
- Andrej Karpathy public một script ~630 dòng để AI tự chạy 700 thí nghiệm ML qua 2 ngày, kéo benchmark Time to GPT-2 từ 2.02 giờ xuống 1.80 giờ.
- Ole Lehmann adapt pattern này cho landing page copy: pass rate 56% lên 92% sau một đêm, tốn ~$15.
- Bí quyết không phải thêm quyền cho agent mà là siết lại: một file, một metric, cap 5 phút mỗi thí nghiệm.
- Với marketer, nó là bộ lọc trước khi đốt budget, không phải bản thay thế A/B test.
TL;DR
- AutoResearch là pattern Karpathy public đầu tháng 3/2026: một AI agent sửa một file, chạy thí nghiệm cap 5 phút, đo một metric, giữ nếu tốt hơn / rollback nếu tệ hơn, lặp cả đêm.
- Run thực tế của Karpathy: 700 thí nghiệm trong 2 ngày, 20 cải tiến cộng dồn, kéo "Time to GPT-2" từ 2.02 giờ xuống 1.80 giờ. CEO Shopify Tobias Lütke replicate: 37 thí nghiệm qua đêm, +19%.
- Ole Lehmann adapt cho copywriting: skill viết landing page đi từ 56% lên 92% pass rate sau một đêm, chi phí ~$15.
- Điểm mấu chốt: constraint là feature. Vòng nhỏ cộng feedback nhanh thắng những run mở-rộng-vô-định.
- Với marketer: dùng như bộ lọc trước (ad copy, subject line, headline) trước khi đốt budget - không thay được A/B test với người thật.

AutoResearch là gì - và vì sao nó nhỏ đến vậy
Đầu tháng 3/2026, Andrej Karpathy - đồng sáng lập OpenAI, người đặt ra cụm "vibe coding" - public repo autoresearch trên GitHub. Nó cố tình nhỏ: một script Python khoảng 630 dòng, một GPU, một file train, một metric.
Vòng lặp như sau: agent đọc file hướng dẫn, đề xuất sửa một biến trong train.py, chạy một job training đúng 5 phút, đo val_bpb (validation bits-per-byte, thấp hơn là tốt hơn), commit nếu cải thiện, rollback nếu không, rồi lặp lại. Có thể chạy cả đêm - tỉnh dậy là có một experiment log và (lý tưởng) model tốt hơn.
Điểm tinh tế: Karpathy không dùng LLM-chấm-LLM cho bản gốc. Anh ấy chọn một con số scalar duy nhất, tính được mà không cần con người phán xét. Lý do: metric mơ hồ, hay metric tối ưu proxy thay vì kết quả thật, sẽ bị một vòng lặp tự động khai thác đến tận cùng.
Những con số đáng chú ý
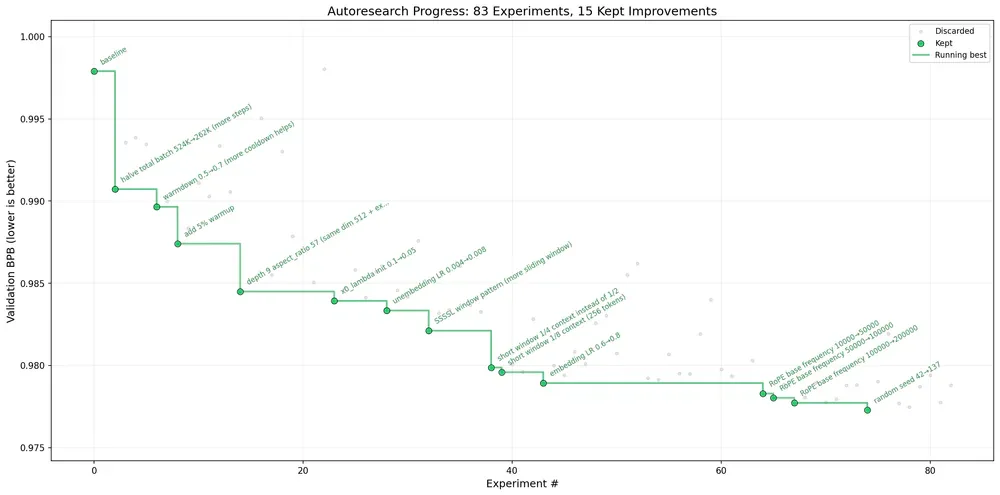
Run kéo dài 2 ngày của chính Karpathy: 700 thí nghiệm, agent stack được 20 cải tiến cộng dồn, kéo benchmark "Time to GPT-2" từ 2.02 giờ xuống 1.80 giờ (khoảng 11% trên model lớn hơn). Tobias Lütke, CEO Shopify, chạy lại pattern này: 37 thí nghiệm qua đêm, +19% hiệu năng. Với cap 5 phút mỗi thí nghiệm, một đêm cho ra khoảng 100 vòng lặp - tức khoảng 12 vòng mỗi giờ.
Khi pattern này chạm tới marketing

Ole Lehmann (The AI Solopreneur) thay train.py bằng một prompt template, thay val_bpb bằng checklist 3-6 câu hỏi yes/no định nghĩa thế nào là output "tốt": headline có chứa con số không? Không có buzzword? CTA dùng động từ cụ thể? Dưới 150 từ?
Anh để agent chạy vòng lặp đó qua một đêm. Skill viết landing page copy đi từ 56% lên 92% pass rate, tốn khoảng $15 cho 16 thí nghiệm. Agent tự thêm rule cấm hứa hẹn mơ hồ, dựng banned-buzzwords list ("revolutionary", "synergy", "cutting-edge"), chèn worked example - và có lúc thử siết word count rồi tự lùi lại khi nhận ra nó làm hỏng CTA. Nó thử, thấy tệ, đảo ngược - không cần ai bảo.
Chỗ pattern này dùng được hôm nay là bất cứ đâu AI tự chấm chất lượng được mà không phải chờ data người dùng:
- Biến thể ad copy - trước khi đổ budget
- Email subject line - trước khi bấm gửi
- Headline landing page - trước khi kéo traffic
- Newsletter intro, cold outreach template
Coi nó là pre-filter, không phải bản thay A/B test.
Vì sao "ít quyền hơn" lại thắng
Trào lưu agent đang đi theo hướng "more autonomy" - thêm tool, thêm context, thêm tự do. Karpathy đi ngược: một file, một metric, cap 5 phút. Constraint trở thành feature: vòng lặp nhỏ với feedback nhanh đánh bại những run mở-rộng-vô-định mỗi lần. Karpathy còn nói thẳng định hướng tiếp theo không phải làm một agent giỏi hơn mà là một swarm chạy song song - "mục tiêu không phải mô phỏng một nghiên cứu sinh PhD, mà mô phỏng cả một cộng đồng nghiên cứu", và "tất cả frontier lab sẽ làm cái này, đây là trận đánh trùm cuối".
Mặt trái: AI đang chấm điểm AI
Bản marketing có một lỗ hổng cần nói thẳng. Trong ML bạn có feedback trong 5 phút: sửa code, chạy test, ra điểm. Marketing cần con người mở email, click ad, vào trang - mất hàng giờ tới ngày. Feedback loop quá chậm cho 12 thí nghiệm mỗi giờ.
Nên bản của Ole dùng một LLM chấm output của LLM theo rubric do LLM sinh ra. Con số 56% lên 92% là đúng, nhưng chưa validate với conversion thật. Nó nói lên "bản nháp này qua được checklist nội bộ", không nói lên "bản này bán được hàng hơn". Và metric phải khó lách - bất kỳ metric nào "cần cả hội đồng diễn giải" sẽ bị agent khai thác.
Bạn nên thử gì
Lập luận về chi phí mới là điểm thật sự: bạn chạy được 16 thí nghiệm qua đêm với khoảng $15. Vấn đề không còn là win rate - mà là chi phí thử nghiệm vừa rơi xuống gần bằng 0. Nếu bạn có một prompt hay skill dùng đi dùng lại và chấm điểm được nó, bạn autoresearch được nó.
Bắt đầu bằng việc viết một checklist 3-6 câu yes/no cho một asset cụ thể (subject line, headline, intro), chạy skill một lần để có baseline, rồi để vòng lặp tự đổi một biến mỗi vòng. Giữ win, bỏ loss, lưu changelog. Đừng kỳ vọng nó thay được A/B test - kỳ vọng nó dọn sạch những phương án hiển nhiên kém trước khi bạn tốn tiền thật.
Đọc thêm: repo autoresearch via Karpathy, "The Karpathy Loop" via Fortune, và phân tích ML-to-marketing via Sameer Khan.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ