
- Nous Research ra mắt Lighthouse Attention - tăng tốc forward pass 21× tại 512K context trên single B200 mà không đổi deployed model.
- Token Superposition Training cắt 2.5× thời gian pretraining 10B-A1B MoE từ 12,311 xuống 4,768 GPU-hours.
- AI Co-Mathematician của Google DeepMind đạt 48% FrontierMath Tier 4, SOTA mới, và đã giúp giải bài toán nhóm mở suốt 60 năm.
- The Memory Curse cho thấy context window lớn hơn làm giảm khả năng hợp tác của LLM agents trong 18/28 cài đặt thử nghiệm.
TL;DR
Tuần May 11-17 là một tuần bội thu với 10 papers đáng chú ý. Nổi bật nhất là Nous Research - trong một tuần ra mắt hai kỹ thuật pretraining độc lập: Lighthouse Attention (training-only attention wrapper, 21× nhanh hơn tại 512K context) và Token Superposition Training (cắt 2.5× thời gian pretraining mà không đụng đến architecture). Google DeepMind ra mắt AI Co-Mathematician đạt 48% FrontierMath Tier 4 và giải bài toán nhóm mở suốt 60 năm. Hai papers khác thách thức assumption phổ biến: context window lớn hơn có thể hại multi-agent cooperation, và grep thường đánh bại vector search trong coding agents.
Nous Research: Hai kỹ thuật training trong một tuần
Đây là điều hiếm gặp: cùng tác giả Bowen Peng và Jeffrey Quesnelle publish hai papers pretraining độc lập trong cùng ngày 7 May 2026.
Lighthouse Attention
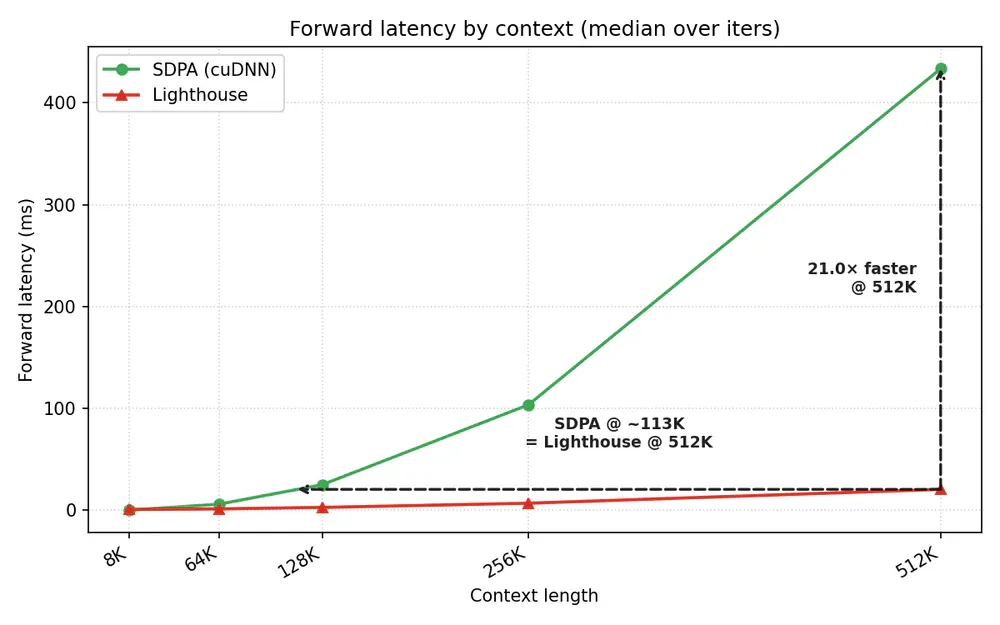
Vấn đề cốt lõi: Attention có chi phí O(N²) - training với 512K token context cực kỳ tốn kém. FlashAttention cải thiện memory footprint nhưng không giảm compute quadratic scaling.
Cách tiếp cận: Lighthouse Attention là training-only wrapper quanh SDPA thông thường. Điểm khác biệt so với NSA, HISA, MoBA là nó pool cả Q, K, V symmetrically qua multi-level pyramid - đưa compute cost từ O(N·S·d) xuống O(S²·d). Selection chạy ngoài attention kernel nên vẫn dùng stock FlashAttention trên dense sub-sequence. Sau khi training gần xong, wrapper bị loại bỏ hoàn toàn và deployed model chạy vanilla SDPA bình thường - không có deployment overhead.
Kết quả thực tế (530M model, ~50.3B tokens, 98K context):
- Forward pass tại 512K context: 21× nhanh hơn SDPA trên single B200
- End-to-end pretraining wall-clock: 1.4-1.69× nhanh hơn
- Final loss tốt hơn: 0.698-0.710 vs baseline 0.724
- Scales đến 1M token context trên 32 Blackwell GPUs (4 nodes, CP degree 8)
Token Superposition Training (TST)
TST đặt câu hỏi: có thể tăng data throughput per FLOP mà không đổi tokenizer, optimizer hay architecture không? Câu trả lời là có.
Phase 1 (Superposition): Model nhận "bags" gồm s token liền nhau (average embeddings thành 1 latent token), train với multi-hot cross-entropy. Phase 2: revert về next-token prediction bình thường từ checkpoint đó. Deployed model giống hệt model train theo cách truyền thống.
- 10B-A1B MoE: 4,768 B200-GPU-hours vs baseline 12,311 (~2.5× tiết kiệm), loss thấp hơn
- HellaSwag: 71.2 vs 70.1; ARC-Challenge: 47.3 vs 46.3; MMLU: 39.0 vs 37.4
- 3B dense: 247 vs 443 GPU-hours (~1.8×), loss xấp xỉ nhau
Lưu ý: TST phù hợp khi compute-bound. Nếu data-bound (data ít), standard baseline thắng vì Phase 1 dùng s× nhiều token hơn.
Google DeepMind: AI giải bài toán nhóm mở 60 năm
AI Co-Mathematician là workbench đa agent bất đồng bộ hỗ trợ nghiên cứu toán học. Không phải chatbot - mà là môi trường có trạng thái: coordinator agent phân công các workstream chạy song song (literature search, proof attempt, code experiment), tự track failed hypotheses, và output mathematical artifacts có thể verify được.
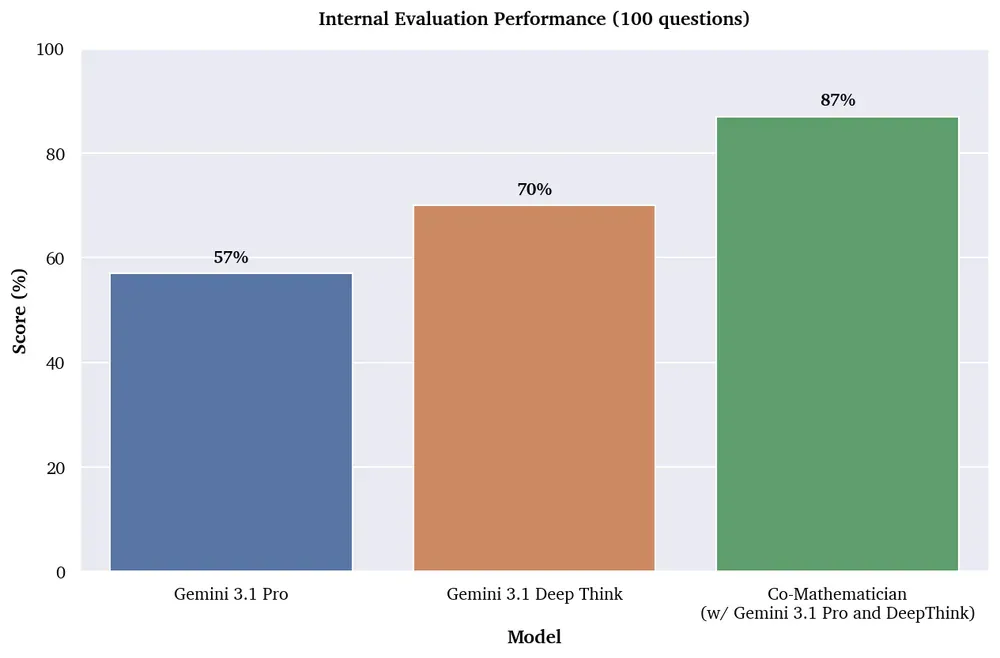
Benchmark chính: 48% FrontierMath Tier 4 - mức cao nhất từ trước đến nay trong tất cả AI systems được đánh giá. Gemini 3.1 Pro baseline chỉ đạt 19% trên cùng benchmark này.
Ứng dụng thực tế: Giáo sư Marc Lackenby (Oxford) dùng hệ thống để giải Problem 21.10 từ Kourovka Notebook - bài toán nhóm tồn tại chưa giải suốt 60 năm. Reviewer agent nội bộ phát hiện lỗi trong draft proof đầu tiên; Lackenby nhận ra gap và biết cách vá. Kết quả được publish.
Giới hạn: tốn compute hơn single model call; có thể xảy ra reviewer-pleasing bias và non-terminating review loops; LaTeX đẹp có thể che đi reasoning yếu.
Hai phát hiện thách thức assumption phổ biến
The Memory Curse: Context window lớn hơn có thể hại multi-agent systems
Nghiên cứu của Jiayuan Liu và 9 đồng tác giả thử nghiệm 7 LLMs, 4 trò chơi social dilemma, 500 rounds. Kết quả: mở rộng history window làm giảm hợp tác trong 18/28 cài đặt model-game. Nguyên nhân không phải agents trở nên nghi ngờ nhau hơn - mà là forward-looking intent bị xói mòn. Agents đọc quá nhiều lịch sử nên reasoning về quá khứ thay vì tương lai. Phân tích trên 378,000 reasoning traces xác nhận điều này.
Đáng ngạc nhiên hơn: Chain-of-Thought amplifies the curse thay vì cải thiện. Mitigation: memory sanitization (thay visible history bằng synthetic cooperative records) hoặc LoRA fine-tuned trên forward-looking traces - cả hai đều transfer zero-shot sang games khác.
Is Grep All You Need? Vector search không phải luôn tốt hơn
So sánh grep vs embedding retrieval trong coding agents (116 câu từ LongMemEval, 4 harnesses: Chronos, Claude Code, Codex, Gemini CLI). Grep thường đạt accuracy cao hơn hoặc bằng vector retrieval. Insight quan trọng hơn: harness design là biến quan trọng nhất - không phải retrieval method. Cùng data, khác harness, hiệu suất thay đổi rõ rệt. Vector database là mặc định phổ biến trong coding agent stacks, nhưng có thể đang được overrated.
Các papers đáng chú ý khác
- A Geometric Calculator (Goodfire): Phát hiện cơ chế arithmetic bên trong LLM - số được mã hóa như circles trên activation space, phép cộng là rotation. Circuit tương tự xuất hiện cả trong non-math contexts.
- δ-mem: Augment frozen full-attention model bằng delta-rule memory state (không cần fine-tuning). 8×8 state tăng average score 1.10× và đánh bại memory baseline mạnh nhất 1.15×.
- AEvo: Tách self-improvement loop thành proposer + meta-agent. 26% gain so với evolution baseline; tận dụng accumulated search logs cho procedure-level updates.
- AutoTTS: Tự động tìm kiếm test-time scaling strategies. Discovered controllers vượt hand-designed recipes với chi phí $39.9 và 160 phút.
- Beyond Individual Intelligence: Survey 200+ papers multi-agent systems theo 3 axes: collaboration mechanisms, failure attribution, self-evolution.
Nhận định
Điểm nổi bật nhất tuần này là Nous Research - publish hai kỹ thuật pretraining độc lập trong cùng một ngày, cả hai đều không yêu cầu thay đổi architecture hay deployed model. Đây là kiểu research thực dụng: không có deployment tax, ai cũng có thể thử. Token Superposition Training đặc biệt thú vị vì concept đơn giản đến mức đáng ngờ nhưng works consistently từ 270M đến 10B.
The Memory Curse là nhắc nhở quan trọng khi thiết kế multi-agent systems: "context lớn hơn = tốt hơn" là assumption nguy hiểm. Content trong memory mới là yếu tố quyết định, không phải độ dài.
via DAIR.AI · Papers: Lighthouse Attention · Token Superposition Training · AI Co-Mathematician · Memory Curse · Is Grep All You Need?
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ