
- Xây agent ban đầu tốn 20% công sức - production-ready mới tốn 80% còn lại.
- Chi phí thực tế cho research agent: ~$0.08 mỗi lần chạy, 1.000 lần/ngày tương đương $2.400 mỗi tháng.
- Gartner: 50% AI agent deployment failures sẽ gây thiệt hại tài chính cho enterprises vào năm 2030.
- Security cho agent là bảo vệ trước chính hệ thống của bạn.
TL;DR
Xây được agent là 20% công việc. 80% còn lại là đưa nó lên production đúng cách. Phần 3 của series AI Agents tập trung vào 5 vấn đề production thực tế: advanced task decomposition, cải thiện chất lượng theo thứ tự đúng, latency và cost thực tế, observability, và security - những thứ phân biệt team ship sản phẩm thực sự và team mãi kẹt ở giai đoạn prototype.
Advanced Task Decomposition - 4 pattern cho hệ thống phức tạp
Trong multi-agent phức tạp, cách bạn decompose task quyết định phần lớn sự thành công. Có 4 patterns:
Functional: chia theo technical domain. Frontend agent, Backend agent, Database agent. Classic cho engineering teams và phù hợp khi có phân chia team rõ ràng.
Spatial: chia theo cấu trúc file hoặc directory. Agent 1 xử lý /services/users/, agent 2 xử lý /services/orders/. Hiệu quả cho codebase lớn, giảm thiểu conflicts giữa agents.
Temporal: chia theo phase tuần tự. Phase 1: Research. Phase 2: Plan. Phase 3: Build. Phase 4: Launch. Mỗi phase phải hoàn thành trước khi phase tiếp theo bắt đầu.
Data-driven: chia theo data partitions. Agent 1 xử lý log tuần 1, agent 2 xử lý log tuần 2. Mạnh cho large datasets và các tác vụ cần parallelize analysis.
Bạn có thể kết hợp các patterns. Ví dụ: functional decomposition cho cấu trúc chính, kết hợp temporal decomposition bên trong từng agent. Dùng cái phù hợp nhất với natural boundaries của task bạn đang giải quyết.
Cải thiện chất lượng trong production - Thứ tự quan trọng
Hệ thống đang chạy nhưng chưa đủ tốt. Thứ tự fix có tầm quan trọng quyết định:
Non-LLM components (web search, RAG, OCR, code execution):
Tune knobs trước: search date ranges, top-k results, chunk size, similarity thresholds
Swap providers nếu cần: thử search APIs, vision models, parsers khác nhau
LLM components (generation, reasoning, extraction) - theo thứ tự này:
Prompt tốt hơn: thêm constraints, examples, output schemas. Một system prompt được viết tốt giảm 60-80% lỗi.
Thử model khác: một số models giỏi code, một số giỏi following instructions phức tạp.
Decompose tasks khó thành pieces nhỏ hơn.
Fine-tune: chỉ dùng như biện pháp cuối cùng - tốn kém và phức tạp, chỉ phù hợp cho những phần trăm cuối cùng của quality improvement.
Thứ tự này quan trọng. Phần lớn teams đạt chất lượng đủ tốt ngay ở bước 2. Thực tế từ production: một deployment cho công ty bảo hiểm bắt đầu ở 85% accuracy, đạt 95% sau 2 tháng continuous tuning. Build ban đầu tốn khoảng 20% công sức tổng thể - refinement để production-ready chiếm 80% còn lại.
Latency và Cost - Con số thực tế bạn cần biết
Chi phí thực tế cho một research agent run điển hình:
LLM generation calls: ~$0.04
Web search API calls: ~$0.02
Embedding calls: ~$0.005
Infrastructure: ~$0.015
Tổng: ~$0.08 mỗi lần chạy
1.000 lần chạy mỗi ngày = $80/ngày = $2.400/tháng. Đối với multi-agent systems, chi phí là multiplicative chứ không phải additive - vì mỗi agent thấy full conversation history, cost có thể gấp 5-10 lần single agent với cùng task.
Giảm cost:
Tấn công bucket lớn nhất trước - đừng cố optimize đều khắp nơi
Tier models: cheap model cho tasks đơn giản, frontier model chỉ cho reasoning phức tạp
Cache aggressively: search results, embeddings, summaries - tránh duplicate LLM calls
Constrain outputs: "Return JSON, 5 fields max" - output ngắn hơn nghĩa là ít token hơn
Batch operations khi có thể
Giảm latency:
Measure từng bước riêng lẻ - tìm bottleneck thực sự, không phải đoán
Parallelize những gì không phụ thuộc vào nhau
Right-size models: fast/cheap model cho bước đơn giản, big model chỉ cho reasoning
Trim context: prompts ngắn hơn decode nhanh hơn
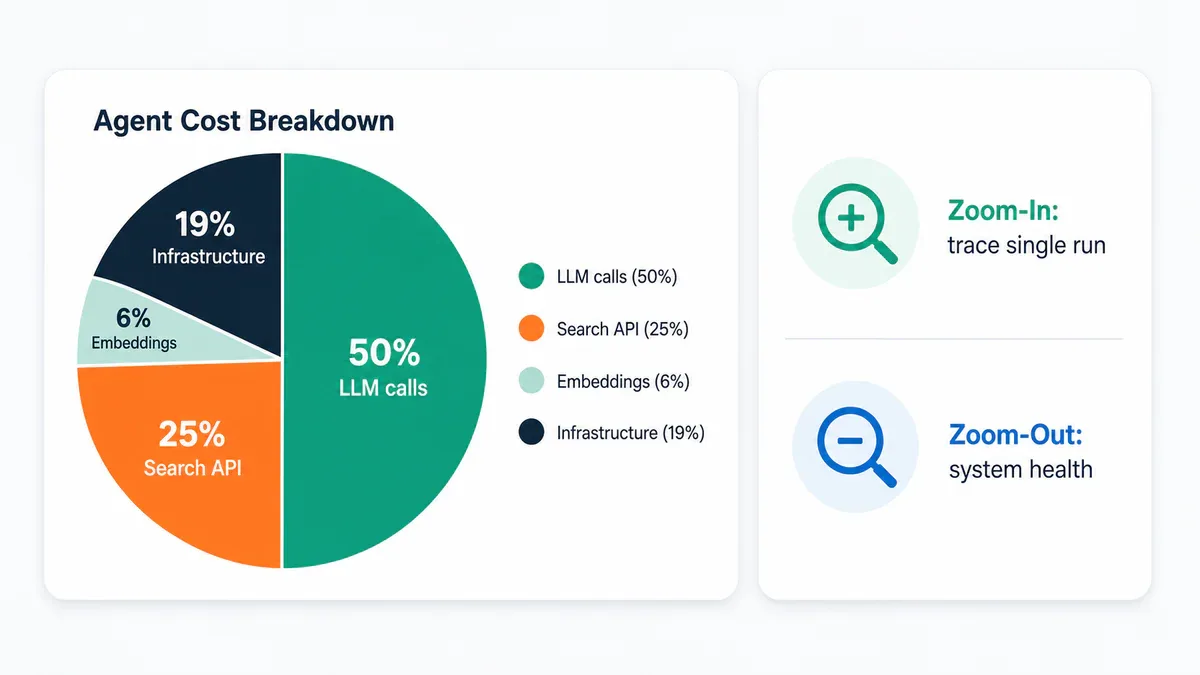
Chi phí thực tế mỗi lần chạy và hai chế độ observability cho production system
Observability - Nhìn thấy agent làm gì ở scale
Traditional software: trace execution path - A gọi B, B gọi DB, trả kết quả.
AI agents không hoạt động như vậy. Chúng non-deterministic - cùng input có thể ra output khác nhau. Distributed execution. External dependencies có thể fail bất kỳ lúc nào. Bạn cần hai loại visibility:
Zoom-in metrics - debug single run:
Full trace: mọi prompt, mọi tool call, mọi token được dùng
Tại sao agent chọn tool này chứ không phải tool khác?
Mỗi bước trả về gì?
Fail chính xác ở bước nào?
Log không chỉ cái gì xảy ra mà cả lý do tại sao. Ví dụ: "Agent chọn web search thay vì RAG vì query chứa từ 'recent'" - loại context này vô giá khi debug production issues.
Zoom-out metrics - system health:
Quality scores theo thời gian - trend đang đi lên hay đi xuống?
Hallucination rates
Success rates
Những thay đổi gần đây đang giúp hay gây hại?
Bạn không thể manually inspect từng trace ở scale. Dùng quality sampling - evaluate một percentage của tất cả runs. Build trend line. Đây là cách catch regressions trước khi users phát hiện.
Gartner dự đoán 50% AI agent deployment failures sẽ gây thiệt hại tài chính hoặc uy tín cho enterprises vào năm 2030. Observability không phải nice-to-have - đó là bảo hiểm bắt buộc.
Security - Phần không ai nói đến nhưng nên nói
Security cho AI agents không giống traditional app security. Bạn không chỉ bảo vệ trước external attackers - mà còn bảo vệ trước chính hệ thống của bạn đưa ra các quyết định nguy hiểm.
Các threats chính:
Prompt injection: nội dung độc hại trong user input có thể hijack instructions của agent, dẫn đến privilege escalation hoặc data exfiltration.
Unsafe code generation: agent tự viết code truy cập sensitive data hoặc thực hiện hành động gây hại.
Data leakage: PII hoặc thông tin độc quyền bị exposed qua outputs hoặc tool calls. IBM research cho thấy shadow AI usage thêm trung bình $670.000 vào breach costs.
Resource exhaustion: agents chạy vòng lặp vô hạn, đốt cháy expensive API calls mà bạn phải trả tiền.
Code execution là tính năng rủi ro nhất trong agent systems. Nếu bạn enable nó, đây là cách làm đúng:
Sandbox trong Docker - container bị destroy sau mỗi run
Đặt hard resource limits: timeouts, memory caps, CPU limits - không thể thương lượng
Whitelist chỉ các thư viện safe cụ thể, không cho phép import tùy ý
Validate tất cả inputs trước khi reach agent
Scan tất cả outputs cho sensitive data: API keys, PII, credentials
Dùng deterministic I/O - code trả về structured JSON, không free-form text đến end users
Kết - Roadmap đầy đủ
Đây là roadmap từ prototype đến production của series 3 phần này:
Phần 1 - Nền tảng:
Agent hoạt động theo vòng lặp ReAct, không phải one-shot
Context engineering mới là thứ tạo ra sự thông minh thực sự
Task decomposition là kỹ năng quan trọng nhất
Phần 2 - Intermediate:
Evaluate từ ngày đầu, memory khác knowledge
Ba lớp guardrails, 4 design patterns, bắt đầu Sequential
Phần 3 - Production:
4 decomposition patterns: functional, spatial, temporal, data-driven
Fix prompts trước khi nghĩ đến fine-tune
Measure latency và cost từng bước, tấn công bucket lớn nhất
Hai chế độ observability: zoom-in traces và zoom-out health metrics
Security = bảo vệ trước chính hệ thống của bạn, không chỉ từ bên ngoài
Phần lớn người bắt đầu build agents. Ít người ship agents hoạt động đáng tin cậy ở scale. Khoảng cách đó là tất cả những gì trong series 3 bài này.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ