
- Model AI tốt nhất hiện tại (claude-opus-4-6 CoWork) chỉ đạt 4.17% trên Remote Labor Index, benchmark dùng 240 dự án Upwork thực tế trị giá hơn $140.000.
- 96% thất bại không phải vì task khó - các công việc đã được chia nhỏ và định nghĩa rõ ràng trước khi đưa vào test.
- Failure mode phổ biến nhất: file rỗng, file bị corrupt, và deliverable sai format.
- AI đang cải thiện - từ 2.5% lên 4.17% trong 4 tháng - nhưng human baseline vẫn gấp đôi mức tốt nhất của AI.
TL;DR
Remote Labor Index (RLI) là benchmark đo khả năng AI agent hoàn thành công việc remote có giá trị kinh tế thực. Được tạo bởi Scale AI và Center for AI Safety, RLI dùng 240 dự án Upwork thực tế - không phải bài test giả định - trị giá hơn $140.000. Kết quả tháng 5/2026: model tốt nhất (claude-opus-4-6 CoWork) chỉ đạt 4.17%. 12 model hàng đầu thế giới đều không vượt ngưỡng này. Phần còn lại - 95.83% - là thất bại.
RLI là gì và ai tạo ra nó
RLI (Remote Labor Index) là benchmark được Scale AI và Center for AI Safety (CAIS) công bố vào tháng 10/2025, với tác giả chính là Mantas Mazeika cùng 46 đồng tác giả, trong đó có Dan Hendrycks (CAIS) và Alexandr Wang (Scale AI).
Điểm khác biệt cốt lõi so với các benchmark thông thường: RLI dùng công việc thực tế từ Upwork, không phải bài test nhân tạo. Mỗi dự án trong bộ 240 tasks đều có brief thực, file đầu vào thực, và một deliverable "gold standard" do freelancer người thật đã hoàn thành. Tiêu chí đánh giá thẳng thắn: liệu một "reasonable client" có chấp nhận deliverable này không?
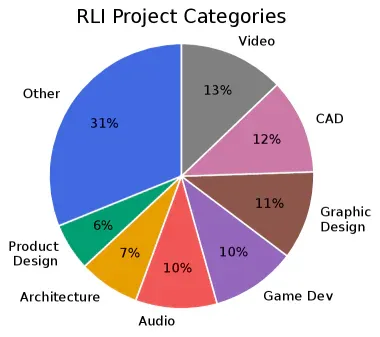
Phạm vi bao gồm 23 ngành nghề, trong đó nổi bật:
- Video production: 13%
- CAD & 3D modeling: 12%
- Graphic design: 11%
- Game development: 10%
- Audio: 10%
- Architecture: 7%
- Product design: 6%
Tổng khối lượng công việc được đại diện: 6.000+ giờ lao động, giá trị hơn $140.000. Một số dự án có chi phí lên tới $10.000+ và kéo dài hơn 100 giờ. Thời gian hoàn thành trung bình của freelancer người thật: 28.9 giờ (trung vị: 11.5 giờ).
Leaderboard tháng 5/2026: Bức tranh không đẹp
Khi RLI được công bố lần đầu (tháng 10/2025), Manus dẫn đầu với 2.5%. Sau 7 tháng, top leaderboard giờ trông như thế này:
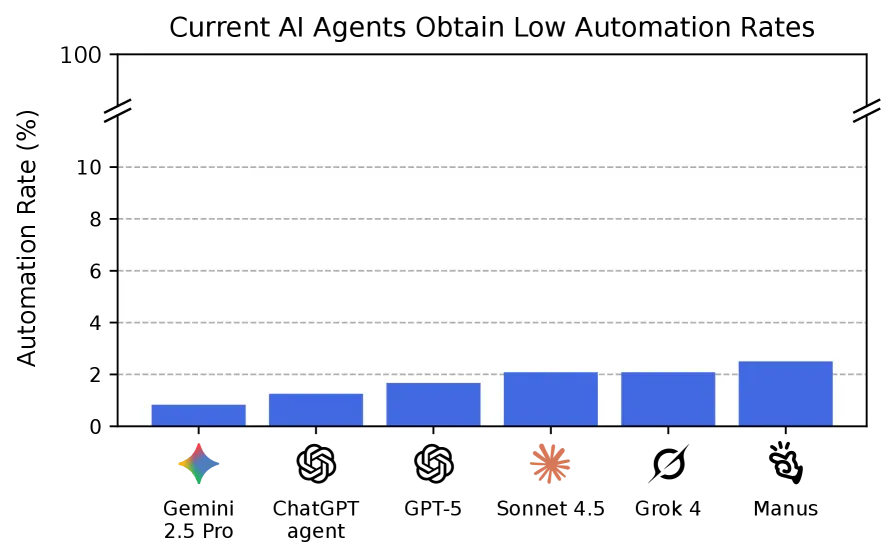
- #1 claude-opus-4-6 (CoWork): 4.17% - entry mới nhất
- #2 claude-opus-4-5 thinking: 3.75%
- #3 Manus_1.6 Max: 2.92%
- #4 gpt-5.2 (medium) & Manus 1.5: 2.50%
- #7 claude-4-5-Sonnet & gpt-5.2 (default): 2.08%
- #9 gpt-5: 1.67%
- #12 Gemini 2.5 Pro: 0.83%
Gemini 2.5 Pro - model Google quảng bá mạnh trên nhiều benchmark - đứng cuối với chỉ 0.83%. Ngay cả model dẫn đầu cũng chỉ hoàn thành được 1 trong 24 task. 23 task còn lại: thất bại.
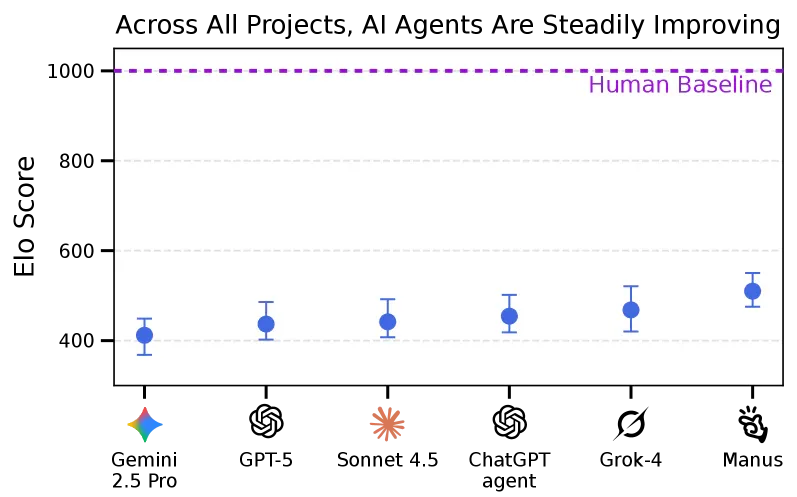
Elo score của tất cả model nằm trong khoảng 400-510, trong khi human baseline cố định ở 1000 - khoảng cách gần gấp đôi.
Tại sao AI thất bại trên công việc thực tế
Câu hỏi quan trọng hơn con số 4%: tại sao? AI đã đạt 40-80%+ trên SWE-bench và nhiều benchmark lập trình - nhưng lại sụp đổ trên công việc freelance thực tế?
Có 4 nguyên nhân chính được ghi nhận trong RLI paper:
1. Lỗi cộng dồn (Compounding failures) - Task thực tế cần 20+ bước liên tiếp. Nếu mỗi bước accuracy là 90%, tổng thành công của cả chuỗi chỉ còn ~12%. Benchmark đơn giản thường chỉ cần 1-3 bước.
2. Câu lệnh mơ hồ (Instruction ambiguity) - Brief Upwork thực tế không được viết cho AI. "Build me a scraper" không nói rõ data nào, format nào, error handling ra sao. AI agent hoặc tự assume sai hoặc hỏi quá nhiều.
3. Điều phối tool thất bại (Tool orchestration failures) - Task thực đòi hỏi chuỗi tool calls phức tạp: web search, file manipulation, API calls, code execution. Pass output từ tool này sang tool khác, xử lý rate limits và lỗi bất ngờ - AI thường gãy ở đây.
4. Môi trường không kiểm soát được (Unpredictable environments) - Website thay đổi structure, API trả về lỗi bất ngờ, file đến không đúng format. AI được train trong môi trường kiểm soát, thiếu khả năng ứng phó với bất định thực tế.
Failure mode phổ biến nhất được ghi lại: file rỗng, file bị corrupt, deliverable sai format. Những lỗi kỹ thuật cơ bản mà một freelancer người thật sẽ không mắc phải.
Góc nhìn cân bằng: AI đang cải thiện, nhưng chậm
Đây không phải là câu chuyện "AI vô dụng". Từ 2.5% (tháng 1/2026) lên 4.17% (tháng 5/2026) là mức tăng 67% trong vòng 4 tháng. Elo ranking xác nhận: model mới liên tục vượt model cũ, xu hướng cải thiện có thể đo lường được.
Điều quan trọng là biết AI làm tốt ở đâu. RLI chỉ đo autonomous completion - AI tự làm từ đầu đến cuối không có người hỗ trợ. Trong thực tế, AI vẫn tạo ra giá trị lớn khi:
- Task hẹp, lặp lại, có cấu trúc và success criteria rõ ràng
- Con người review và chỉnh sửa output (AI augment, không phải AI autonomous)
- Workflow đã được định nghĩa trước, không cần interpret brief mơ hồ
Những vendor tuyên bố AI sẽ "tự động hóa 50% công việc" thường không phân biệt autonomous vs augmented. RLI đo cái khó hơn nhiều - và kết quả nói lên tất cả.
Kết: Đọc benchmark, không đọc press release
Khi một vendor AI tuyên bố "AI sẽ thay thế X% lao động vào năm Y", hãy hỏi một câu đơn giản: Automation rate của bạn trên RLI là bao nhiêu?
4.17% không phải con số để xấu hổ - đó là baseline thực tế của năm 2026. Nhưng đừng nhầm nó với "AI đã sẵn sàng thay thế remote worker". Khoảng cách giữa Elo ~500 và Human Baseline 1000 là rất thật. Nó đang thu hẹp - chỉ là chậm hơn nhiều so với những gì headline thường gợi ý.
Tài liệu tham khảo: RLI Leaderboard | arxiv:2510.26787 | remotelabor.ai | via @gerardsans
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ