
- HeavySkill biến heavy thinking thành 2 giai đoạn song song và tổng hợp tuần tự, đạt 100% AIME25 với Kimi K2 và DeepSeek V3.2.
- GPT-OSS-20B tăng từ 69.7% lên 85.5% trên LiveCodeBench.
- Open-source Apache-2.0, tích hợp trực tiếp Claude Code không cần sửa code.
TL;DR
HeavySkill là framework mã nguồn mở biến heavy thinking - khả năng suy luận chuyên sâu của các AI model - thành một kỹ năng có thể học và tối ưu hóa. Thay vì chạy 1 lần suy nghĩ rồi lấy kết quả, HeavySkill sinh K trajectories song song rồi dùng một model thứ hai để tổng hợp toàn bộ. Kết quả: Kimi K2 và DeepSeek V3.2 đạt 100% AIME25, GPT-OSS-20B nhảy từ 69.7% lên 85.5% trên LiveCodeBench - chỉ bằng cách thay đổi cách gọi API.
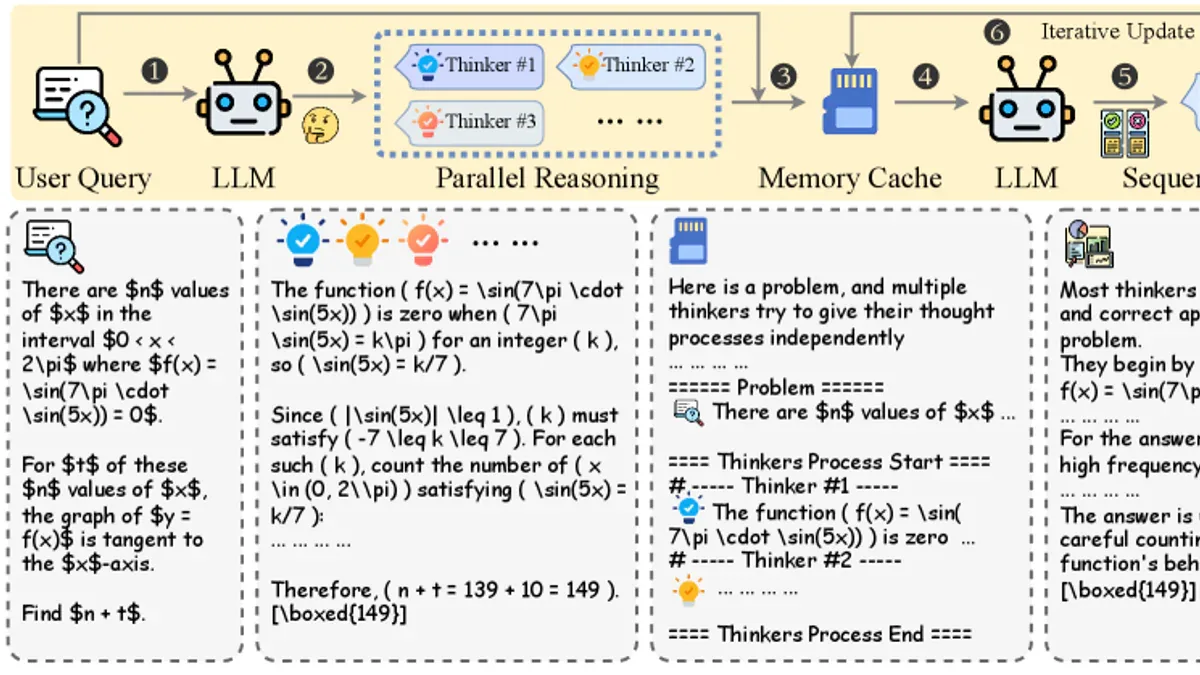
Tại sao sinh nhiều câu trả lời chưa đủ?
Majority voting (Vote@K) - chọn câu trả lời được đa số đồng ý trong K lần chạy - là kỹ thuật phổ biến để cải thiện độ chính xác. Nhưng voting có giới hạn cơ bản: nó chỉ chọn đáp án phổ biến nhất, không thực sự phân tích các luồng lập luận. Nếu cùng một lỗi sai xuất hiện trong đa số trajectories, voting vẫn chọn lỗi đó.
HeavySkill đặt câu hỏi khác: Điều gì xảy ra nếu một model thứ hai thực sự đọc, phân tích, và tổng hợp tất cả các luồng suy nghĩ? Đây là gốc rễ của paradigm "parallel reasoning + sequential deliberation" mà paper arxiv 2605.02396 hệ thống hóa lần đầu tiên một cách toàn diện.
Kiến trúc 2 giai đoạn
HeavySkill hoạt động theo 2 giai đoạn rõ ràng:
- Giai đoạn 1 - Parallel Reasoning: Gọi model K lần song song với cùng bài toán. Mỗi lần là một luồng suy nghĩ hoàn chỉnh và độc lập. Mặc định K=8, temperature=1.0 để tối đa hóa sự đa dạng.
- Giai đoạn 2 - Sequential Deliberation: Toàn bộ K trajectories được nén vào một Serialized Memory Cache (có pruning và shuffling để tránh positional bias), rồi đưa cho model deliberation để phân tích, tìm mâu thuẫn, và ra đáp án cuối.
Điểm thú vị: model deliberation không cần giỏi tự suy luận. Qwen2.5-32B-Instruct - chỉ đạt 12.8% AIME25 khi chạy độc lập - vẫn cải thiện kết quả khi làm deliberator, vì nó chỉ cần phân tích và tổng hợp, không cần năng lực reasoning chuyên sâu. Điều này có nghĩa bạn có thể dùng một model nhẹ hơn cho deliberation và tiết kiệm chi phí.
Framework còn được distill thành một skill file plain-text tương thích trực tiếp với Claude Code (cũng như CodeX và Hermes) mà không cần chỉnh code framework - chỉ copy file vào thư mục skills là dùng được.
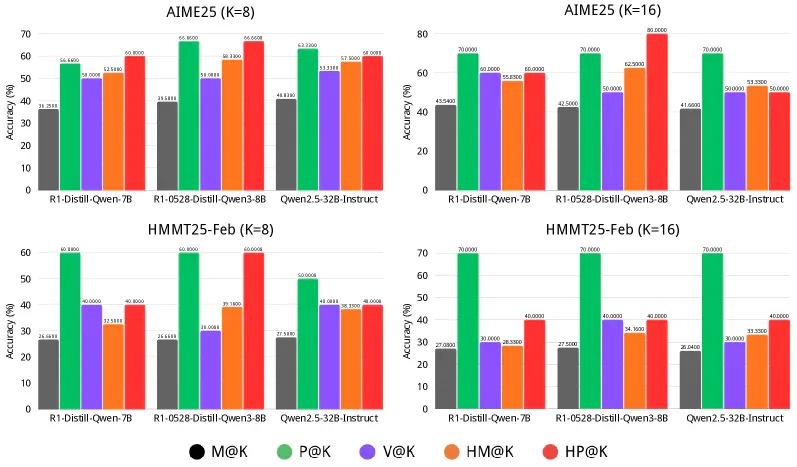
Con số đáng chú ý
Paper kiểm thử trên hàng loạt frontier model với kết quả nhất quán:
- AIME25: Kimi K2 Thinking đạt HM@4=100%. DeepSeek V3.2 Thinking với K=16 đạt HM@4=100%. GPT-5 Thinking đạt HM@4=96.7%.
- LiveCodeBench (24.08-25.05): GPT-OSS-20B từ 69.7% lên 85.5% (+15.8 điểm tuyệt đối).
- IFEval (instruction following): R1-Distill-Qwen-32B từ 35.7% lên 69.3% - gần gấp đôi chỉ nhờ deliberation.
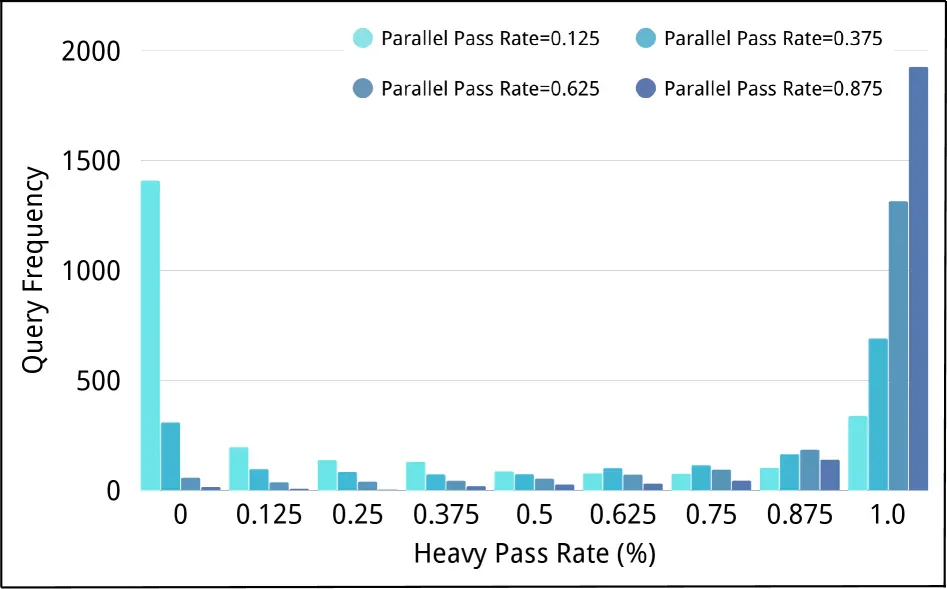
- IMO Answer Bench: GLM 4.6 đạt HP@4=86.0% so với P@K=75.1% - deliberation tạo ra đáp án đúng không có trong bất kỳ trajectory gốc nào.
Thứ bậc hiệu suất nhất quán trên mọi benchmark STEM: Heavy-Pass@k >= Heavy-Mean@K >= Vote@K >= Mean@k. Quan trọng là Heavy-Pass@K vượt Pass@K (upper bound lý thuyết) trong gần 50% thử nghiệm - có nghĩa deliberation có thể tạo ra đáp án đúng mới hoàn toàn không tồn tại trong tập trajectories gốc.
Ai nên thử ngay
HeavySkill phát huy tối đa với các tác vụ có câu trả lời khả kiểm (verifiable):
- Giải toán thi đấu (AIME, HMMT, IMO-level) và câu hỏi nghiên cứu khoa học cấp sau đại học
- Competitive programming và code generation cần độ chính xác cao
- Instruction following phức tạp với nhiều ràng buộc cứng
- Agentic workflows tích hợp tool-use (Python interpreter, code execution feedback)
Ngược lại, với các tác vụ preference-oriented - chat phong cách, sáng tác tự do, đánh giá chủ quan (Arena-Hard) - gains từ HeavySkill marginal hoặc âm. Deliberation giỏi phân biệt "đúng/sai", không giỏi phân biệt "hay/chưa hay".
Giới hạn cần biết trước
- Chi phí gọi API: K=8 parallel + K⁽¹⁾=4 deliberation = ~12 inference calls mỗi query. Tốn gấp ~12 lần so với single-call thông thường.
- Context window: Serializing K trajectories dài dễ vượt max context length. Script có pruning nhưng vẫn cần model hỗ trợ context lớn.
- Verbosity không phải chất lượng: Chọn K trajectories dài nhất (Max-Length) là chiến lược tệ nhất. Max-Answer-Num (consensus selection) vượt trội hơn hẳn Random và Max-Diversity.
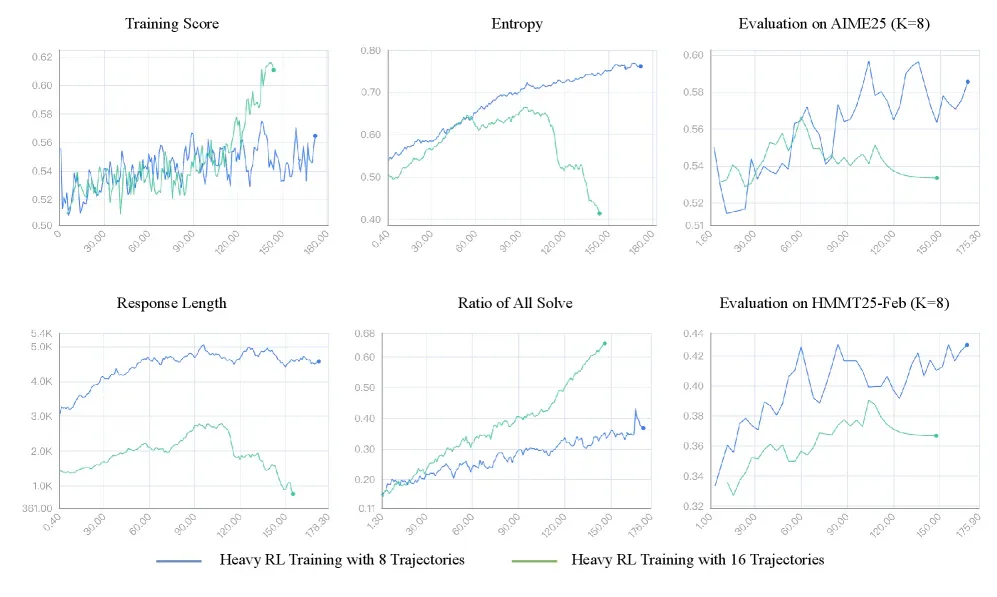
- RLVR với K=16: Entropy collapse sau 100 training steps do context length. K=8 ổn định hơn trong quá trình RLVR fine-tuning.
Tương lai của heavy thinking
Paper chứng minh RLVR có thể train heavy thinking thêm: trong 100 steps đầu, HM@4 cải thiện ~10%. Đây mở ra hướng dài hạn là self-evolving LLMs - model tự internalize complex reasoning mà không cần brittle orchestration layers bên ngoài.
Snell et al. (2024) đã chỉ ra "scaling test-time compute có thể hiệu quả hơn scaling model parameters". HeavySkill là minh chứng thực tế: thay vì train model to hơn, ta dạy model cách dùng compute thông minh hơn ở inference time - một hướng đi có thể tự tối ưu tiếp qua reinforcement learning.
Code mở tại github.com/wjn1996/HeavySkill (Apache-2.0). Cài qua git clone && pip install -e .. Tương thích mọi OpenAI-compatible endpoint: vLLM, DeepSeek, Together AI, OpenRouter, Ollama. via arxiv 2605.02396
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ