
- Prompt injection đạt 100% tỷ lệ thành công - guardrail tầng ngôn ngữ không đủ để bảo vệ AI agent trong doanh nghiệp.
- Anthropic phát hành framework Zero Trust 3 tầng với quy trình triển khai 8 bước: từ cryptographic identity đến behavioral monitoring.
- 250 malicious documents đủ để backdoor LLM 13 tỷ tham số; kỹ thuật Spotlighting giảm indirect injection từ trên 50% xuống dưới 2%.
TL;DR
Anthropic vừa phát hành eBook "Zero Trust for AI Agents" - framework bảo mật toàn diện để triển khai AI agent tự động trong doanh nghiệp. Quan điểm cốt lõi: guardrail ở tầng ngôn ngữ tự nhiên không còn đủ - kẻ tấn công có thể jailbreak mọi prompt-level control. Giải pháp là kiểm soát ở tầng infrastructure với ba nguyên tắc: trust nothing, verify everything, assume breach has already occurred.
Tại sao guardrail truyền thống không đủ
AI agent hoạt động hoàn toàn khác so với phần mềm truyền thống. Thay vì chạy logic cố định, agent diễn giải mục tiêu mơ hồ, tự chọn tool, và thực thi chuỗi hành động nhiều bước mà không cần human review ở mỗi bước. Điều đó có nghĩa là: một agent bị thao túng có thể gây hại ở tốc độ máy tính - nén timeline tấn công từ tháng xuống còn giờ, thậm chí giây.
Vấn đề căn bản hơn là LLM không thể phân biệt đáng tin cậy giữa "thông tin bình thường" và "lệnh có thể thực thi". Bất kỳ guardrail nào hoạt động ở tầng ngôn ngữ đều có thể bị vượt qua qua encoding (Base64, hex) hoặc adversarial suffix. Anthropic thẳng thắn thừa nhận: model layer alone cannot secure agentic AI.
5 mối đe dọa đặc thù của agentic AI
OWASP đã phân loại các mối đe dọa chính với agentic systems:
- Prompt Injection: Nghiên cứu cho thấy các phương pháp algorithmic đạt 100% tỷ lệ thành công với direct injection, có thể transfer across multiple model families. Indirect injection - nhúng lệnh độc hại vào web page, email, tài liệu - còn nguy hiểm hơn: theo nghiên cứu của Google DeepMind, simple content injection hijack thành công đến 86% scenarios.
- Tool poisoning & chaining: Kẻ tấn công cấy lệnh vào MCP tool descriptor để agent gọi tool với hành vi không mong muốn. Tool chaining kết hợp nhiều tool hợp lệ theo cách nguy hiểm - ví dụ: CRM tool kết hợp email tool để exfiltrate toàn bộ data khách hàng, mà không tool nào expose dữ liệu đó một mình.
- Identity & privilege abuse: Manager agent delegate full access xuống worker agent mà không giới hạn scope (unscoped privilege inheritance). Hoặc agent cache credentials từ session cũ và thực thi request với quyền leo thang - tấn công escalate privilege across session boundaries.
- Memory poisoning: RAG poisoning, shared context poisoning, long-term memory drift. Khác với tấn công đơn lẻ, memory poisoning persist across sessions - agent tiếp tục phục vụ mục tiêu kẻ tấn công lâu sau khi injection ban đầu.
- Supply chain: Anthropic research chứng minh chỉ cần 250 malicious documents là đủ để backdoor LLM từ 600 triệu đến 13 tỷ tham số, và backdoor này persist qua cả supervised fine-tuning lẫn RLHF.
Framework 3 tầng Zero Trust
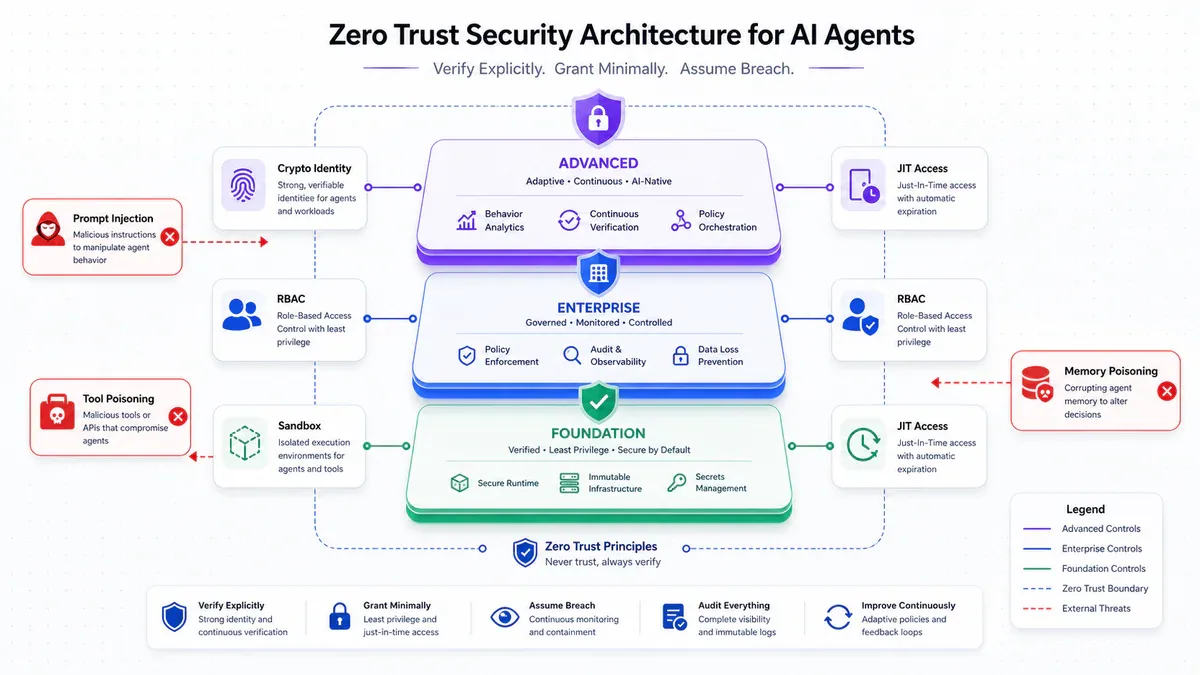
Framework được tổ chức thành ba tầng theo mức độ trưởng thành của tổ chức:
- Foundation: Điểm vào tối thiểu mà mọi tổ chức đều phải đạt. Bao gồm: cryptographic identity cho mỗi agent instance, short-lived tokens thay thế static API key, RBAC deny-by-default, identity-based isolation, và input isolation cơ bản.
- Enterprise: Target của phần lớn tổ chức có deployment thực sự. Thêm: certificate-based authentication, ABAC với context-aware policies, sandboxed execution environments (gVisor, container), constitutional classifiers, immutable audit trails.
- Advanced: Baseline cho tổ chức có high-risk deployment. Hardware-backed identity (HSM/TPM), JIT access tự động expire, hardware isolation (AMD SEV/Intel TDX), ML-based behavioral analysis.
Hai khái niệm mới nổi bật trong framework: Least Agency - mở rộng least privilege sang agentic context, giới hạn chính xác từng tool có thể làm gì, bao nhiêu lần, và ở đâu. Blast radius - agent có read-only access vào 1 database có blast radius nhỏ; agent có admin access vào cloud infrastructure có blast radius khổng lồ. Security investment cần match mức exposure đó.
8 bước triển khai thực tế
- Identify requirements - Align security, legal, compliance, và business stakeholders trước khi build
- Manage supply chain - AI-BOM để track model provenance, OpenSSF Scorecard cho dependency health, cryptographic signing ở mọi stage
- Define agent boundaries - Unique crypto identity cho mỗi agent, document approved/prohibited actions, xác định blast radius
- Defend against prompt injection - Input isolation, constitutional classifiers (block 95% jailbreak attempt trong testing), Spotlighting giảm indirect injection từ >50% xuống <2%
- Secure tool access - Tool allow-listing, capability restrictions, parameter validation, sandboxed execution, approval escalation cho high-risk action
- Protect credentials - Short-lived tokens từ identity provider, credential isolation, hardware-bound credentials cho production, JIT access
- Safeguard memory - Session isolation, context integrity validation bằng cryptographic hash, retention policies với TTL tự động expire
- Measure what matters - Dwell time (anomaly đến human awareness), detection speed, explainability, behavioral conformance baselines
Ai nên quan tâm ngay
Các ngành regulated - y tế, tài chính, chính phủ - chịu áp lực compliance trực tiếp: HIPAA, FINRA, GDPR, FedRAMP, EU AI Act đều có yêu cầu align với Zero Trust. Chính phủ Mỹ yêu cầu tất cả cơ quan liên bang phải adopt Zero Trust architecture vào 2027.
Nhưng framework này không chỉ dành cho regulated industries. Bất kỳ tổ chức nào đang deploy AI agent - từ coding agent, customer service agent, đến research agent - đều cần đánh giá lại model bảo mật hiện tại. Như Anthropic nhấn mạnh: retrofitting controls after an incident costs more than building them now.
Bài test nhanh để tự đánh giá: "Impossible vs. Tedious" - kiểm soát hiện tại tạo ra barrier thực sự (impossible), hay chỉ thêm friction (tedious)? AI agent có unlimited patience và near-zero per-attempt cost. Mọi control chỉ dựa trên friction - rate limit, non-standard port, SMS MFA - đều không đủ trước attacker chạy agent.
Nhìn về phía trước
Anthropic nêu rõ: mọi capability trong framework đều tồn tại hôm nay, nhưng tooling và enterprise adoption vẫn đang trưởng thành. Advanced tier được kỳ vọng trở thành Enterprise standard trong tương lai gần - và Enterprise sẽ trở thành Foundation mới.
Framework tích hợp nhiều reference đến Claude Code - Anthropic đang build security-first mindset vào chính developer tool của mình: sandboxed execution, explicit permission control qua settings.json, OAuth 2.0 với automatic token refresh cho MCP connections, session isolation mặc định.
Tải eBook đầy đủ (34 trang) tại via Anthropic hoặc đọc tóm tắt tại via Claude Blog.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ