
- Build agent chạy được là dễ - build agent đáng tin cậy trong production là chuyện khác.
- Evaluation từ ngày đầu giúp catch lỗi trước users.
- Memory dynamic và Knowledge static là hai thứ hoàn toàn khác nhau.
- Phần lớn production systems dùng ít nhất 2 trong 3 loại guardrails.
TL;DR
Build được agent chạy được là 20% công việc. 80% còn lại là làm nó hoạt động đáng tin cậy. Phần 2 của series AI Agents tập trung vào 5 building blocks trung cấp mà bất kỳ ai muốn ship hệ thống thực sự đều phải nắm: evaluation, memory, guardrails, 4 design patterns, và các mô hình phối hợp multi-agent.
Evaluation - Thứ nhàm chán ngăn cách pro và hobbyist
Không ai muốn nói về evals. Nhưng tất cả những ai ship production systems đều làm.
Cách đánh giá agent hoạt động tùy theo loại task:
Task đơn giản: đếm câu trả lời đúng. Bot customer service có trả lời đúng câu hỏi tồn kho không? Có/không - đơn giản vậy thôi.
Task phức tạp: dùng LLM làm judge. Một model thứ hai chấm điểm output theo thang 1-5 dựa trên rubric cố định. Bài essay có luận điểm mạnh không? Có citation đúng không? Đúng tone không?
Hai cấp evaluation bạn cần:
Component-level: từng bước riêng lẻ có hoạt động không? Search queries có đủ cụ thể không? Critique có đang đưa feedback thực sự không?
End-to-end: output cuối cùng có tốt không?
Nếu end-to-end fail nhưng component evals pass - vấn đề ở handoff giữa các bước. Nếu một component cụ thể fail - agent đó cần cải thiện. Hai tình huống này cần hai cách fix hoàn toàn khác nhau.
Bắt đầu evaluate từ ngày đầu tiên. Đừng chờ hệ thống eval hoàn hảo mới bắt đầu. Ship nhanh và iterate. Xây dựng eval harness với tối thiểu 50-100 test cases đa dạng trước khi push lên production.
Memory và Knowledge - Hai thứ khác nhau hoàn toàn
Đây là sự nhầm lẫn phổ biến nhất trong community. Chúng không phải là một.
Memory = dynamic, cập nhật mỗi lần chạy.
Short-term: agent ghi chú khi làm việc. Agents khác trong hệ thống có thể đọc những ghi chú đó.
Long-term: sau mỗi task, agent reflect - cái gì tốt? cái gì không? Lưu lại bài học. Lần chạy tiếp sẽ load bài học và áp dụng. Đây chính xác là cách bạn "train" agents mà không cần fine-tuning tốn kém.
Knowledge = static, load sẵn từ đầu.
PDFs, CSVs, internal docs, database access
Thư viện tham khảo của agent - cho vào một lần, agent kéo ra mỗi khi cần
Nhớ đơn giản: Memory = thứ bạn học từ kinh nghiệm. Knowledge = sách giáo khoa bạn có thể tra cứu. Cả hai đều quan trọng, không cái nào thay thế cái còn lại.
Lưu ý thực tế từ production: agents không có memory thì bị giới hạn, nhưng agents với memory thiếu tối ưu thì tốn kém. Smart summarization - giữ context quan trọng trong khi cắt bỏ redundancy - là thứ tạo ra sự khác biệt giữa hệ thống dùng được và hệ thống degradate theo thời gian dài.
Guardrails - Vì agent hoạt động được không có nghĩa là an toàn
LLMs là non-deterministic. Chúng có thể sai format, đưa fact sai, hoặc đi lạc khỏi task. Guardrails là quality gate giữa "agent nói xong rồi" và "task thực sự được hoàn thành đúng cách".
Ba loại guardrails:
Type 1 - Code checks (nhanh + rẻ): Dùng cho thứ deterministic. Output đúng format không? Đúng độ dài không? Required fields có đủ không? Viết một validation function đơn giản, chạy tức thì. Ưu tiên cái này khi có thể.
Type 2 - LLM judge: Dùng cho quality checks tinh tế hơn. Ví dụ: "Response này có factually consistent với source documents không?" Nếu judge nói không, nó giải thích tại sao, agent revise, rồi thử lại.
Type 3 - Human in the loop: Dùng cho quyết định high-stakes. Agent dừng trước khi finalize, gửi output để human review và approve hoặc reject.
Phần lớn production systems dùng ít nhất 2 trong 3 loại này. Trong môi trường enterprise, guardrails thường được tổ chức theo layers: data context - design-time governance - runtime enforcement - identity management.
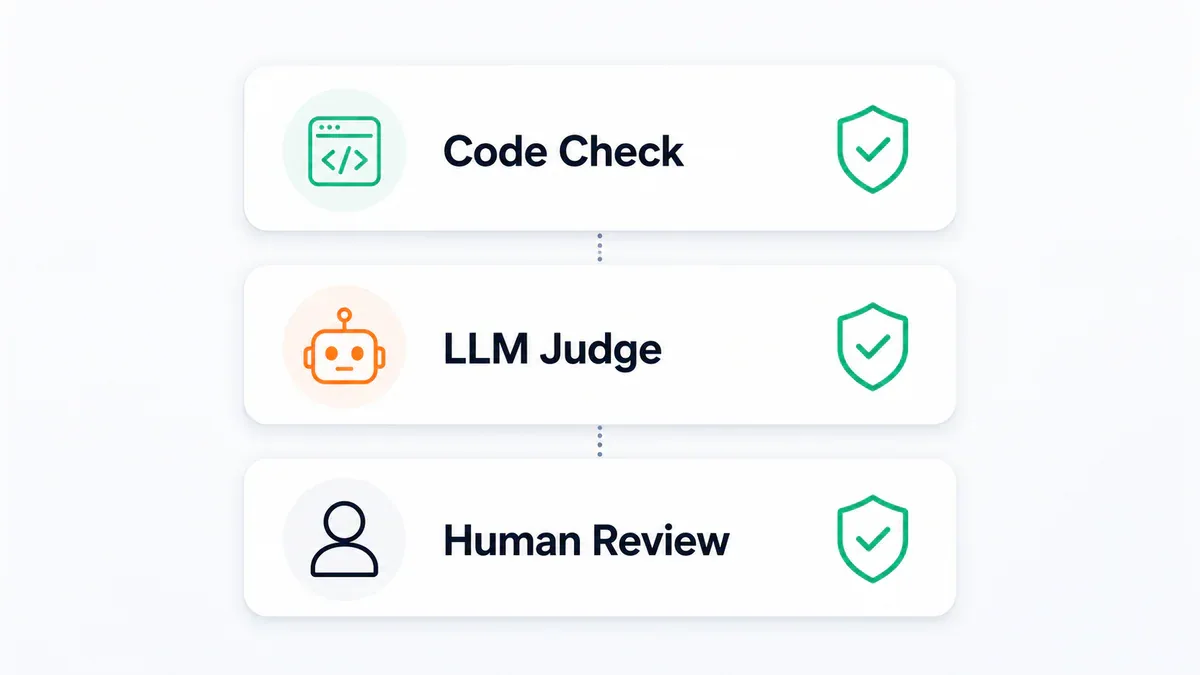
Ba lớp guardrails - từ nhanh/rẻ đến chậm/chắc chắn
4 Design Patterns luôn giúp agent tốt hơn
Bốn patterns này được validate trong thực tế và đáng tin cậy trong mọi agent system:
Pattern 1: Reflection
Đừng dừng ở bản nháp đầu tiên. Model tạo output, tự critique, rồi viết lại dựa trên critique đó. Email v1: "Hi, gặp tháng sau nhé." Critique: ngày mơ hồ, không có sign-off, tone quá casual. Email v2: "Hi Alex, mình đề xuất gặp ngày 5-7/6, bạn thấy ngày nào tiện? Trân trọng." Pattern này càng mạnh hơn với code - viết code, chạy, capture errors, feed back, model tự sửa lỗi.
Pattern 2: Tool Use
Cho LLM menu các functions nó có thể gọi. Model tự quyết định khi nào và dùng tool nào. Web search, database query, code execution, calendar, email, API calls. LLM không thể làm những thứ này một mình - tools là cách agent tương tác với thế giới thực.
Pattern 3: Planning
Thay vì pipeline cố định, để agent tự quyết định các bước thực hiện. Cho nó toolkit, prompt nó lên kế hoạch, execute từng bước. Ví dụ retail: "Có kính mắt tròn dưới 2 triệu không?" Agent tự plan: tìm trong descriptions, check tồn kho, filter theo giá, rồi trả lời. Bạn không script những bước cụ thể đó - agent tự chọn dựa trên context.
Pattern 4: Multi-Agent Collaboration
Chia công việc phức tạp cho các agents chuyên biệt. Researcher truyền cho Designer, Designer truyền cho Writer. Mỗi agent giỏi ở lĩnh vực cụ thể của mình. Output tốt hơn vì không có agent nào phải cố làm tất cả mọi thứ.
Multi-Agent System Design - 4 mô hình phối hợp
Khi bạn cần nhiều agents cùng làm việc, câu hỏi quan trọng là: phối hợp như thế nào?
Sequential: mỗi agent xong mới pass output cho agent tiếp theo. Như dây chuyền lắp ráp: Researcher - Designer - Writer - Done. Dễ debug, predictable. Bắt đầu ở đây.
Parallel: chạy independent agents đồng thời. Researcher và Designer làm song song, Writer kết hợp outputs. Nhanh hơn nhưng phức tạp hơn về coordination.
Manager Hierarchy: một manager agent điều phối specialists. Manager lên kế hoạch, delegate, và review. Specialists báo cáo lại cho manager, không phải cho nhau. Đây là mô hình phổ biến nhất trong production systems thực tế hiện nay.
All-to-All: bất kỳ agent nào cũng có thể nhắn cho bất kỳ agent nào. Chaotic và khó đoán. Chỉ dùng cho creative hoặc low-stakes work. Tuyệt đối không dùng trong production.
Rule of thumb: bắt đầu Sequential. Thêm complexity chỉ khi thực sự cần, không phải vì nó trông thú vị hơn.
Kết
5 building blocks của intermediate agent development:
Evaluate từ ngày đầu - component-level lẫn end-to-end
Memory dynamic và Knowledge static là hai thứ hoàn toàn khác nhau
Ba lớp guardrails theo thứ tự: code checks - LLM judge - human in the loop
4 patterns luôn hiệu quả: reflection, tool use, planning, multi-agent collaboration
Bắt đầu Sequential, thêm coordination complexity chỉ khi thực sự cần
Phần 3 đi vào những gì thực sự giúp bạn từ prototype đến production: advanced decomposition, latency và cost thực tế, observability, và security. Đọc tiếp Phần 3
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ