
- AgingBench phát hiện 4 cơ chế lão hóa khiến AI agent suy giảm dù model weights không thay đổi.
- Chỉ đổi compaction prompt tạo ra gap 4,5x về half-life.
- Typed-state overlay giảm accumulator error 47%.
- Forced re-read đẩy recall của Opus-4.7 từ 0,68 lên 0,91.
TL;DR
Nhóm nghiên cứu tại UT Austin vừa công bố AgingBench - benchmark đầu tiên đo sự suy giảm độ tin cậy của AI agent theo thời gian thực tế sau khi deploy. Paper "Your Agents Are Aging Too" xác định 4 cơ chế lão hóa khiến agent hỏng dần qua từng session, ngay cả khi model weights hoàn toàn không đổi. Kết quả từ 14 model, 7 kịch bản, ~400 lần chạy cho thấy: cùng một lỗi có thể cần cách sửa hoàn toàn khác nhau tùy nguyên nhân gốc rễ.
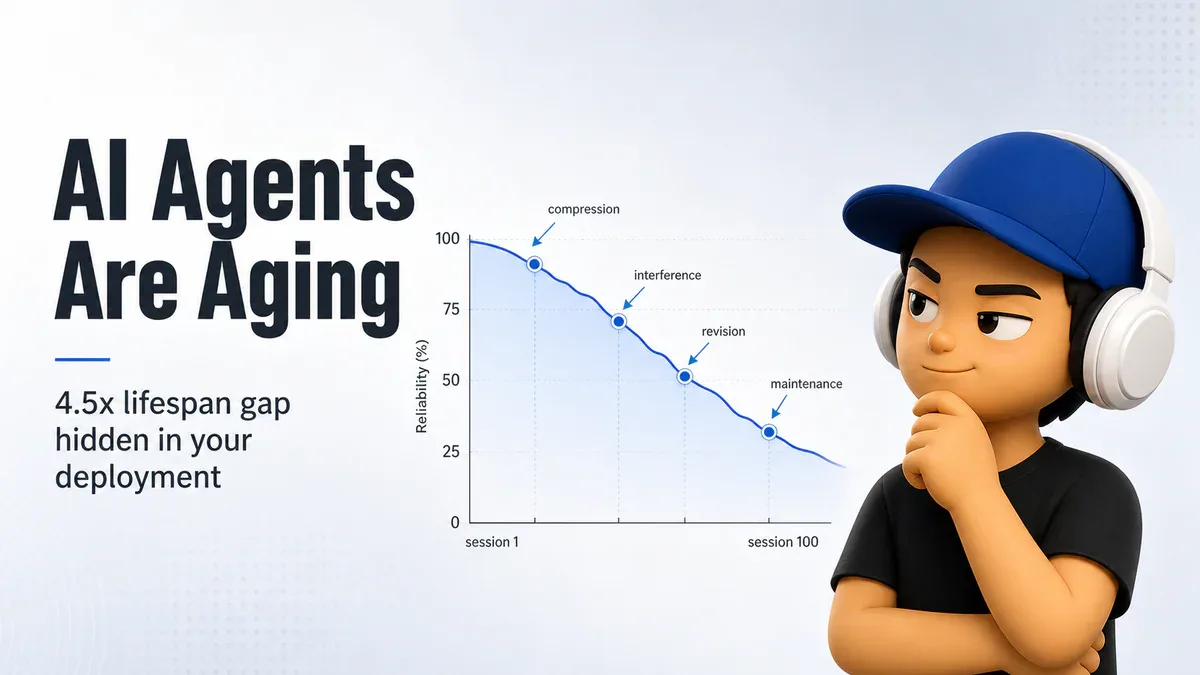
Reliability của agent suy giảm qua từng session qua 4 cơ chế: compression, interference, revision, maintenance
Vấn đề: Agent "già đi" dù model không thay đổi
Hầu hết các benchmark AI đánh giá agent tại một thời điểm duy nhất - ngày đầu tiên deploy. Nhưng thực tế, agent trong production chạy xuyên suốt nhiều tháng, tích lũy lịch sử tương tác, cập nhật memory, và trải qua các sự kiện bảo trì định kỳ.
Vấn đề là: frozen model weights không có nghĩa là frozen behavior. Một agent đầy đủ là một harness gồm LLM + memory writing + storage + retrieval + tools + prompts + maintenance procedures. Mỗi khi agent tóm tắt lịch sử, tích lũy thêm memory tương tự, revise dữ kiện, hay trải qua recompaction - effective state của system thay đổi.
Các dấu hiệu lão hóa điển hình trong thực tế: liều thuốc hàng ngày bị tóm tắt thành "một loại thuốc hàng ngày" (mất chi tiết cụ thể); "John Smith" bị nhầm với "John Smyth" do memory tích lũy; subscription đã hủy vẫn được treat như còn hiệu lực; lịch thứ Ba hàng tuần biến mất sau maintenance.
Bốn cơ chế lão hóa
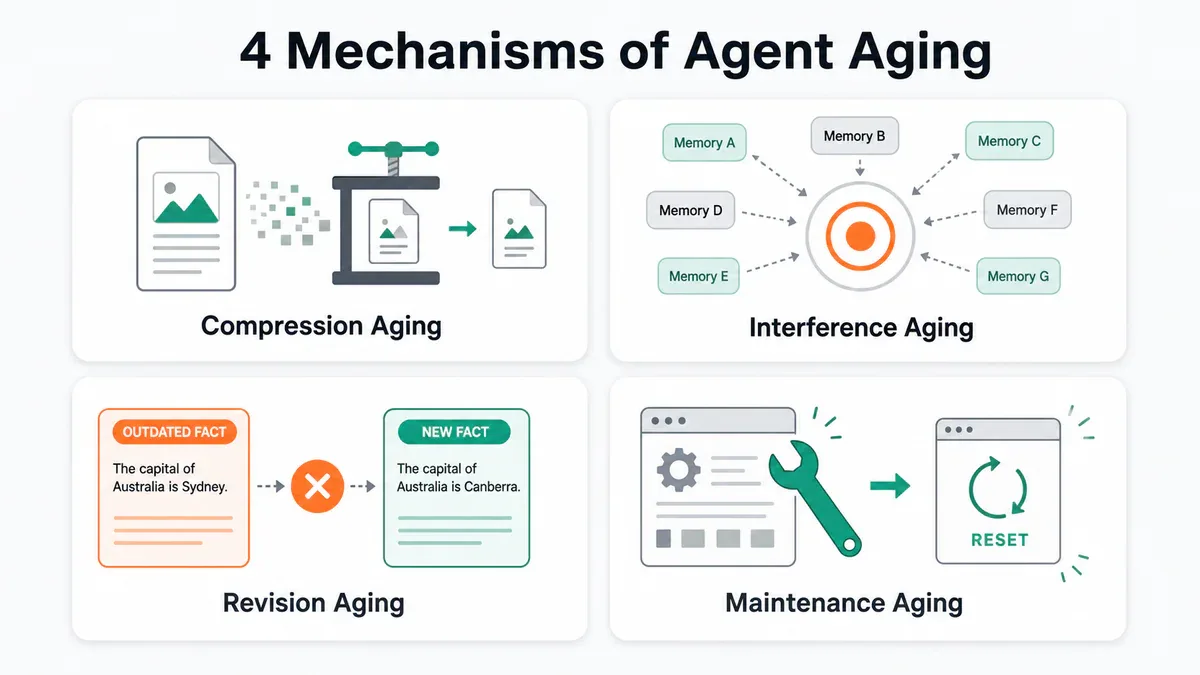
Bốn cơ chế lão hóa trong AgingBench - mỗi cơ chế cần cách sửa khác nhau
AgingBench tổ chức sự suy giảm thành 4 nhóm độc lập:
Compression aging: Write-time summarization bỏ mất các chi tiết quan trọng cho query trong tương lai. Vì phải quyết định giữ gì ngay lúc ghi, trong khi chưa biết sẽ được hỏi gì, các giá trị cụ thể (số tiền, tên riêng, constraint) bị tóm gọn thành mô tả chung chung.
Interference aging: Memory tương tự tích lũy theo thời gian làm "chèn" mất target fact khi retrieval. Cơ chế này xảy ra ngay cả khi không có thông tin nào bị mất - chỉ cần có quá nhiều entry giống nhau là đủ gây nhiễu.
Revision aging: Khi dữ kiện thay đổi, agent không propagate update đúng cách. Dạng nguy hiểm nhất là dynamic latent state: khi câu trả lời được tính từ nhiều delta tích lũy (ví dụ budget = ban đầu + tổng các thay đổi), một delta bị bỏ sót gây sai lệch tích lũy từ session đó trở đi.
Maintenance aging: Các sự kiện vận hành định kỳ - recompaction, prompt update, history flush - thay đổi behavior của agent một cách im lặng. Đây là cơ chế duy nhất do hành động tác động lên agent, không phải từ accumulated state.
Những con số đáng chú ý
AgingBench tiến hành ~400 lần chạy qua 8-200 sessions trên 14 model (từ 7B đến 120B), bao gồm các model open-source (Llama-3.1-8B, Qwen3-8B/14B, DeepSeek-R1) và closed-source (GPT-4o, GPT-5-mini, Claude Haiku 4.5/4.6, Claude Sonnet 4.6, Claude Opus-4.7). Chi phí reproduce toàn bộ matrix: ~1 GPU-day trên H100 cộng ~$25 API spend.
Một số phát hiện nổi bật:
4,5x half-life gap từ một dòng prompt: Chỉ đổi compaction prompt từ dạng "lossy" (tóm tắt tổng quát) sang dạng "careful" (giữ nguyên tên, số, dollar amount, ngày tháng) tạo ra gap gần 4,5 lần về half-life - số session trước khi agent mất 50% khả năng. Cùng một model (Haiku 4.5), khác duy nhất ở prompt.
Typed-state overlay giảm lỗi 47%: JSON sidecar lưu riêng các giá trị số (budget, counter, versioned constraint) giảm accumulator error 25% với lossy backend và 47% với careful backend, chi phí overhead chỉ ~10% wall-time. Điều này gợi ý vấn đề revision aging là về dạng biểu diễn, không phải capacity.
Write-read gap trong autonomous agent: Với Opus-4.7 ở Scenario 7, forced re-read ablation (bắt agent đọc lại ít nhất 2 file trước khi trả lời) đẩy recall từ 0,68 lên 0,91, accumulator error từ 2,25 xuống 0,00. Agent ghi đúng nhưng không đọc lại đủ khi cần.
Cùng error rate, khác root cause: Ba model có error rate gần nhau (~0,60-0,82) nhưng breakdown hoàn toàn khác: Scenario 1 dominated bởi Utilization failure, Scenario 2 bởi Write/Compression, Scenario 5 bởi Read/Interference. Kê đơn "thêm memory" cho cả ba sẽ chỉ fix được một trong ba.
So sánh với benchmark trước
Benchmark hiện có như LongMemEval, LoCoMo, MemoryArena đánh giá memory nhưng đều treat reliability như một điểm snapshot. AgingBench điền vào 4 khoảng trống:
Longitudinal aging curves: đo half-life, decay slope, hazard proxy - thay vì một con số accuracy.
Cross-session dependencies: version chains (fact mới thay fact cũ), dependency edges (probe đòi hỏi tổng hợp từ nhiều session), interference pairs (entity gây nhầm lẫn).
Lifecycle event injection: inject maintenance events có kiểm soát - không benchmark nào trước đó làm điều này.
Component-aware diagnosis: counterfactual probes phân loại Write/Retrieval/Utilization stage - thay vì chỉ nói "agent sai".
Ai nên dùng AgingBench?
AgingBench phù hợp nhất cho:
Engineer deploy production agent: thay vì nhận generic failure score, bạn biết chính xác sửa ở giai đoạn nào trong pipeline (write, retrieval, hay utilization).
System architect chọn model: không có model nào dominant mọi aging mechanism - chọn dựa trên deployment pressure cụ thể của bạn (agent tracking budget vs agent quản lý codebase).
Team enterprise triển khai long-lived workflow: đo maintenance aging trước khi roll out - biết trước prompt update hoặc memory recompaction sẽ ảnh hưởng thế nào.
Code open source tại AgingBench.github.io, kèm per-run aging-curve data và extendable scenario manifest.
Kết: Reliability không phải snapshot
AgingBench đặt ra một câu hỏi quan trọng mà ngành vẫn chưa có câu trả lời đầy đủ: agent của bạn sẽ hoạt động được bao lâu sau khi deploy? Không phải "model này đạt bao nhiêu điểm benchmark" - mà là "sau 50 session, 100 session, agent còn đáng tin cậy không?"
Benchmark tốt nhất là "day-one" vẫn cần thiết, nhưng chưa đủ để deploy production. Bước tiếp theo của lĩnh vực là kết nối diagnostic vocabulary này với production telemetry thực tế - và AgingBench đang đặt nền móng cho hướng đó. via arXiv 2605.26302
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ