
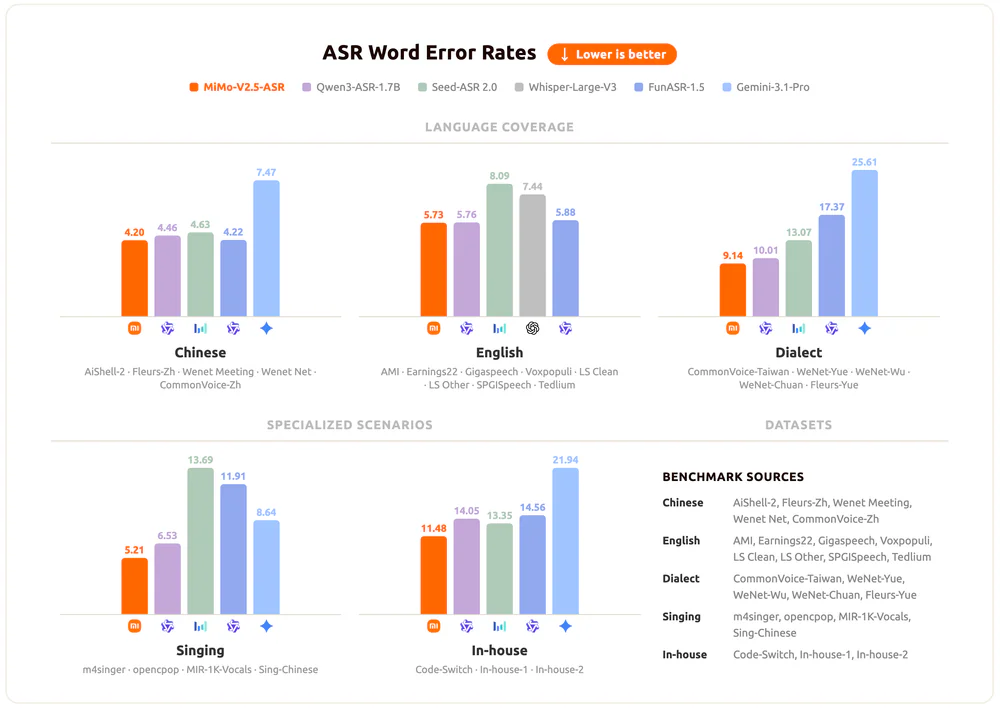
- Xiaomi just open-sourced MiMo-V2.5-ASR, an 8B-parameter end-to-end speech recognition model that posts 5.73 average WER on the Open ASR Leaderboard — ahead of Whisper-large-v3 (7.44), Seed-ASR 2.0 (8.09), and on par with Qwen3-ASR-1.7B.
- Native support for Wu, Cantonese, Hokkien, Sichuanese; no-tag Chinese–English code-switching; and lyrics transcription that actually works.
- Weights + code on Hugging Face, GitHub, and ModelScope, Apache-2.0.
TL;DR
On April 24, 2026, Xiaomi's MiMo team open-sourced MiMo-V2.5-ASR — an 8B-parameter end-to-end speech recognition model that reaches state-of-the-art on a swath of public benchmarks. Key headline numbers:
- 5.73 average WER on the Open ASR Leaderboard — ahead of Whisper-large-v3 (7.44) and Seed-ASR 2.0 (8.09).
- 2.41 WER on Fleurs-Zh, beating Gemini-3.1-Pro (3.30) and Qwen3-ASR-1.7B (3.21).
- Native Wu, Cantonese, Hokkien, Sichuanese — plus no-tag CN/EN code-switching.
- Lyrics transcription with mixed accompaniment: 2.93 WER on opencpop.
- Native punctuation from prosody — transcripts usable out of the box.
- Apache-2.0 / MIT, weights on Hugging Face, GitHub, and ModelScope.
What's new
Xiaomi dropped MiMo-V2.5-ASR alongside the MiMo-V2.5-TTS series — together they form what Xiaomi calls a "full-link" voice pipeline for the agent era: the machine now speaks and listens at SOTA level, both sides open-sourced.
This isn't a research toy. The model ships with an 8B backbone (qwen2-tagged, Safetensors/F32), a self-developed MiMo-Audio-Tokenizer, a Gradio demo, and a Python asr_sft() API you can wire into your own pipeline in minutes. Everything runs locally — CUDA 12+, Python 3.12, flash-attn — no hosted inference provider required (or available, yet).
The training recipe: large-scale mid-training → high-quality supervised fine-tuning (SFT) → a novel reinforcement-learning algorithm. Xiaomi bolted on aggressive data augmentation for noise, live-streaming, and overlap scenarios instead of hoping clean-data SFT would generalize.
Why it matters
Most production ASR stacks still lean on Whisper or a cloud API. Both assume fairly clean audio and a single dominant language. Real-world audio is messier — a Cantonese livestream seller pitching in mixed Mandarin-English at 200 words per minute over background music. Conventional end-to-end models fall apart here; MiMo-V2.5-ASR was trained specifically for that mess.
Three structural wins make this release stand out:
- Dialects at launch, not as an afterthought. Wu, Cantonese, Hokkien, Sichuanese all covered natively. No fine-tune required to get a working baseline on the "long tail" of Chinese.
- Code-switching without language tags. Most ASR models want you to pre-declare the language. MiMo handles mid-sentence switches ("Stack Overflow 是一个科技 Q&A 的平台") natively.
- Usable transcripts from byte zero. Punctuation is generated from prosody + context during decoding — no separate punctuation-restoration model needed.
Technical facts
Core specs:
- Parameters: 8B, Safetensors, F32 tensors, qwen2-tagged backbone
- Tokenizer: MiMo-Audio-Tokenizer (self-developed, paired download)
- Training pipeline: Mid-training → SFT → RL with large-scale data augmentation
- Runtime: Python 3.12, CUDA ≥ 12.0, flash-attn, Linux
- Interfaces: Gradio web demo + Python
asr_sft()API - License: Apache-2.0 (GitHub) / MIT (Hugging Face) — permissive either way
Open ASR Leaderboard scores (lower WER = better):
| Benchmark | MiMo-V2.5-ASR | Whisper-large-v3 |
|---|---|---|
| LibriSpeech Clean | 1.45 | 2.01 |
| SPGISpeech | 1.85 | 2.94 |
| Tedlium | 2.40 | 3.86 |
| AMI (meetings) | 10.63 | 15.95 |
| Voxpopuli | 6.01 | 9.54 |
| Average | 5.73 | 7.44 |
Comparison
MiMo is competing with the cream of 2026 ASR:
- vs Whisper-large-v3 (OpenAI): 5.73 vs 7.44 avg WER — a 23% relative improvement. On AMI specifically, MiMo cuts error from 15.95 to 10.63.
- vs Qwen3-ASR-1.7B (Alibaba): Essentially tied on English (5.73 vs 5.76) but MiMo dominates Chinese — Fleurs-Zh 2.41 vs 3.21, AiShell-2 2.52 vs 2.67.
- vs Seed-ASR 2.0 (ByteDance): MiMo wins decisively — 5.73 vs 8.09 on English, 2.41 vs 3.31 on Fleurs-Zh.
- vs Gemini-3.1-Pro (Google): Gemini is weak on Chinese dialects and meetings — Wenet Meeting 12.09 vs MiMo 5.92 (2× worse).
- vs FunASR-1.5 (Tongyi): Roughly matched on core benchmarks; MiMo pulls ahead decisively on lyrics (m4singer 3.95 vs 5.58; opencpop 2.93 vs 17.36).
For Mandarin and Chinese-dialect-heavy workloads, MiMo-V2.5-ASR is arguably now the single best open-weights option.
Use cases
Xiaomi's scenario showcases target some genuinely hard real-world conditions:
- Live-stream sales & esports commentary — rapid speech, heavy ambient, overlapping shouts.
- Multi-party meetings — overlapping dialogue, Chinese-English code-switching, accented English.
- Entertainment & music — pop, ballad, English song lyrics with full instrumentation.
- Historical drama & wordplay — classical Chinese poetry, idioms, homophones.
- Voice agents — paired with MiMo-V2.5-TTS as the input half of a full-link voice pipeline.
If you are shipping a Mandarin-facing voice agent, live-streaming moderation tool, or meeting-summary product, this is worth a weekend of benchmarking against whatever you use today.
Limitations & pricing
Pricing: Free. Open weights, open code, self-host required.
License: Apache-2.0 on GitHub, MIT tag on Hugging Face — mild documentation inconsistency, but both permissive commercial licenses.
Availability: Hugging Face, GitHub, and ModelScope. No hosted inference provider at launch — HF shows "not deployed by any Inference Provider."
Known rough edges:
- Wu dialect remains the hardest — WeNet-Wu WER of 19.55 is meaningfully worse than Cantonese (3.28). Not yet a solved problem.
- 8B parameters + F32 weights = non-trivial GPU requirement; expect 20–30 GB VRAM for comfortable inference. Quantized variants will help but aren't shipped out of the box.
- Installation path documented only for Linux. flash-attn compilation is slow — Xiaomi recommends a precompiled wheel.
- No published public API or hosted endpoint; production users need to stand up their own serving layer.
What's next
The MiMo team explicitly flagged two roadmap priorities: expanding dialect coverage (the 19.55 WER on Wu is likely the first target) and deepening contextual awareness (likely to close the code-switching gap — current internal benchmark still sits at 14.07 WER, the highest of any reported scenario).
With MiMo-V2.5-TTS and MiMo-V2.5-ASR both shipping Apache-2.0/MIT, Xiaomi just handed the open-source community a credible full-stack alternative to cloud voice APIs. Expect the next 6 months to be busy — quantized builds, distilled sub-billion variants, and plenty of dialect-specific fine-tunes on Hugging Face.
Nguồn: Xiaomi MiMo blog, Hugging Face model card, GitHub repo, gizmochina.

