
- 94% team có AI agent trong production đều dùng observability - nhưng phần lớn bắt đầu quá muộn.
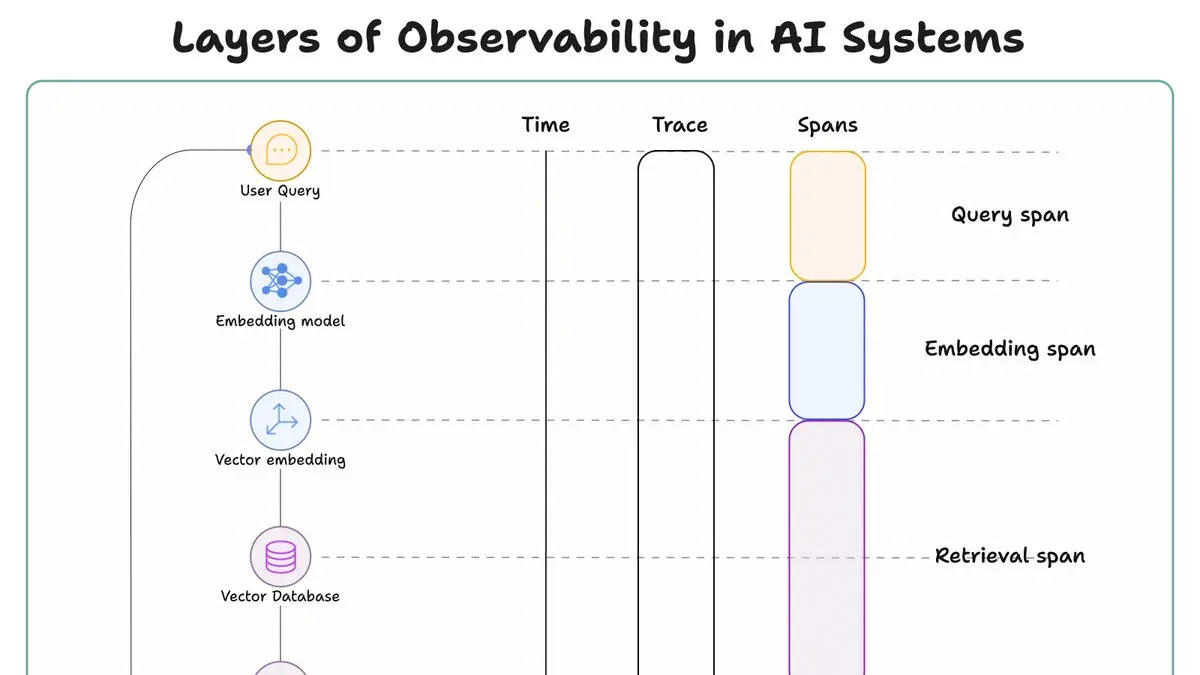
- Trace ghi lại toàn bộ hành trình từ query đến response; span là từng bước riêng lẻ bên trong.
- Không có span-level tracing, bạn chỉ biết response sai nhưng không bao giờ biết tại sao.
- Gartner dự báo 50% GenAI deployments sẽ áp dụng LLM observability vào 2028.
TL;DR
- Khi triển khai LLM cho người dùng thực, nhìn vào input và output của cả hệ thống là chưa đủ - bạn cần thấy được mỗi bước bên trong.
- Trace là container ghi lại toàn bộ hành trình của một request từ đầu đến cuối, liên kết bởi một Trace ID duy nhất.
- Span là từng operation riêng lẻ bên trong trace - embedding, retrieval, context assembly, generation - mỗi span có time, latency, và metadata riêng.
- Không có span-level tracing, bạn chỉ biết "response sai" nhưng không biết do retrieval xấu, context quá dài, hay LLM hallucinate.
- 94% team có AI agent trong production đang dùng observability. Team chưa dùng thường vẫn đang debug sự cố của tuần trước.
Vấn đề: AI pipeline là hộp đen
Hệ thống của bạn xanh hết. Không có alert, không có error. Nhưng AI đã đang trả lời sai cho người dùng suốt hai tuần qua.
Đây là điểm khác biệt cơ bản: một button bị hỏng trả về HTTP 500 - APM truyền thống bắt được ngay. Một LLM đang hallucinate trả về HTTP 200 OK. Traditional monitoring chấp nhận nó là "thành công".
Vấn đề nằm ở chỗ bạn chỉ nhìn vào input và output của cả pipeline. Bên trong là một chuỗi bước - query processing, embedding, vector search, context assembly, LLM call - mỗi bước có thể fail theo cách riêng của nó. Nếu một bước làm chậy hay tạo ra output tồi, tất cả các bước sau bị ảnh hưởng theo, nhưng bạn không biết bắt đầu debug từ đâu.
Đây là lý do traces và spans tồn tại.
Traces và Spans là gì
Hãy nghĩ RAG pipeline như một chuỗi các bước. Người dùng đặt câu hỏi, nó chạy qua nhiều component, và cuối cùng response được trả về. Mỗi bước tốn thời gian, mỗi bước có thể fail, mỗi bước có chi phí riêng.
Trace là container bao trùm toàn bộ hành trình đó. Khi người dùng gửi một query, một Trace ID duy nhất được tạo ra. Mỗi operation xảy ra trong quá trình xử lý query đó đều mang cùng Trace ID này - dù chúng xảy ra ở các service khác nhau hay thời điểm khác nhau. Nếu hệ thống xử lý 1.000 query, bạn có 1.000 traces.
Span là từng operation riêng lẻ bên trong trace đó. Khác với log chỉ ghi lại một thời điểm, span ghi lại một khoảng thời gian: thời điểm bắt đầu, thời điểm kết thúc, duration, status (thành công hay lỗi), và các attributes - metadata mô tả chi tiết điều gì đã xảy ra. Span có thể lồng nhau thành cây phân cấp: root span bao trùm toàn bộ request, các child span xử lý từng sub-operation.
Giải phẫu từng Span trong RAG
Mỗi span trong pipeline RAG tiêu biểu bắt lấy một loại vấn đề khác nhau:
- Query Span: Người dùng gửi câu hỏi. Đây là điểm bắt đầu của trace. Bạn ghi lại raw input, timestamp, và session info. Nếu có vấn đề ở đây - input bị truncate, session bị mất - bạn sẽ biết ngay từ span đầu tiên.
- Embedding Span: Query được đưa vào embedding model và biến thành vector. Span này theo dõi token count và latency. Nếu embedding API chậm hoặc đang bị rate limit, bạn bắt được ở đây - trước khi nó ảnh hưởng đến kết quả retrieval.
- Retrieval Span: Vector đi vào database để similarity search. Đây là nơi ẩn nhiều bug nhất trong RAG - bad chunks, điểm relevance thấp, giá trị top-k sai, vector DB quá tải. Một nghiên cứu học thuật 2025 xác nhận: retrieval failure là một trong hai nguồn chính gây ra hallucination trong RAG. Span này lộ ra tất cả.
- Context Span: Các chunk tìm được được ghép với system prompt. Span này cho thấy chính xác những gì sẽ được nạp vào LLM. Nếu context quá dài (vượt max tokens), bạn nhìn thấy ở đây - trước khi LLM nhận được một prompt bị cắt phần quan trọng.
- Generation Span: LLM tạo ra response. Đây thường là span dài nhất và đắt nhất. Input tokens, output tokens, latency, reasoning tokens (nếu có) - tất cả đều được log để theo dõi chi phí và debug hallucination.
Ba lý do bạn cần làm điều này ngay bây giờ
1. Debug tốc độ ánh sáng. Trước khi có observability, một response sai có nghĩa là chạy lại pipeline thủ công, tinh chỉnh prompt và hy vọng vấn đề tái hiện. Với trace đầy đủ, bạn mở trace đó lên, đọc span bị lỗi, và sửa - không cần đoán mò. Span retrieval cho thấy doc không liên quan? Vấn đề ở chunking strategy. Generation span cho thấy context hợp lý nhưng LLM vẫn trả lời sai? Vấn đề ở model. Hai trường hợp, hai hướng sửa khác nhau hoàn toàn.
2. Biết tiền chạy vào đâu. LLM tính phí mỗi API call dựa trên token. Nếu bạn chỉ nhìn hóa đơn cloud cuối tháng, bạn không biết feature nào, user nào, hay prompt version nào đang đốt ngân sách. Span-level tracking cho thấy chính xác generation span của tính năng nào tốn kém nhất - để tối ưu trước khi chi phí leo thang.
3. Bắt drift trước khi người dùng phàn nàn. AI hệ thống xuất cấp theo thời gian. Thứ hoạt động tốt tháng trước có thể không còn tốt hôm nay - embedding model update, data distribution thay đổi, knowledge base cũ đi. Span-level metrics cho phép bạn thiết lập threshold trên hallucination rate, retrieval relevance score, và latency - và nhận cảnh báo khi chúng xấu đi, thay vì phát hiện qua support ticket.
Công cụ để bắt đầu
Tiêu chuẩn kỹ thuật là OpenTelemetry (OTel) - miễn phí, open-source, và vendor-neutral. Bạn viết instrumentation code một lần, dữ liệu chạy được tới bất kỳ backend nào. Namespace gen_ai đang trở thành chuẩn cho LLM attributes (gen_ai.usage.prompt_tokens, gen_ai.request.model...).
Phía trên OTel là các platform chuyên biệt:
- LangWatch, Langfuse, Agenta - open-source, có free tier, phù hợp cho team nhỏ đến vừa
- Arize Phoenix - mạnh về drift detection và RAG monitoring
- Traceloop / OpenLLMetry - auto-instrument LangChain, LlamaIndex với ít code nhất
- DeepEval - nếu ưu tiên CI/CD testing hơn production monitoring
Nguyên tắc: bắt đầu bằng LLM call chính (prompt, response, latency, tokens), thêm retrieval span ngay sau, đo baseline trước khi sự cố xảy ra.
Tiếp theo: Observability sẽ trở thành bắt buộc
Gartner dự báo LLM observability sẽ đạt 50% trong tất cả GenAI deployments vào 2028 - từ mức 15% hiện tại. OpenTelemetry đang chính thức mở rộng vào AI Agent Observability với các span kind chuyên biệt (agent, workflow, tool). Bên cạnh đó, Voice Observability đang nổi lên như một lĩnh vực riêng để bắt các lỗi lớp audio mà text traces không thể nhìn thấy.
Những điều không thay đổi: nếu không có visibility vào từng bước trong pipeline, bạn đang blind-fly trong production. Span-level tracing là điều kiện cơ bản để vận hành AI system tin cậy.
Nguồn: @_avichawla, Traceloop, Agenta, Cekura.
