không thể scale.
Bước 9: Security
Security không phải afterthought - phải được build vào kiến trúc từ đầu:
- mTLS giữa mọi internal service: mọi service-to-service call đều được authenticate và encrypt
- Zero-trust network: không service nào tin service khác mặc định, bất kể request đến từ đâu trong network
- Encryption at rest và in transit: không có ngoại lệ
- Chaos engineering định kỳ: chủ động kill random pods trong production để verify resilience assumptions trước khi traffic thật làm điều đó
Phát hiện failure mode trong controlled test tốt hơn vô cùng so với phát hiện nó trong traffic spike lúc 2 giờ sáng. Chaos engineering không phải rủi ro - đây là cách duy nhất để có confidence thực sự vào resilience của hệ thống.
Kiến trúc hoàn chỉnh
Assembled lại, toàn bộ stack trông như sau:
1 Triệu Users
↓
Edge + CDN + WAF (Cloudflare/Fastly)
↓
Global Load Balancer (AWS Global Accelerator)
↓
API Gateway (Rate Limiting + Auth + Bot Detection)
↓
Stateless Application Services
↓
┌─────────────────────────────────────────┐
│ Redis Cluster │ Kafka Event Bus │
│ Sharded PostgreSQL + Citus │
│ Cassandra/ScyllaDB (high-write) │
│ ClickHouse (analytics) │
└─────────────────────────────────────────┘
↓
Background Workers
↓
Observability: Prometheus, Grafana, Jaeger, LokiKiến trúc này xử lý 1 triệu daily active users với headroom đáng kể để scale lên hàng chục triệu mà không cần rewrite căn bản.
Trước khi bạn bắt đầu
- Start small và measure mọi thứ. Optimize dựa trên data, không phải assumptions.
- Load test với k6 hoặc Locust ở mức 2x expected peak traffic trước mọi launch.
- Dùng feature flags và canary deployments - không ship thẳng lên 100% users.
- Profile hot paths trước khi optimize. Bottleneck hiếm khi ở chỗ bạn nghĩ.
- Dùng spot hoặc preemptible instance cho non-critical workload để giảm infrastructure cost đáng kể.
Sự khác biệt giữa system sống sót qua scale và system sụp dưới nó không phải talent. Đó là kiến trúc quyết định sớm - trước khi traffic đến.
via Akintola Steve trên X | Pattern: Transactional Outbox | Postgres + ClickHouse Stack | AlgoMaster - Scaling to 10M Users
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ