
- 9 lớp kiến trúc từ frontend đến GPU quyết định liệu agent của bạn có chạy ổn định ở production hay mãi stuck trong vòng lặp.
- LangChain đạt 5/10 DX trong benchmark 90 ngày của Nextbuild, PydanticAI dẫn đầu 8/10 và bắt được 23 production bugs LangChain bỏ sót.
- CrewAI không có token budget cap mặc định - một run uncapped trên Gemini đã tốn $414.
- McKinsey 2025: 62% doanh nghiệp đang thử nghiệm AI agents, 23% đã scale ở ít nhất một chức năng.
TL;DR
Xây dựng AI agent không chỉ là chọn đúng LLM. Đằng sau mỗi agent hoạt động tốt ở production là 9 lớp kiến trúc riêng biệt, từ giao diện người dùng đến phần cứng GPU. Hiểu rõ stack này giúp bạn chọn đúng tool, tránh bẫy chi phí, và không phải build lại từ đầu khi scale.
- 62% doanh nghiệp đang thử nghiệm AI agents (McKinsey 2025, khảo sát 1,993 tổ chức tại 105 quốc gia)
- PydanticAI tiết kiệm hơn CrewAI ~64% trong benchmark 90 ngày ($390 vs $1,088 tổng chi phí)
- Một CrewAI run uncapped trên Gemini đã tốn $414 trong 1 lần chạy duy nhất
- Snowflake thêm organizational ontology vào agent: accuracy tăng 20%, tool calls giảm 39%
AI agent không phải chatbot - đây là sự khác biệt
Chatbot trả lời. Agent hành động. Sự khác biệt đó tạo ra toàn bộ độ phức tạp của tech stack bên dưới.
Giai đoạn AutoGPT-style (agent loop hoàn toàn tự chủ) đã qua. Thực tế cho thấy các loop đó thường bị stuck, lặp lại task vô nghĩa, hoặc drift khỏi mục tiêu ban đầu vì thiếu grounding và termination logic. Năm 2025, pattern hiệu quả hơn là: agent có phạm vi hẹp, vai trò rõ ràng, và structured handoffs với con người hoặc agent khác.
Để xây được loại agent đó, bạn cần hiểu 9 lớp bên dưới.
9 lớp kiến trúc - từ UI đến GPU

Mỗi lớp giải quyết một vấn đề cụ thể. Không cần dùng hết cùng lúc - hiểu để chọn đúng:
- Frontend (Streamlit, Gradio, Next.js): giao diện kết nối user với AI brain. Streamlit cho internal dashboard, Next.js cho production copilot.
- Memory (Zep, Mem0, Letta): không có lớp này, agent của bạn là "con cá vàng" - quên hết sau mỗi turn. Memory phân thành episodic (short-term) và semantic (long-term).
- Tools (Serper, Exa, Composio): biến agent từ conversational thành action-oriented. Composio kết nối Gmail, Notion, GitHub chỉ qua vài dòng code.
- Observability (Langfuse, Helicone, Arize): "Grafana cho AI pipelines" - trace từng bước chain-of-thought, đo latency, cost, phát hiện hallucination.
- Orchestration (LangChain, CrewAI, AutoGen, LlamaIndex): logic layer điều phối reasoning, planning, và tool usage.
- Models (GPT, Claude, Gemini, DeepSeek, Qwen): Claude cho long context, Gemini cho multimodal, DeepSeek cho cost optimization. Quan trọng: stack phải cho phép switch model, không lock-in.
- Database (Pinecone, Weaviate, Chroma, Supabase): external memory bank lưu embeddings. Pinecone: sub-33ms p99 latency; Weaviate: tìm nearest neighbors từ hàng triệu vectors trong vài milliseconds.
- Infra (Docker, Kubernetes): Docker đảm bảo reproducibility, K8s quản lý traffic spikes ở production.
- GPU/CPU Providers (Azure, AWS, Groq, RunPod): RunPod cho fine-tuning, AWS Lambda cho inference scaling.
Framework nào phù hợp với bạn?
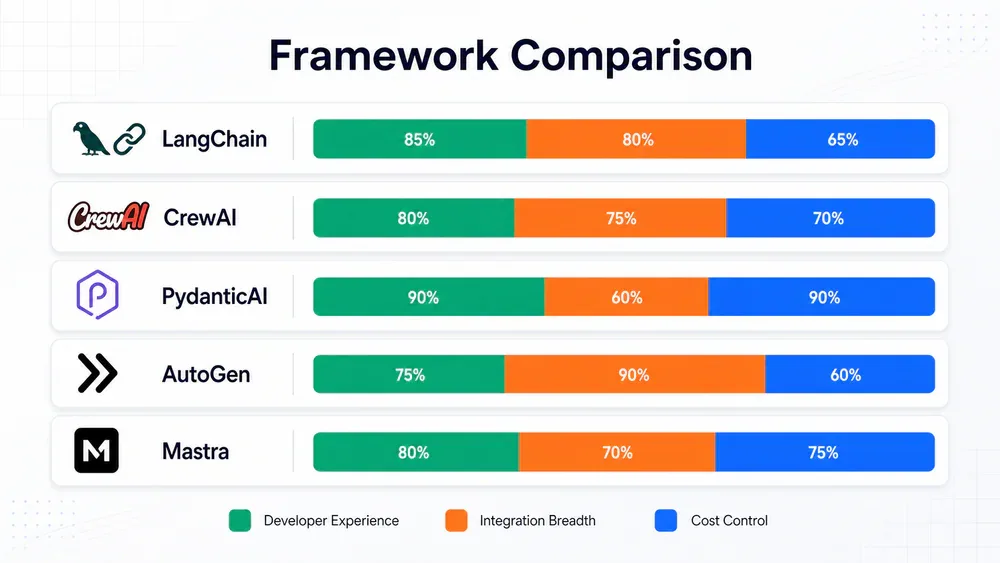
Lớp Orchestration là nơi quyết định quan trọng nhất. Dữ liệu từ benchmark 90 ngày của Nextbuild (2025):
| Framework | DX Score | Best for | Rủi ro chính |
|---|---|---|---|
| LangChain | 5/10 | 1,000+ integrations, RAG pipelines phức tạp | ConversationBufferMemory unbounded, debug khó |
| CrewAI | - | Role-based multi-agent (PwC, IBM, PepsiCo dùng) | Không có token cap - risk $414/run |
| PydanticAI | 8/10 | Type-safe, cost-controlled single-agent | Ecosystem nhỏ hơn LangChain 15x |
| AutoGen | - | Human-in-the-loop, conversational multi-agent | MCP integration cần thêm custom work |
| Mastra | - | TypeScript teams, serverless-first | Auth vẫn experimental, chưa có SOC 2 |
Nguyên tắc quan trọng: LlamaIndex và LangChain thường dùng kết hợp - LlamaIndex làm retrieval layer (tìm đúng tài liệu), LangChain làm orchestration layer bên trên. Hai tool này bổ sung nhau hơn là thay thế nhau.
Một insight đáng chú ý từ Snowflake: thêm organizational ontology vào agent (không đổi framework) giúp accuracy tăng 20% và giảm 39% số lần gọi tool. Context layer quan trọng hơn framework choice.
Bẫy chi phí cần biết trước
Ba rủi ro phổ biến nhất khi deploy AI agent lên production:
- Token loop không có cap: CrewAI và LangGraph không có built-in token budget limiter. Một experiment 2-agent trên Gemini đã reach $414 trong 1 run. Luôn set
max_iterstrước khi deploy. - Memory overflow im lặng: LangChain
ConversationBufferMemorykhông có token limit - mặc định trong dev, "silent failure" trong production khi conversation đủ dài để overflow context window. - Chi phí ẩn của automation: Mastra Observational Memory chạy background LLM calls qua Gemini 2.5 Flash để nén hội thoại - chi phí đó không hiện trong token usage report của agent. 5-40x compression, 95% LongMemEval score - nhưng phải biết để không bị surprise trên billing.
So sánh chi phí 90 ngày thực tế: PydanticAI $390 tổng (infra $240 + Temporal Cloud $150), CrewAI $1,088 - chênh lệch gần 3 lần cho cùng loại workflow.
Kết - chọn vì kiểm soát, không vì hype
Theo McKinsey State of AI 2025, blocker số 1 khi scale AI agents không phải là chọn framework sai - mà là unreliable performance (32% teams cite). Framework chỉ là phương tiện. Những gì thực sự quan trọng:
- Context layer tách biệt khỏi framework (dùng MCP hoặc external API) - khi bạn migrate framework, context không bị mất
- Observability từ ngày đầu (Langfuse, Promptfoo) - agent không debug được là agent không thể tin tưởng
- Model strategy linh hoạt - stack phải cho phép switch model, fallback, mixed-provider workflows
- Token budget control từ config, không phải afterthought
Thomson Reuters build CoCounsel (legal AI assistant) bằng Vercel AI SDK với 3 developers trong 2 tháng. Netguru build Omega (Slack agent tích hợp HubSpot + Salesforce + Google Drive) bằng AutoGen. Stack tốt không cần phức tạp - cần đúng.
via LearningLM · Netguru · Speakeasy
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ