
- Google Research vừa công bố S2Vec — foundation model thứ ba trong bộ Earth AI.
- Không cần ảnh vệ tinh, không cần nhãn tay, mô hình học cách 'đọc' khu phố từ các pixel bản đồ rồi dự đoán dân số, thu nhập, phát thải CO₂ ở những vùng chưa từng thấy — đạt R² 0.72 khi fuse với RS-MaMMUT.
TL;DR
S2Vec là foundation model mới của Google Research, công bố trên blog Research ngày 24/03/2026 (paper arXiv 2504.16942). Nó biến built environment — toà nhà, đường, điểm bán cà phê, trạm bus — thành ảnh nhiều lớp rồi dùng masked autoencoding học cách điền vào vùng bị che. Đầu ra là embedding 256-chiều cho mọi vị trí trên Trái đất. Trên zero-shot extrapolation (dự đoán cho vùng chưa từng thấy), S2Vec đạt R² 0.64 cho dân số và 0.45 cho median income; fuse với RS-MaMMUT lên 0.72, vượt mọi baseline ảnh vệ tinh.
What's new
Cách tiếp cận truyền thống của geospatial ML là hand-craft chỉ số cho từng bài toán: dự đoán không khí thì tự xây feature set, dự đoán giá nhà lại xây bộ khác. S2Vec thay tất cả bằng một biểu diễn đa năng (task-agnostic) chuyển sang được nhiều nhiệm vụ.
Quy trình gồm ba bước:
- Phân vùng bằng S2 Geometry — dùng thư viện S2 của Google chia Trái đất thành lưới ô phân cấp. Cell level-12 phủ ~5 km², cell level-8 phủ ~1300 km². Mỗi ảnh đầu vào là grid 16×16 = 256 patch cells.
- Rasterize feature thành ảnh — mỗi cell có một vector 116 chiều: 115 counts cho các danh mục POI (cà phê, pharmacy, công viên...) + 1 count cho đường. Vector này trở thành 'pixel' nhiều kênh trong ảnh built environment.
- Masked Autoencoding (MAE) — theo kiến trúc Vision Transformer, model bị che một phần patch và học cách tái tạo dựa vào ngữ cảnh. Thấy cụm cao tầng cạnh ga metro → đoán đâu đó có siêu thị. Làm hàng triệu lần trên toàn cầu, model tự học 'ngữ pháp không gian' của cách các thành phố tự tổ chức.
Không ai gán nhãn 'financial district' hay 'ngoại ô'. Model tự nhóm các khu đó dựa vào hình học của những gì được xây ở đâu.
Vì sao quan trọng
Dữ liệu training của S2Vec là map features, không phải pixel vệ tinh. Khác biệt này quan trọng vì ba lý do: map data cập nhật nhanh hơn, xử lý rẻ hơn, và bắt được hạ tầng ở độ phân giải mà ảnh vệ tinh không luôn làm được. Vệ tinh chỉ thấy mái nhà; S2Vec biết dưới đó có ba quán cà phê, một pharmacy, một trạm bus.
Số liệu kỹ thuật
| Thông số | Giá trị |
|---|---|
| Embedding dimension | 256 |
| Feature vector / cell | 116-dim (115 POI + 1 road) |
| Patch cell (level 12) | ~5 km² |
| Image cell (level 8) | ~1300 km², 16×16 patch |
| MAE backbone | ViT, 8 heads, 6 encoder / 2 decoder layers |
| Training hardware | 8× NVIDIA V100 GPUs, TensorFlow 2.0 |
| Optimizer | AdamW, lr 5e-4, weight decay 0.001 |
Benchmark trên ba dataset: California housing (~6,700 điểm), US population density (~47,000 điểm), US median income (~1,7 triệu điểm).
So sánh với baselines
Trên zero-shot geographic extrapolation (giữ lại toàn bộ miền Đông nước Mỹ làm test set, model chưa từng thấy), R² càng cao càng tốt:
| Method | Population R² | Median Income R² |
|---|---|---|
| S2Vec | 0.64 | 0.45 |
| RS-MaMMUT (vệ tinh) | 0.68 | 0.23 |
| GEOCLIP | 0.33 | 0.30 |
| SATCLIP | −0.6 (fail) | −7.24 (fail) |
| S2Vec + RS-MaMMUT (fusion) | 0.72 | 0.35 |
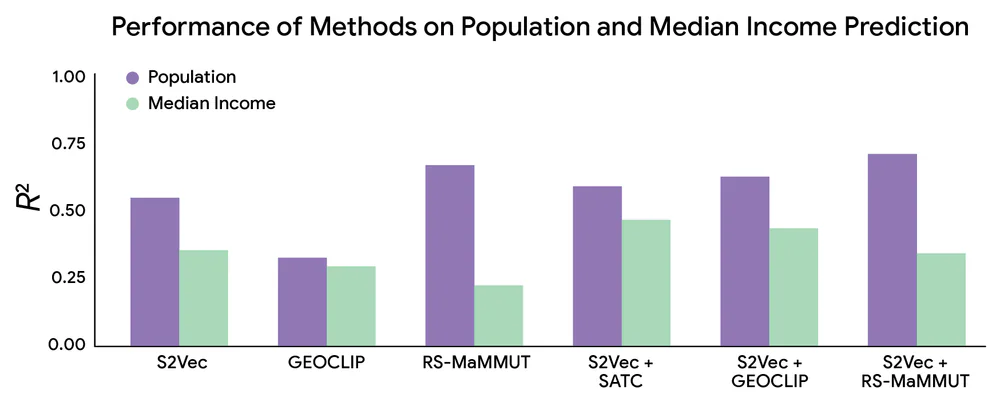
Đáng chú ý: S2Vec một mình vượt RS-MaMMUT trên median income (0.45 vs 0.23) dù RS-MaMMUT dùng ảnh vệ tinh RGB có embedding 1152-chiều. Fuse hai mode (phương pháp 'project-and-add') cho kết quả tốt nhất trên population.
Use cases
- Quy hoạch đô thị — mô phỏng tác động của thay đổi hạ tầng lên sức khoẻ khu phố, thu nhập, mật độ dân số.
- Nghiên cứu môi trường — ước tính carbon footprint cho các thành phố phát triển nhanh, kết hợp RS-MaMMUT cho cây xanh và độ cao.
- Bất động sản & retail — định giá nhà, chọn vị trí cửa hàng mà không cần tự xây feature riêng.
- Chính sách công — ước tính dân số / thu nhập ở các vùng thiếu census, đặc biệt ngoài Mỹ.
- ML engineers — một embedding dùng cho nhiều task thay vì hand-craft cho từng bài toán.
Hạn chế & khả dụng
- Environmental tasks yếu — độ phủ cây, độ cao, chỉ built-env data là không đủ. Phải fuse với RS-MaMMUT để bù tầm nhìn vệ tinh.
- Phụ thuộc vào location signal — trên median income, GEOCLIP (encode toạ độ trong pre-training) có thể nhỉnh hơn. S2Vec cần thêm variant S2Vec-Loc để thu hẹp khoảng cách.
- Overfitting khi fuse embedding lớn — gộp với RS-MaMMUT (1152-dim) trên dataset nhỏ như California housing (6,700 điểm) dễ quá khớp.
- Khả dụng & giá — S2Vec hiện là research release, paper licence CC BY-NC-SA 4.0, chưa có product thương mại đứng riêng. Model 'anh em' PDFM đã có sẵn dưới tên Population Dynamics Insights (Preview) trên Google Maps Platform theo hình thức subscription hoặc pay-as-you-go.
Earth AI pipeline
Google Earth AI giờ có ba foundation model chạy song song, bổ trợ nhau:
- PDFM — population dynamics: hành vi con người (Search trends, Maps popular times, air quality, weather) → embedding 330-dim, cập nhật hàng tháng ở S2 cell level 12.
- RS-MaMMUT — satellite imagery: vision-language model trên ảnh vệ tinh RGB, embedding 1152-dim.
- S2Vec — built environment: map features (POI, road network) → embedding 256-dim.
Stack cả ba, bạn có hệ thống đọc một khu phố theo cách dân địa phương hiểu nó — từ cấu trúc vật lý, hình ảnh chụp trên cao, đến hành vi con người.
What's next
Paper nêu rõ roadmap tiếp theo:
- Feature giàu hơn: thêm overhead building geometries, elevation profiles, mobility/traffic flow theo thời gian.
- Kiến trúc mới: thử graph transformer để mô hình hoá phụ thuộc giữa các cell lân cận tường minh hơn.
- Mở rộng sang entity khác: không chỉ grid cells mà cả POI, road network, vector geo data.
- Joint multi-channel MAE — thay vì late fusion, pre-train chung map features + ảnh vệ tinh trong một model duy nhất, học cross-modal từ đầu.
Nguồn: Google Research blog, arXiv 2504.16942, Google Earth AI, Google Maps Platform — PDI.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ