
- LatentSync của ByteDance đạt 94% SyncNet accuracy trên HDTF, vượt qua Wav2Lip, DINet, MuseTalk về mọi chỉ số chất lượng.
- Chỉ cần 8GB VRAM để chạy inference, hoàn toàn miễn phí và open-source.
- Dựa trên Stable Diffusion 1.5 với cơ chế TREPA độc quyền giúp giữ temporal consistency mà không làm giảm độ chính xác lip-sync.
TL;DR
ByteDance vừa open-source LatentSync - framework lip-sync đầu cuối dựa trên audio-conditioned latent diffusion models. Tool này cho phép thay thế audio trong video và tự động đồng bộ chuyển động môi khớp hoàn toàn với giọng nói mới. Kết quả: 94% SyncNet accuracy trên HDTF test set, FID 7.03 - tốt hơn tất cả các tool lip-sync open-source hiện có. Inference chỉ cần 8GB VRAM (v1.5), API miễn phí trên Replicate và Fal.
LatentSync là gì
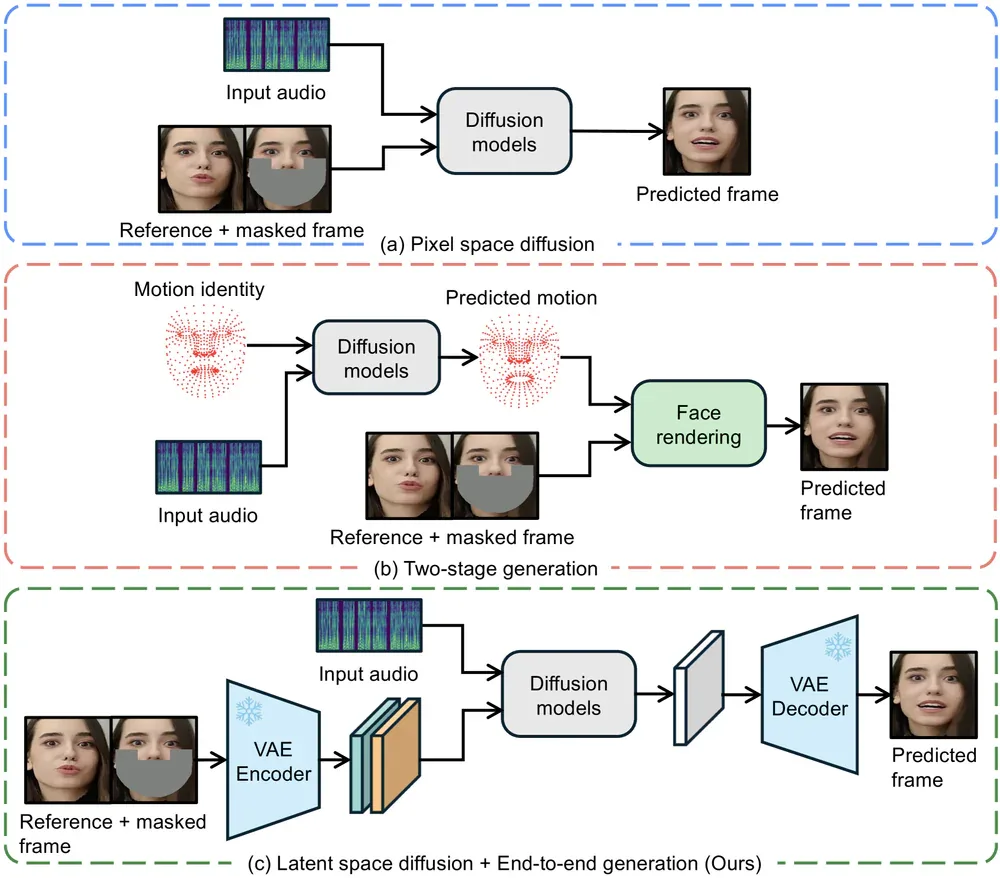
LatentSync là framework lip-sync end-to-end của ByteDance, công bố tháng 12/2024 qua bài báo arXiv:2412.09262. Điểm khác biệt cốt lõi: thay vì dùng intermediate representation như 3D morphable models (SadTalker) hay 2D landmarks, LatentSync hoạt động trực tiếp trong latent space của Stable Diffusion 1.5.
Quy trình đơn giản: người dùng upload video gốc và file audio mới. Model tự động điều chỉnh chuyển động môi trong video khớp với audio - không cần quay lại, không cần chỉnh tay từng frame.
Kỹ thuật đằng sau
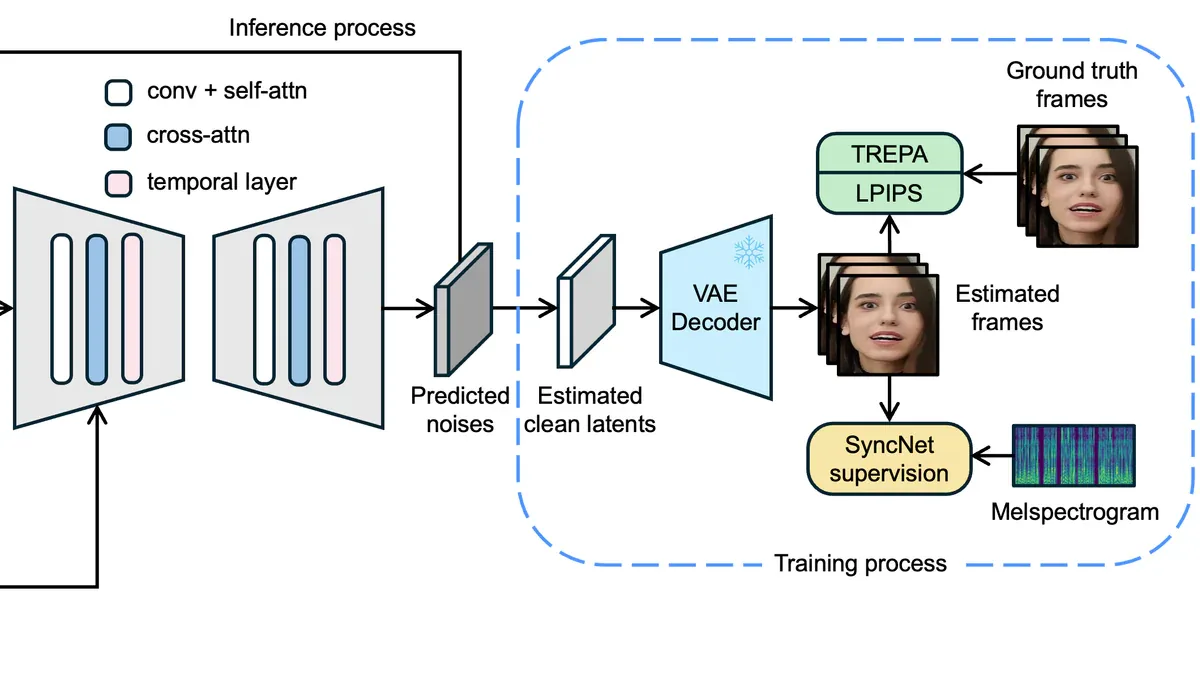
Kiến trúc LatentSync gồm 3 thành phần chính:
- Audio pipeline: Whisper chuyển audio thành mel-spectrogram, sau đó encode thành audio embeddings và tích hợp vào U-Net qua cross-attention layers.
- U-Net input: 13 channel được concatenate gồm noise latents, mask, masked image và reference frame - cho phép model học cả context ngữ cảnh khuôn mặt lẫn audio.
- TREPA (Temporal Representation Alignment): cơ chế độc quyền dùng VideoMAE-v2 để align temporal representations, đảm bảo các frame liên tiếp nhất quán mà không làm giảm độ chính xác lip-sync - điểm mà các temporal layer thông thường thường gặp trade-off.
Để SyncNet training hội tụ ổn định, nhóm nghiên cứu xác định 3 yếu tố then chốt: batch size tối thiểu 1024, input 16 frame liên tiếp, và pipeline preprocessing chuẩn hoá âm thanh ở 16000Hz / video ở 25fps.
Con số đáng chú ý
LatentSync được đánh giá trên 2 dataset chuẩn trong lĩnh vực:
- SyncNet accuracy: 94% trên HDTF test set (cải thiện từ 91%)
- FID: 7.03 (HDTF) và 5.6 (VoxCeleb2) - đo chất lượng visual
- FVD: 192.74 (HDTF) và 124.38 (VoxCeleb2) - đo temporal consistency
- SyncConf: 8.9 (HDTF) và 7.3 (VoxCeleb2)
Training data: VoxCeleb2 (hơn 1 triệu utterances từ 6000+ người nói) kết hợp HDTF (362 video HD từ 720p đến 1080p).
So sánh với các tool khác

LatentSync vượt trội trên tất cả các chỉ số so với các tool hiện có:
| Tool | Phương pháp | Điểm mạnh | Hạn chế |
|---|---|---|---|
| Wav2Lip | GAN-based | Nhẹ, dễ triển khai | Blur quanh môi, ít detail |
| SadTalker | 3D morphable model | Head motion tự nhiên | Lip-sync kém chính xác |
| MuseTalk | Pixel-space diffusion | Realtime inference | Temporal consistency thấp |
| DINet | Deformation-based | Tốc độ ổn | Kém về visual quality |
| LatentSync | Latent diffusion | FID, FVD, SyncConf tốt nhất | VRAM cao hơn, cần kỹ thuật |
Điểm khác biệt rõ nhất trong demo: môi trong output của LatentSync sắc nét, tự nhiên, không bị hiệu ứng uncanny valley mà Wav2Lip hay gặp ở khuôn mặt độ phân giải cao.
Ai nên dùng ngay
LatentSync phù hợp nhất với những nhóm sau:
- Content creator YouTube/TikTok: muốn sản xuất video đa ngôn ngữ mà không cần quay lại - chỉ cần dịch audio và sync.
- Studio dubbing: localise phim, series, bài giảng sang ngôn ngữ khác với lip-sync chính xác.
- Developer xây dựng avatar AI: tích hợp qua API Replicate hoặc Fal vào sản phẩm.
- Researcher: toàn bộ training code, data pipeline và checkpoint đều public - có thể fine-tune hoặc experiment trực tiếp.
Giới hạn cần lưu ý: v1.5 cần 8GB VRAM để inference, v1.6 cần 18GB. Training từ đầu yêu cầu 20-55GB tùy stage và độ phân giải. Model chỉ validate trên SD 1.5 - chưa test với SDXL hay FLUX.
Kết
LatentSync là minh chứng rõ ràng rằng latent diffusion không chỉ giỏi sinh ảnh tĩnh - khi áp dụng đúng với TREPA và SyncNet supervision, chất lượng lip-sync có thể vượt hẳn các phương pháp GAN truyền thống trên cả ba chiều: visual quality, temporal consistency và sync accuracy.
Phiên bản hiện tại đang ở v1.6 (tháng 6/2025) với training trên độ phân giải 512×512 để giảm blurriness. Dự án open-source, miễn phí, và dễ tiếp cận qua API. Đây là baseline mặc định cho bất kỳ ai cần lip-sync chất lượng cao trong năm 2025.
Nguồn: arXiv:2412.09262 · GitHub - bytedance/LatentSync · Replicate API