
- WhisperX đạt tốc độ 70x real-time với large-v2 nhờ batched inference và VAD Cut & Merge, nhanh hơn Whisper gốc 11.8 lần trên benchmark chính thức.
- Timestamp word-level chính xác ±50ms, so với ±500ms của Whisper - cải thiện 10 lần.
- DER ~8% trong điều kiện chuẩn, tích hợp pyannote-audio để phân biệt từng người nói.
- Miễn phí hoàn toàn, BSD-2-Clause license, 21.8k GitHub stars.
TL;DR
WhisperX là pipeline ASR mã nguồn mở xây trên Whisper của OpenAI, ra mắt tại Interspeech 2023. Thay vì cải tiến model gốc, nó bổ sung 3 lớp kỹ thuật: VAD Cut & Merge để batched inference (70x nhanh hơn), forced phoneme alignment qua wav2vec2 (timestamp ±50ms), và speaker diarization qua pyannote-audio. Phiên bản hiện tại v3.8.5, BSD-2-Clause license, hoàn toàn miễn phí.
Vấn đề với Whisper gốc
OpenAI Whisper là model nhận dạng giọng nói xuất sắc - nhưng có 3 hạn chế lớn khi dùng thực tế:
Chậm: xử lý tuần tự, không tận dụng được batch inference trên GPU
Timestamp thô: chỉ có timestamp ở cấp độ câu/đoạn, không biết từng từ bắt đầu/kết thúc lúc nào
Không biết ai nói: output là transcript thuần, không phân biệt SPEAKER_00, SPEAKER_01
WhisperX giải quyết cả 3 vấn đề này mà không cần thay thế Whisper - nó wrap Whisper thành một pipeline hoàn chỉnh hơn.
Kiến trúc pipeline
WhisperX hoạt động theo 4 bước tuần tự:
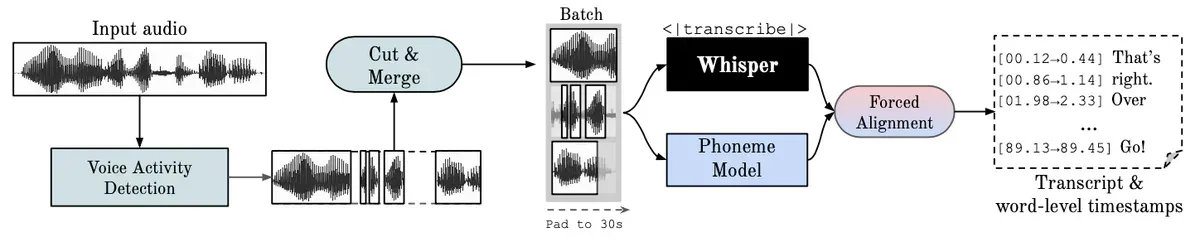
Pipeline WhisperX: VAD phát hiện vùng có tiếng nói, Cut & Merge tách thành chunk ~30s, Whisper transcribe song song, Forced Alignment gán timestamp từng từ
Voice Activity Detection (VAD): tiền xử lý audio, đánh dấu vùng có tiếng nói và im lặng
Cut & Merge: tách audio thành các chunk 15-30 giây tại điểm im lặng, không cắt giữa chừng câu nói
Batched Whisper: các chunk được đưa vào Whisper song song thay vì tuần tự - đây là nguồn gốc của speedup 70x
Forced Phoneme Alignment: dùng wav2vec2 + Dynamic Time Warping để căn chỉnh transcript với audio ở cấp độ từng âm tiết, rồi map ngược ra từng từ
Bước tùy chọn thứ 5 là Speaker Diarization qua pyannote-audio: sau khi có transcript với word timestamps, hệ thống map từng đoạn sang speaker ID tương ứng.
Con số đáng chú ý
Từ paper Interspeech 2023 và benchmark cộng đồng:
Tốc độ: 70x real-time với large-v2, 11.8x so với vanilla Whisper trên cùng phần cứng
Word timestamp: ±50ms độ chính xác, so với ±500ms của Whisper gốc (cải thiện 10 lần)
WER: TED-LIUM giảm từ 10.5% xuống 9.7%; MLPerf 2025 đạt 4.8% vs 12.5% vanilla Whisper
Word precision: 85.4% → 93.2% trên Switchboard corpus (+9.2%)
Diarization Error Rate (DER): ~8% trong điều kiện chuẩn; WDER 2.68% cho 2 người, 11.65% cho 3 người
GPU memory: dưới 8GB VRAM cho large-v2 với beam_size=5
Subtitle gen: video 30 phút → SRT hoàn chỉnh trong 1-3 phút
Ai nên dùng ngay
WhisperX phù hợp nhất với các use case sau:
Podcast producer: transcript tự động với nhãn người nói, xuất SRT/VTT, không cần chỉnh thủ công "ai nói gì"
Video creator: subtitle gen với word-level timing để làm karaoke-style caption, sync chính xác từng từ
Meeting recorder: ghi lại cuộc họp Zoom/Teams/Meet với speaker attribution đầy đủ
Researcher / linguist: forced alignment chính xác ở cấp âm tiết, dùng cho phonetics annotation
Developer: tích hợp vào pipeline với Python API hoặc CLI, output JSON/SRT/VTT/TSV
WhisperX không phải lựa chọn tốt khi audio có nhiều người nói đồng thời (overlapping speech làm DER tăng 15-20%), hoặc khi cần transcribe ngôn ngữ không có sẵn wav2vec2 model.
Bắt đầu trong 3 bước
Cài đặt:
pip install whisperx
# hoặc
uvx whisperxTranscribe cơ bản:
whisperx audio.wav --model large-v2Với diarization (cần HuggingFace token):
whisperx audio.wav \
--model large-v2 \
--diarize \
--hf_token YOUR_HF_TOKENOutput format mặc định là .srt. Thêm --output_format json để lấy word-level timestamps dạng JSON cho downstream processing.
Lưu ý: CUDA 12.8 cần cho GPU trên Linux/Windows. CPU mode dùng --compute_type int8 nhưng chậm hơn đáng kể.
Hạn chế và lưu ý
Overlapping speech: khi 2 người nói cùng lúc, DER tăng 15-20% - đây là hạn chế lớn nhất
Non-dictionary characters: số, ký tự đặc biệt không có phoneme tương ứng, bị bỏ qua trong alignment
Translation mode: tắt forced alignment vì audio và text không match phonetically
HuggingFace setup: diarization yêu cầu accept license của 3 model riêng biệt trên HuggingFace
Language coverage: alignment đầy đủ cho 5 ngôn ngữ (EN, FR, DE, ES, IT); 30+ ngôn ngữ khác qua HuggingFace nhưng chất lượng không đồng đều
Kết
WhisperX không thay thế Whisper - nó biến Whisper thành một công cụ production-ready. Nếu bạn đang dùng Whisper gốc và gặp vấn đề về tốc độ, timestamp không chính xác, hoặc cần phân biệt người nói, WhisperX là bước nâng cấp rõ ràng nhất với zero cost.
21.8k GitHub stars sau 2 năm và vẫn được maintain tích cực là tín hiệu tốt. Version v3.8.5 (tháng 4/2026) cho thấy project vẫn trong trạng thái phát triển.