
Xây Eval Dataset Hiệu Quả cho LLM: Bắt Đầu Từ Đâu và Dùng Công Cụ Gì (Phần 2)
Dataset tốt là dataset mirror được production - nếu pass dataset bạn tự tin deploy, nó đang làm đúng việc. Bắt đầu với 10-20 ví dụ curate thủ công; với từng component riêng lẻ thì 5-10 là đủ. 3 nguồn dữ liệu theo thứ tự: production traces, hand-written cases, sau đó mới generate synthetic bằng AI. Sau dataset là experiments - đo impact từng thay đổi trước khi deploy.
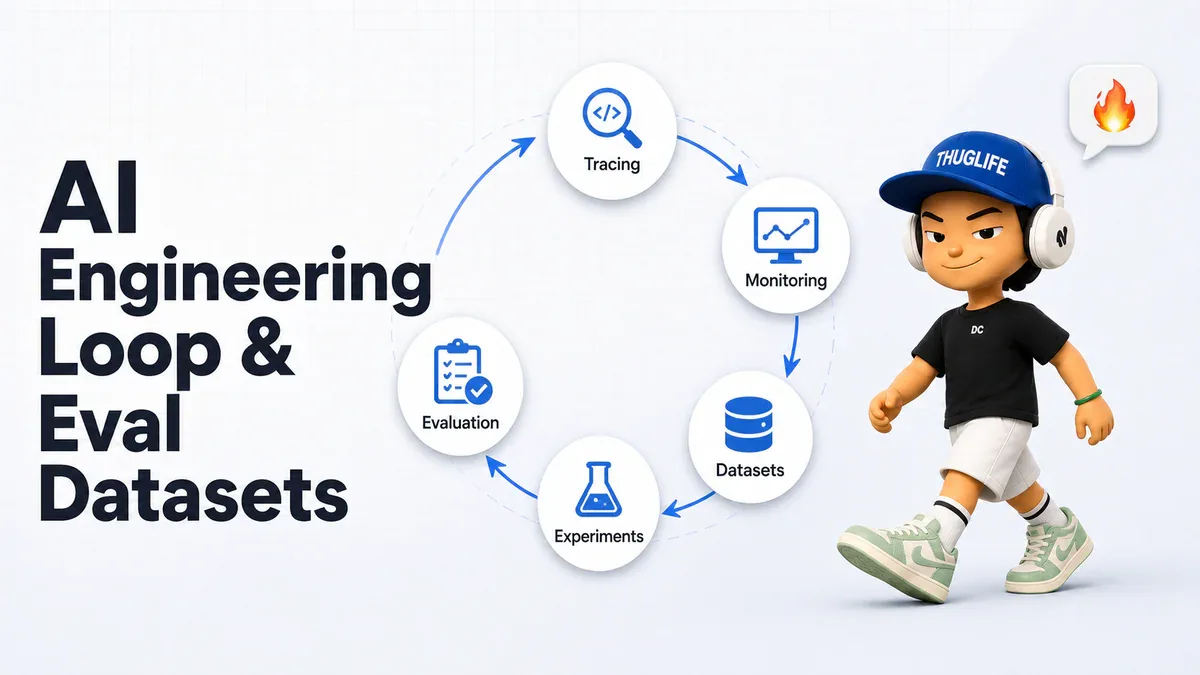
AI Engineering Loop và Cấu Trúc Eval Dataset cho Ứng Dụng LLM (Phần 1)
AI Engineering Loop là vòng lặp liên tục kết nối production monitoring với development có hệ thống - dataset là mắt xích trung tâm. Mỗi dataset item gồm 3 trường: Input bắt buộc, Expected output tùy chọn, và Metadata tùy chọn. Reference-based evaluators yêu cầu ground truth và chỉ dùng được ở offline; reference-free evaluators chạy được cả online lẫn offline. Hiểu đúng cấu trúc này là nền tảng để xây hệ thống eval không đoán mò.

Thiết kế Eval Dataset cho LLM - Nền tảng của vòng lặp AI Engineering
Eval dataset là tập test case giúp kiểm tra hệ thống LLM có hệ thống trước khi deploy, thay thế chiến lược deploy-and-hope-for-the-best. Mỗi dataset item gồm 3 trường: Input (bắt buộc), Expected output và Metadata (tùy chọn). Langfuse giảm CLI error rate từ 25% xuống 0% chỉ bằng cách thêm một instruction rõ ràng - phát hiện nhờ dataset và experiments. 57% tổ chức đã có AI agents trong production (LangChain 2026), và quality là rào cản số 1 với 32% đội nhóm.