
- Nhóm nghiên cứu Đại học Chiết Giang và Ant Group công bố KMLP — kiến trúc KAN + gMLP tự động học feature, đạt SOTA trên 2 tỷ mẫu, vượt LightGBM 1.76 điểm KS và đem về 670 triệu USD tăng trưởng tín dụng thực tế.
TL;DR
KMLP là kiến trúc deep learning lai mới do Đại học Chiết Giang + Ant Group công bố tại The Web Conference 2026 (arXiv 2602.22777, 26/02/2026). Nó ghép một Kolmogorov-Arnold Network (KAN) nông ở front-end với Gated MLP (gMLP) làm backbone, tự động học feature transformation trên dữ liệu tabular quy mô web. Trên bộ dữ liệu tín dụng 2 tỷ mẫu của Ant Group, KMLP vượt LightGBM +1.76 điểm KS, đem về giảm 46 triệu USD nợ quá hạn và tăng 670 triệu USD quy mô tín dụng sau 6 tháng triển khai. Điểm khác biệt lớn nhất: khoảng cách với GBDT mở rộng khi dữ liệu scale lên — đảo ngược niềm tin cũ rằng GBDT vô địch trên tabular.
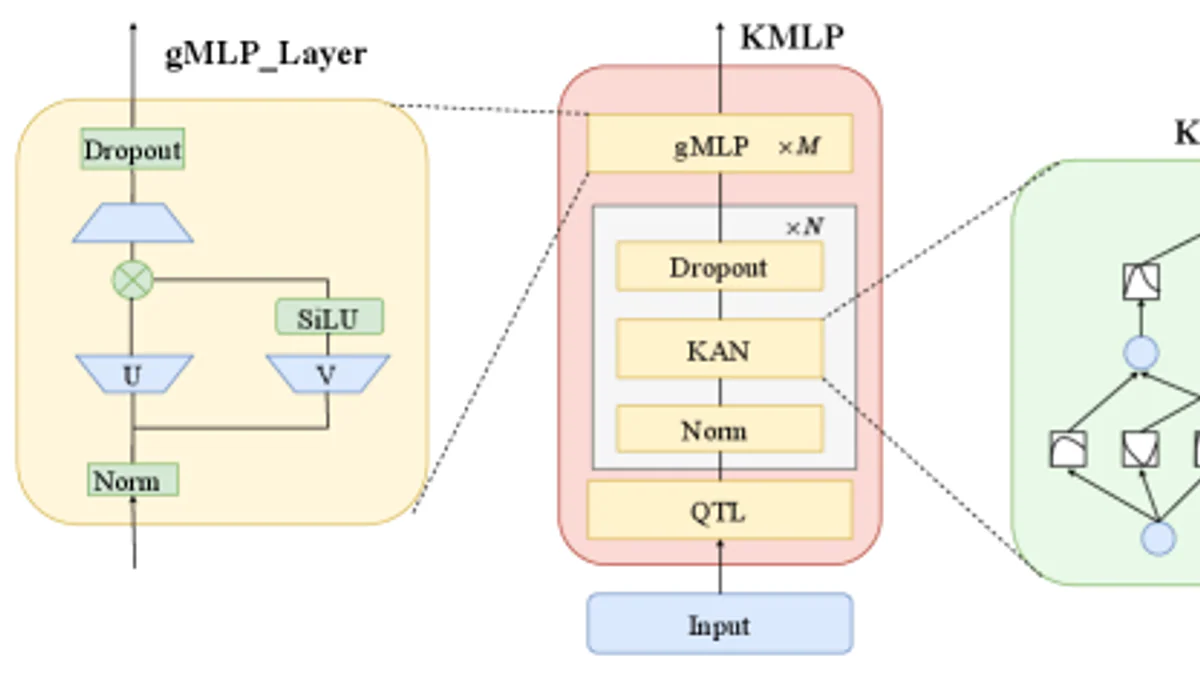
Có gì mới?
Trong ngành, mọi bài toán web-scale tabular — chấm điểm tín dụng, CTR quảng cáo, fraud, recommendation — đều chung một công thức mệt mỏi: kỹ sư ngồi thủ công nghĩ ra hàng trăm feature (log, bucket, cross-feature), rồi quăng vào XGBoost/LightGBM. GBDT mạnh nhưng train tuần tự, không tận dụng được GPU phân tán, và mỗi lần phân phối feature dịch chuyển phải retrain + rework feature.
KMLP tách bạch 2 việc này về mặt kiến trúc:
- KAN front-end học activation function cho từng feature bằng basis B-spline bậc 3 + SiLU — thay thế luôn phần feature engineering thủ công.
- gMLP backbone dùng khối
SwiGLU(x) = SiLU(xV + b₁) ⊗ (xU + b₂)để nắm bắt tương tác bậc cao giữa các feature đã được KAN tinh chỉnh. - QTL preprocessing: quantile transform đưa giá trị về phân phối đều nhưng giữ thứ tự trong từng bin — xử lý phân phối đuôi nặng, không dừng mà GBDT rất khó chịu.
Vì sao đáng chú ý?
Hai thập kỷ qua, cộng đồng ML đều thuộc câu châm ngôn: “deep learning thua GBDT trên tabular”. Các paper như TabNet, FT-Transformer, SAINT đều không kéo được khoảng cách khi dữ liệu lớn. KMLP là bằng chứng công khai đầu tiên cho thấy nếu thiết kế đúng — KAN làm feature học, gMLP làm interaction — thì DL không chỉ bằng mà vượt GBDT, và khoảng cách rộng dần theo kích thước dữ liệu. Với bất kỳ tổ chức nào đang ngồi trên bảng 100 triệu dòng trở lên, đây là tín hiệu để xem lại pipeline.
Số liệu kỹ thuật
KMLP được đánh giá trên 6 benchmark công khai (13K–98K mẫu) + một bộ dữ liệu tín dụng công nghiệp cực lớn của Ant Group.
| Chỉ số | Giá trị |
|---|---|
| Dataset công nghiệp — train | 2 tỷ mẫu |
| Dataset công nghiệp — test | 1 tỷ mẫu |
| Số feature số | 449 |
| Thời gian train (KMLP) | 10 giờ · 8× A100 |
| Thời gian train (LightGBM) | 24 giờ · 10.000 CPU |
| Inference 1 tỷ mẫu | ~2 giờ |
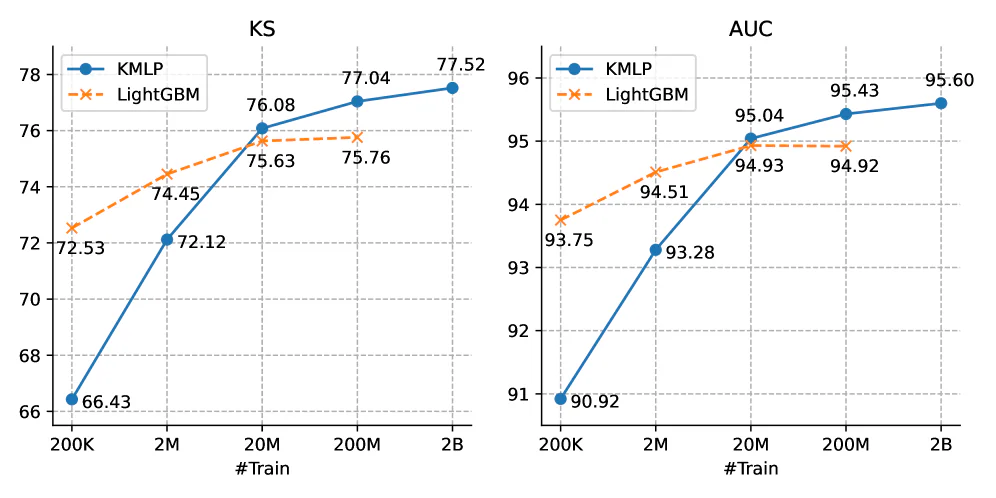
Đường KS ở 200K mẫu: LightGBM dẫn với 72.53 vs KMLP 66.43. Nhưng từ ~20M mẫu trở đi KMLP vượt lên, đạt 77.52 KS ở 2B mẫu trong khi LightGBM chỉ đạt 75.76 tại 200M và không scale tiếp nổi. AUC 2B: 95.60.
So sánh với baseline
| Dataset | KMLP AUC / KS | LightGBM AUC / KS |
|---|---|---|
| Medium Financial | 95.04 / 76.08 | 94.93 / 75.63 |
| Higgs | 80.88 / 46.23 | 79.86 / 44.16 |
| Industrial 2B | 95.60 / 77.52 | 94.92 / 75.76 (@200M) |
Nhóm baseline đầy đủ gồm: LightGBM, XGBoost, FT-Transformer, TabNet, SAINT, NODE, DANet, TabTransformer. KMLP đạt SOTA trên cả benchmark công khai và dataset công nghiệp.
Use case thực tế
- Chấm điểm rủi ro tín dụng — domain triển khai gốc tại Ant Group.
- CTR quảng cáo, ranking, fraud, churn, loan default — bất kỳ bài toán tabular web-scale nào đang dùng GBDT.
- Teams mệt mỏi với feature engineering thủ công — KAN front-end bỏ qua bước này hoàn toàn.
- Pipeline đã đụng trần training wall-clock — KMLP dùng GPU phân tán, LightGBM thì không.
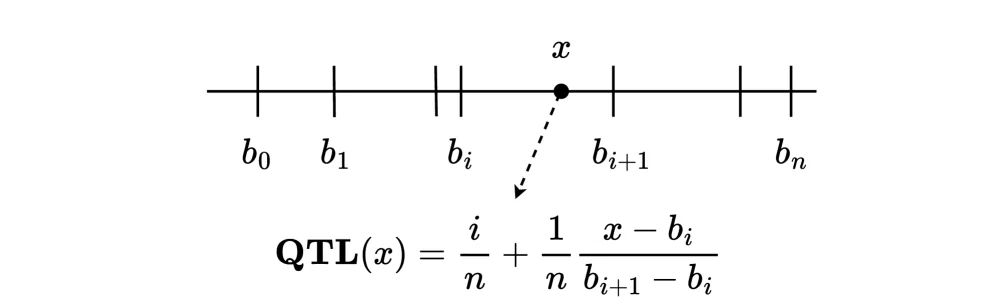
Hạn chế & điểm cần lưu ý
- Code chưa được open-source công khai ở arXiv v1 — đây là research + deployment paper, chưa phải thư viện dùng ngay.
- Lợi ích kinh tế vs GBDT chỉ rõ khi dữ liệu ≥ 100M dòng. Dưới mức đó LightGBM vẫn ngon và rẻ.
- Yêu cầu hạ tầng GPU (A100 hoặc tương đương) cho training — chi phí khởi điểm cao hơn cluster CPU thuần.
- Paper không công bố giá / license — là artifact học thuật + công nghiệp, không phải sản phẩm SaaS.
Bước kế tiếp
KMLP đã chạy production trong hệ tín dụng của Ant Group, đem về tác động đo lường được: −46 triệu USD nợ quá hạn, +670 triệu USD quy mô tín dụng trong 6 tháng. Kỳ vọng ngắn hạn: cộng đồng sẽ có reproduction trên HuggingFace, và các biến thể mở rộng KAN front-end cho dữ liệu multi-modal (tabular + sequence + text) sẽ xuất hiện trong năm 2026.
Với practitioner, bước hành động rõ ràng: nếu bạn đang chạy LightGBM/XGBoost trên bảng 100M+ dòng với feature engineering nặng tay, KMLP xứng đáng là benchmark tiếp theo cần thử.
Nguồn: arXiv 2602.22777, Hugging Face Papers, Jiqizhixin.
