
- Google Cloud ra mắt 3 StorageClass profiles cho GKE tự động tune Cloud Storage FUSE theo training, serving và checkpointing — giảm thời gian load Qwen3-235B từ 39 giờ xuống 14 phút, không cần chỉnh tay hàng chục mount options.
TL;DR
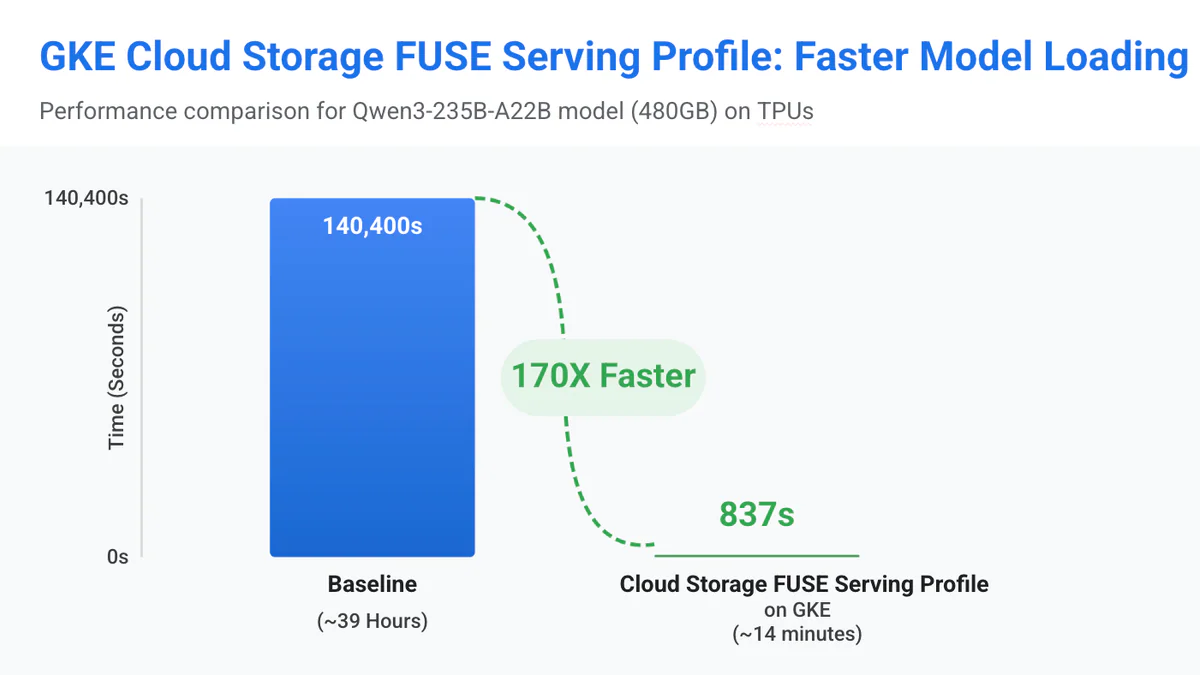
Ngày 9/4/2026, Google Cloud công bố GKE Cloud Storage FUSE Profiles — ba StorageClass dựng sẵn (gcsfusecsi-training, gcsfusecsi-serving, gcsfusecsi-checkpointing) tự động tune mount options và cache size theo loại workload AI/ML và tài nguyên node. Case study flagship: load Qwen3-235B-A22B (480GB) trên TPU giảm từ 39 giờ xuống 14 phút — nhanh hơn ~170×. GA từ GKE 1.35.1-gke.1616000.
Có gì mới
Cloud Storage FUSE cho phép mount một bucket GCS như filesystem POSIX trong Pod. Nhưng để chạy nhanh cho AI/ML, phải chỉnh tay hàng chục flag: read-ahead, file cache size, metadata prefetch, sidecar memory, Local SSD... Cấu hình training tối ưu thì sai cho inference, và ngược lại.
Profiles giải quyết bằng 3 StorageClass pre-installed:
gcsfusecsi-training— read throughput cao để giữ GPU/TPU không bị đói data khi train trên dataset lớn.gcsfusecsi-checkpointing— write throughput cao để save checkpoint multi-GB mà không pause training step.gcsfusecsi-serving— tích hợp Rapid Cache (Anywhere Cache) để load model weights cho inference.
Khi Pod dùng profile, CSI driver scan bucket (size, object count) và node (RAM, Local SSD, GPU/TPU) rồi tự tính cache size + mount options tối ưu. Kiểm tra nhanh bằng kubectl get sc -l gke-gcsfuse/profile=true.
Vì sao quan trọng
Với các model ngày càng lớn (Llama 3 405B, Qwen3 235B, DeepSeek-V3), thời gian load weights trở thành bottleneck chính khi scale inference hoặc khởi động lại replica. Mỗi phút Pod chờ data là phút GPU/TPU đắt tiền đang idle — một node H100 8x có thể tốn vài chục USD/giờ chỉ để đứng chờ I/O.
Profiles đưa best practice FUSE tuning của đội storage Google vào mặc định. ML platform team không còn phải debug OOM vì cache quá lớn, hay serving chậm vì thiếu Rapid Cache, hay training step giật vì read-ahead đặt sai. Quan trọng hơn: cùng một bucket có thể backing cả training, checkpointing và serving — trước đây phải config 3 kiểu khác nhau, giờ chỉ đổi storageClassName.
Điểm đáng chú ý về triết lý: thay vì để user tự tune, CSI driver đọc tín hiệu runtime (bucket size, node RAM, Local SSD, loại accelerator) rồi suy ra config phù hợp — tương tự cách Kubernetes scheduler đã làm cho CPU/memory request.
Thông số kỹ thuật
| Profile | Mount profile | Tối ưu cho |
|---|---|---|
gcsfusecsi-training | profile:aiml-training | High-throughput read, GPU/TPU data loading |
gcsfusecsi-checkpointing | profile:aiml-checkpointing | High-throughput write, checkpoint save |
gcsfusecsi-serving | Rapid Cache + read_ahead_kb=131072 | Model load, inference, buffered read |
Các tham số chung: fuseMemoryAllocatableFactor=0.7 (cap cache RAM ở 70% allocatable), fuseEphemeralStorageAllocatableFactor=0.85, bucketScanResyncPeriod=168h, bucketScanTimeout=2m, fuseFileCacheMediumPriority (ưu tiên RAM hoặc Local SSD). Serving profile thêm anywhereCacheZones, anywhereCacheTTL (default 1h), anywhereCacheAdmissionPolicy.
So sánh với các lựa chọn khác
| Cách tiếp cận | Ưu | Nhược |
|---|---|---|
| FUSE Profiles (mới) | Auto-tune, resource-aware, POSIX | Yêu cầu GKE 1.35.1+ |
| FUSE CSI driver thô | Linh hoạt tối đa | Phải tune tay hàng chục flag |
| Filestore (NFS quản lý) | Quen POSIX | Đắt hơn, ràng buộc region |
| GCS API trực tiếp | Nhanh, gần metal | Phải viết lại app, không POSIX |
| Stage-in Local SSD | Rất nhanh khi đã copy xong | Script tay, không scale cho dataset lớn |
Use cases
- Training LLM / foundation model: đọc dataset hàng chục TB từ GCS, đảm bảo accelerator utilization > 90%.
- Checkpointing dài: save weight + optimizer state hàng trăm GB giữa step, không nghẹt throughput mạng.
- Inference cold-start: case study chính thức — Qwen3-235B-A22B 480GB trên TPU: 39h → 14 phút (~170× nhanh hơn) nhờ Rapid Cache warm trong cùng region.
Giới hạn & chi phí
- Yêu cầu GKE ≥
1.35.1-gke.1616000và Cloud Storage FUSE CSI driver bật. - IAM: custom role cần
storage.objects.list,storage.buckets.get,storage.anywhereCaches.*. - Serving profile bắt buộc cluster + bucket cùng region (Rapid Cache).
- Không hỗ trợ: ephemeral volumes, dynamic mounting, custom private sidecar images.
- Chi phí phụ: bucket scan tính Class A ops (list); Serving profile tự bật Rapid Cache nên có phí storage cache.
Tiếp theo
Profiles hiện chỉ phủ 3 pattern cơ bản. Kỳ vọng Google mở rộng sang RAG/embedding pipelines và fine-grained tier caching. Trước mắt, ML platform team nên: (1) nâng GKE lên 1.35.1+, (2) thử gcsfusecsi-serving cho inference workload nặng cold-start, (3) đo lại TTFT / time-to-first-step để thấy impact.
Nguồn: Google Cloud Blog, GKE Docs.


