
- Peak QPS 10.000-50.000 requests/giây, P99 latency dưới 200ms, uptime 99.99% - đây là bộ yêu cầu tối thiểu trước khi viết dòng code đầu tiên.
- Scale Cube chia bài toán thành 3 trục: nhân bản ngang, phân tách theo chức năng, và phân vùng dữ liệu.
- Microservices sớm là sai lầm lớn nhất - bắt đầu từ modular monolith.
- Database không bao giờ chỉ 1 lớp: PostgreSQL + Citus cho OLTP, ScyllaDB cho high-write path, ClickHouse cho analytics.
TL;DR
Xây hệ thống chịu 1.000 users thì dễ. Xây hệ thống vẫn nhanh, rẻ, và ổn định ở 1 triệu users concurrent - đó là chỗ hầu hết backend engineer thất bại. Blueprint này không phải lý thuyết: mọi pattern đều đang chạy trong production. Phần 1 bao gồm 5 quyết định đầu tiên: requirements, nền tảng, edge layer, application design, và database strategy.
Bước 1: Xác định requirements trước khi code
Đây là bước hầu hết engineer bỏ qua - và đó là lý do họ phải rebuild lại toàn bộ sau 6 tháng.
Trước khi viết bất kỳ dòng code nào, phải nail được non-functional requirements:
Peak QPS: 10.000 - 50.000 requests/giây
P99 latency: dưới 200ms (target dưới 100ms)
Uptime: 99.99% - tương đương khoảng 4 phút downtime tối đa mỗi tháng
Consistency model: strong cho dữ liệu tài chính, eventual cho feed và timeline
Cost ceiling: đặt ngưỡng chi phí cụ thể theo đơn vị USD/1.000 users từ ngày đầu
Sau đó dùng Scale Cube để tư duy trong 3 chiều trước khi thiết kế bất cứ thứ gì:
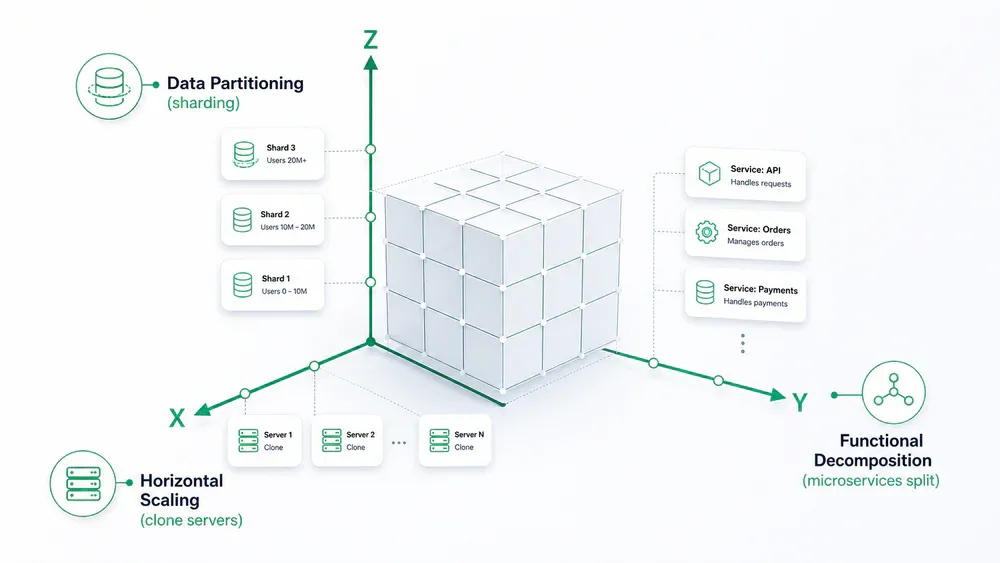
X-Axis: Nhân bản ngang - chạy nhiều instance giống nhau sau load balancer
Y-Axis: Phân tách theo chức năng - tách thành các service nhỏ hơn, chuyên biệt hơn
Z-Axis: Phân vùng dữ liệu - shard theo user_id hoặc region
Mental model này ngăn được 90% thảm họa scale trước khi chúng xảy ra.
Bước 2: Chọn nền tảng đúng
Ngôn ngữ và framework phụ thuộc vào ưu tiên của team:
Go hoặc Rust: raw performance và memory efficiency tốt nhất
TypeScript (NestJS) hoặc Java/Kotlin (Spring Boot): khi tốc độ phát triển của team quan trọng hơn throughput
API strategy:
Public-facing: REST + GraphQL
Internal service-to-service: gRPC - typed, nhanh, hỗ trợ streaming
Quan trọng nhất: bắt đầu bằng modular monolith. Chỉ tách ra microservice khi một service cụ thể đã trở thành bottleneck có thể đo được. Microservices sớm là kẻ giết chết engineering velocity lớn nhất ở scale.
Microservices giải quyết development complexity và bottleneck cụ thể - nhưng chúng đi kèm chi phí lớn: phải implement Transactional Outbox, Saga Pattern, và idempotency keys đúng cách. Chi phí này không đáng nếu bottleneck chưa được chứng minh bằng số liệu.
Bước 3: Edge layer và Load Balancing
Users toàn cầu đồng nghĩa với latency toàn cầu - trừ khi bạn đẩy infrastructure ra đến edge.
Request path chuẩn trông như thế này:
User (Lagos / London / Mumbai)
Cloudflare hoặc Fastly: CDN, DDoS protection, edge caching
Global Load Balancer: AWS Global Accelerator hoặc GCP equivalent
API Gateway: rate limiting, WAF, bot detection
Application Services
Ở quy mô 1 triệu users, edge layer là tuyến phòng thủ đầu tiên. Mục tiêu là xử lý nhiều traffic nhất có thể trước khi request chạm tới application server. Static assets không nên serve từ web server - CDN làm việc đó tốt hơn nhiều, và giảm tải đáng kể cho origin.
Bước 4: Thiết kế Application Layer
4 quy tắc không thể thỏa hiệp:
1. Mọi service phải stateless. Session data thuộc về Redis hoặc Dragonfly, không bao giờ trong application memory. Nếu một server chết, không có user session nào được chết theo nó. Đây cũng là điều kiện để auto-scale hoạt động đúng - không thể thêm/bớt server tự do nếu state gắn với instance cụ thể.
2. Background jobs thuộc về queue. Dùng Kafka hoặc Pulsar ở scale này - không phải RabbitMQ, không phải in-memory processing, không phải setTimeout. Kafka đảm bảo at-least-once delivery và cho phép producer/consumer scale độc lập.
3. Resilience ở cấp độ từng call. Circuit breakers, retry với jitter, và hard timeout trên mọi outbound call. Một dependency chậm không được cascade thành system failure toàn bộ.
4. Auto-scale theo đúng signal. CPU là lagging indicator. Scale theo queue depth và error rate - những metric này phản ánh áp lực thực tế của hệ thống trước khi nó visible trong CPU numbers.
Bước 5: Database Strategy
Một database duy nhất vừa là performance ceiling, vừa là single point of failure. Không bao giờ chỉ dùng một.
Stack được khuyến nghị:
OLTP chính: PostgreSQL + Citus cho horizontal sharding
High-write paths: Cassandra hoặc ScyllaDB (ScyllaDB nhanh hơn Cassandra 10-50x nhờ shard-per-core architecture)
Caching và real-time data: Redis Cluster
Analytics và aggregation: ClickHouse
Mọi write đi qua query router, Vitess, hoặc Citus. Shard theo user_id với modulo strategy để dữ liệu phân tán đều. Read replicas đứng sau PgBouncer cho connection pooling.
Một quy tắc không thể bỏ qua: chọn shard key từ ngày đầu tiên. Thay đổi shard key sau khi data đã vào production là một trong những migration đau đớn nhất mà một engineering team có thể trải qua. Celebrity problem - khi Katy Perry, Justin Bieber, và Lady Gaga cùng rơi vào một shard - là bài học đắt giá mà nhiều team phải trả.
Tiếp theo
Phần 1 bao gồm foundation: requirements cứng, Scale Cube, nền tảng kỹ thuật, edge layer, và database stack. Đây là 5 quyết định quyết định phần lớn khả năng scale của hệ thống.
Phần 2 sẽ đào sâu vào 5 lớp còn lại: multi-layer caching (target 85%+ hit ratio), observability với 4 golden signals, data consistency và idempotency, security với zero-trust model, và toàn bộ kiến trúc assembled lại.
via ByteByteGo - Scale From Zero To Millions | The Scale Cube
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ