
- Coding agent đa lượt tái dùng được 93-97% prefix nhưng phần lớn pipeline vẫn prefill lại từ đầu.
- LMCache kéo KV cache ra GPU HBM, CPU RAM, disk và Redis để dùng chung giữa các engine.
- vLLM + LMCache đạt throughput cao gấp 15 lần trong workload multi-round QA.
- Benchmark trên 2x AMD MI300X cho 32 user agentic trace ghi nhận TTFT trung bình giảm 3.0 lần và 2.3 lần requests hoàn thành.

TL;DR
- Coding agent đa lượt có 93-97% prefix lặp lại giữa các turn, nhưng hầu hết pipeline vẫn tính prefill lại từ đầu.
- LMCache là layer quản lý KV cache đứng ngoài engine, đẩy KV ra CPU RAM, NVMe, Redis hoặc S3 để dùng lại qua nhiều query và nhiều instance.
- Paper arXiv 2510.09665 báo cáo throughput vLLM + LMCache cao gấp 15 lần trong workload multi-round QA.
- Benchmark 2x AMD MI300X chạy MiniMax-M2.5 với 739 trace Claude Code: TTFT trung bình giảm 3.0 lần, p95 giảm 2.1 lần, requests hoàn thành tăng 2.3 lần ở 32 user / 100k context.
- Ở tải nhẹ, HBM prefix cache vẫn nhanh hơn. LMCache chỉ thắng rõ khi working set vượt khoảng 250-300k token.
Vấn đề: agent trả tiền prefill cho cùng một context
Một coding agent điển hình hoạt động theo vòng lặp: đọc file, gọi tool, nhận kết quả, suy nghĩ tiếp. Mỗi turn, prompt mới thường nối thêm vài trăm token output trong khi giữ nguyên 90% nội dung cũ - system prompt, instruction, file đã đọc, kết quả tool. Nếu đo trên trace thật, tỉ lệ prefix trùng giữa hai turn liên tiếp rơi vào khoảng 93-97%.
Vấn đề là phần lớn stack vLLM truyền thống coi mỗi request là độc lập. Sau khi decode xong, KV cache trên HBM bị evict để nhường chỗ cho request tiếp theo. Turn sau quay lại, engine phải prefill toàn bộ context dài trước khi sinh được token đầu tiên. Hệ quả: TTFT cao, GPU busy với công việc trùng lặp, người vận hành ngỡ là model yếu, prompt dài hay phần cứng thiếu. Trên thực tế đây là vấn đề infrastructure chứ không phải limit của LLM.
LMCache làm gì
LMCache là layer quản lý KV cache cho LLM inference, mã nguồn mở Apache 2.0 do Tensormesh phát triển. Mô tả ngắn của repo: Supercharge Your LLM with the Fastest KV Cache Layer. Hệ thống chạy như daemon độc lập, đứng giữa engine inference (vLLM, SGLang) và các tầng lưu trữ.
Thiết kế then chốt là tách KV cache khỏi vòng đời request. Khi engine sinh KV cho một context, LMCache extract block KV ra ngoài GPU và đẩy xuống tier phù hợp: CPU RAM nếu cần truy cập nhanh, NVMe local nếu working set lớn, Redis/Valkey cho cluster, S3 cho persistence dài hạn. Lần sau gặp đúng context đó - dù từ user khác, instance khác - LMCache kéo KV ngược lên HBM thay vì prefill lại.
Bốn năng lực được nhấn mạnh trong paper arXiv 2510.09665:
- Persistent tiered offloading trên GPU, CPU, disk và remote backend qua connector pluggable.
- Non-prefix KV reuse với CacheBlend - tái dùng KV của bất kỳ đoạn text lặp lại, không cần ở đầu prompt.
- Prefill-decode disaggregation truyền KV giữa GPU prefill và GPU decode qua NVLink, RDMA hoặc TCP.
- Control API + Kubernetes observability cho metric KV-specific.
CacheBlend: lý do agentic workload khác RAG đơn lượt
Prefix cache truyền thống chỉ cứu được khi prompt mới giống prompt cũ đúng từ đầu. Lệch một token là toàn bộ phần còn lại bị tính lại. Với agent, chuyện đó xảy ra liên tục: cùng một file source có thể xuất hiện ở turn 3 và turn 7 nhưng nằm sau những tool call khác nhau.
CacheBlend giải bài này bằng cách lưu KV theo chunk có hash riêng. Khi request mới đến, LMCache so khớp từng chunk, ghép KV của các chunk đã có rồi chỉ recompute selective một số token ở biên để giữ ý nghĩa attention. Kết quả: tỷ lệ cache hit thực tế cao hơn nhiều so với prefix cache thuần. Trong môi trường enterprise, paper cho biết practice cắt context (truncation) làm giảm khoảng 50% hit ratio - LMCache xử lý chuyện này bằng cách reuse mà không phụ thuộc vị trí.
Benchmark thực tế trên AMD MI300X
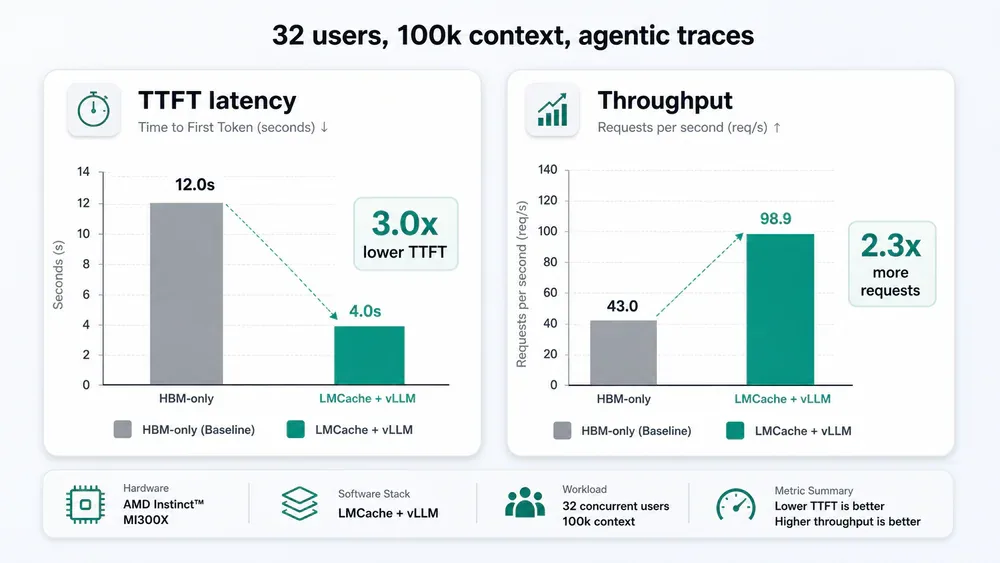
Bài blog kỹ thuật của LMCache chạy MiniMax-M2.5 (230 GB FP8 MoE) trên 2x AMD MI300X 192 GB HBM với tensor parallelism 2 và vLLM 0.19.0. Workload là replay 739 trace Claude Code đã anonymize - đại diện sát cho coding agent thật.
Khi nâng lên 32 concurrent user và 100k token context, kết quả LMCache so với HBM-only baseline:
- TTFT trung bình giảm 3.0 lần, p95 giảm 2.1 lần, max giảm 2.6 lần.
- Số request hoàn thành tăng 2.3 lần.
- Input throughput đo được 933 tok/s so với 471 tok/s.
Ở quy mô tải nhẹ, HBM prefix cache trong vLLM lại thắng: HBM sustain 8 user trong khi vanilla chỉ 2 user, và LMCache chỉ vượt rõ khi tổng working set chạm khoảng 250-300k token - vượt sức chứa hữu dụng của HBM. Synthetic benchmark còn cho thấy LMCache chậm hơn 10-17% nếu workload không có pattern lặp lại thực sự. Đây là điểm cần đọc kỹ trước khi triển khai.
Trên các model phổ biến hơn như Qwen3, Llama3, Qwen-VL, đo riêng của LMCache cho thấy speedup 3-10 lần khi tích hợp vLLM trên MI300X. Throughput cao gấp 15 lần được paper báo cáo là kết quả tổng hợp trên workload multi-round QA và document analysis với GPU NVIDIA.
So sánh với PrefixCache built-in của vLLM
vLLM bản gốc đã có prefix cache trên HBM và spill được sang CPU. SGLang có RadixAttention. Cả hai đều in-engine, gắn chặt vòng đời với pod inference. LMCache là layer external:
- Persistence: KV sống lâu hơn lifetime pod - restart không mất, instance mới hit luôn.
- Sharing: nhiều vLLM pod chia chung Redis/S3, hit chéo instance.
- Non-prefix: CacheBlend tái dùng KV cho đoạn text trùng dù không nằm đầu prompt.
- PD disaggregation: cho phép scale prefill và decode độc lập, một mô hình triển khai mà engine in-process khó dựng.
Đổi lại, LMCache thêm một lớp infrastructure phải vận hành, có chi phí I/O qua RDMA hoặc TCP, và yêu cầu tuning kỹ. Lựa chọn đúng phụ thuộc vào quy mô và mô hình workload.
Khi nào nên đem LMCache vào
Đặt câu hỏi đo lường trước, deploy sau. Có ba dấu hiệu rõ:
- p95 TTFT lớn hơn vài giây và không giảm dù model đã quantize.
- Cache hit rate trên engine hiện tại dưới 30% dù biết workload có context lặp lại.
- Working set context vượt 200k token hoặc cần share KV giữa nhiều instance.
Nếu workload là single-turn ngắn, hoặc agent chạy local quy mô nhỏ với HBM thoải mái, LMCache không cải thiện - thậm chí lùi do overhead I/O. Đo time-to-first-token p95, cache hit, working set, GPU memory pressure và tần suất refill trước khi đổ tiền vào hệ thống mới.
Quick start
Cài đặt qua pip:
pip install lmcacheCấu hình tier storage qua YAML hoặc env, ví dụ chỉ chạy CPU RAM:
LMCACHE_CHUNK_SIZE=256
LMCACHE_LOCAL_CPU=true
LMCACHE_MAX_LOCAL_CPU_SIZE=20Khởi động vLLM với LMCache connector và set PYTHONHASHSEED=0 - nếu thiếu biến này, hash chunk không ổn định và hit rate về 0. Trên ROCm cần build từ source với BUILD_WITH_HIP=1 thay vì cài wheel CUDA mặc định. Docs đầy đủ ở docs.lmcache.ai.
Kết
Trước khi đổ lỗi cho model yếu hay prompt dài, hãy kiểm tra xem coding agent đang trả tiền prefill cho cùng một context bao nhiêu lần mỗi giờ. Khi 93-97% nội dung lặp lại nhưng pipeline vẫn tính lại từ đầu, đó không phải vấn đề AI - đó là vấn đề bộ nhớ. LMCache đáng đặt lên bàn cân khi quy mô bắt đầu vượt khỏi demo: agent multi-user, RAG share document, hay cluster cần chia KV giữa nhiều pod. Repo trên GitHub LMCache/LMCache, paper trên arXiv 2510.09665, benchmark agentic trên blog LMCache. via Zuey trên Facebook.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ