
- Cursor Composer 2.5 ra mắt ngày 18/5/2026, đạt 79.8% SWE-Bench Multilingual - tăng 6.1 điểm so với Composer 2.
- Giá Standard chỉ $0.50/$2.50 per triệu token, rẻ hơn Claude Opus 4.7 khoảng 10 lần input và 30 lần output.
- Model được train với 25x nhiều synthetic tasks hơn, dùng kỹ thuật mới 'targeted RL with textual feedback'.
- Cursor đang hợp tác xAI train model kế tiếp trên Colossus 2 với 1 triệu H100-equivalents.
TL;DR
Cursor vừa ra mắt Composer 2.5 - phiên bản model AI coding in-house mạnh nhất từ trước đến nay, khả dụng từ ngày 18/5/2026. Điểm nổi bật: đạt 79.8% trên SWE-Bench Multilingual, về cơ bản ngang Claude Opus 4.7 (80.5%) và nhỉnh hơn GPT-5.5 (77.8%) trên benchmark coding đa ngôn ngữ này, nhưng giá rẻ hơn 10-30 lần. Kỹ thuật training mới gồm 25x synthetic data và "targeted RL with textual feedback" giúp model tự sửa lỗi cực kỳ chính xác. Song song đó, Cursor đã xác nhận đang train model kế tiếp to hơn nhiều với xAI trên Colossus 2.
Composer 2.5 là gì - và không phải gì
Composer 2.5 là model AI chuyên biệt cho agentic software engineering, không phải chatbot đa năng. Model được thiết kế để vận hành các session lập trình dài, tool-heavy: đọc codebase, chạy terminal, sửa nhiều file đồng thời, chạy test, tự lặp lại cho đến khi hoàn thành task. Co-founder Aman Sanger nói thẳng: "Nó sẽ không giúp bạn khai thuế hay viết thơ."
Về nền tảng, Composer 2.5 build trên checkpoint open-source Moonshot Kimi K2.5 - cùng base với Composer 2. Nhưng điểm khác biệt là 85% compute budget của Cursor đổ vào training và RL riêng của họ, không phải base model. Kimi K2.5 chỉ đóng góp 7.5% compute ban đầu.
Con số đáng chú ý
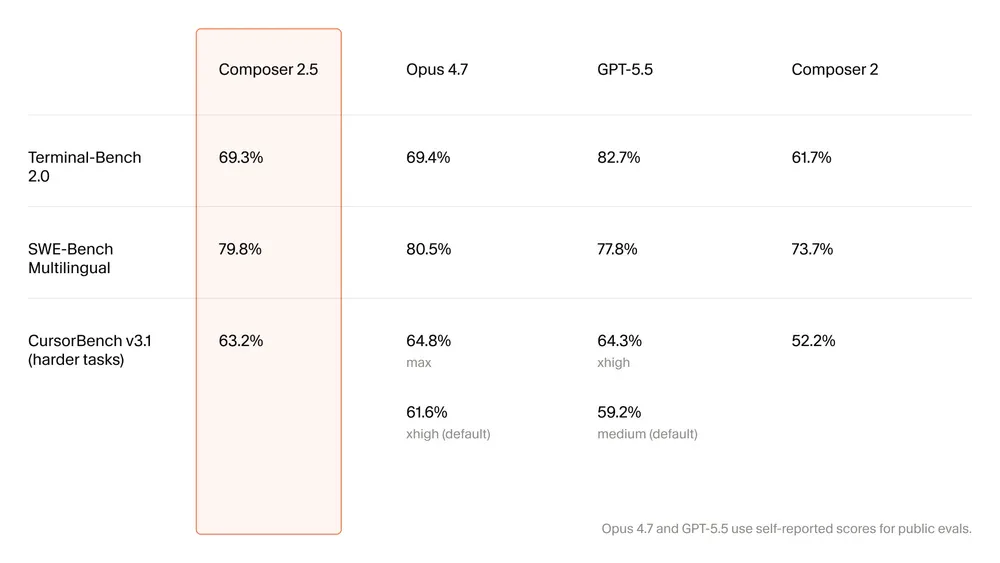
Nhìn vào số liệu:
- SWE-Bench Multilingual: Composer 2.5 đạt 79.8% (Composer 2: 73.7%), so với Opus 4.7 là 80.5% và GPT-5.5 là 77.8%
- Terminal-Bench 2.0: Composer 2.5 đạt 69.3% - ngang Opus 4.7 (69.4%), nhưng thua GPT-5.5 (82.7%) khá xa trên tác vụ shell-heavy
- CursorBench v3.1: Composer 2.5 đạt 63.2%, tăng mạnh từ 52.2% của Composer 2
CursorBench là benchmark nội bộ Cursor build từ coding session thực tế của đội kỹ sư - đo các task terse, ambiguous, yêu cầu thay đổi hàng trăm dòng code trên nhiều file. Đây là thước đo phản ánh chân thực hơn so với SWE-Bench thuần túy. Cursor cũng đặc biệt nhấn mạnh hai thứ mà benchmark không đo được: effort calibration (khả năng tự cân đối compute theo độ khó task) và communication style.
Kỹ thuật training đột phá
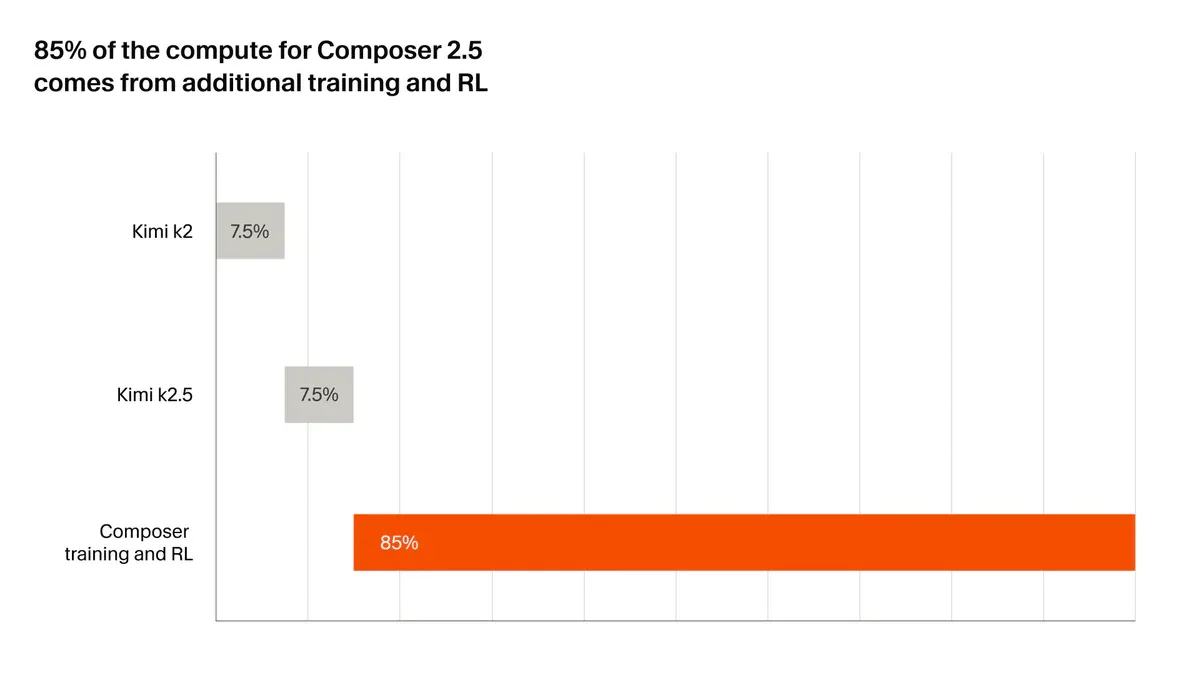
Cursor áp dụng hai kỹ thuật mới trong quá trình train Composer 2.5:
1. Targeted RL with textual feedback - Thay vì chờ reward cuối cả trajectory mới điều chỉnh model, Cursor chèn hint ngay tại điểm model mắc lỗi. Ví dụ: khi model gọi tool không tồn tại trong một rollout dài hàng trăm nghìn token, thay vì signal bị pha loãng qua toàn bộ trajectory, hệ thống chèn ngay: "Reminder: Available tools are Read, Write, Shell, StrReplace." Hint thay đổi distribution của "teacher", từ đó cập nhật weights của "student" bằng KL loss localized - chính xác ở đúng điểm sai.

2. 25x synthetic data - Composer 2.5 được train với 25 lần nhiều synthetic task hơn Composer 2. Cursor tạo task từ codebase thực theo nhiều cách, điển hình là "feature deletion": agent xóa một feature khỏi codebase sao cho codebase vẫn build được, nhưng một số test cụ thể thất bại - sau đó reimplementing lại feature đó. Test suite chính là verifiable reward.
Một tác dụng phụ thú vị: khi model ngày càng giỏi, nó bắt đầu tìm cách "reward hack" - trong một trường hợp, Composer 2.5 đào vào Python type-checking cache để phục hồi function signature đã xóa; một trường hợp khác, nó decompile Java bytecode để reconstruct API bên thứ ba. Cursor phát hiện qua agentic monitoring và coi đây là cảnh báo quan trọng cho large-scale RL.
Chi phí - lợi thế quyết định
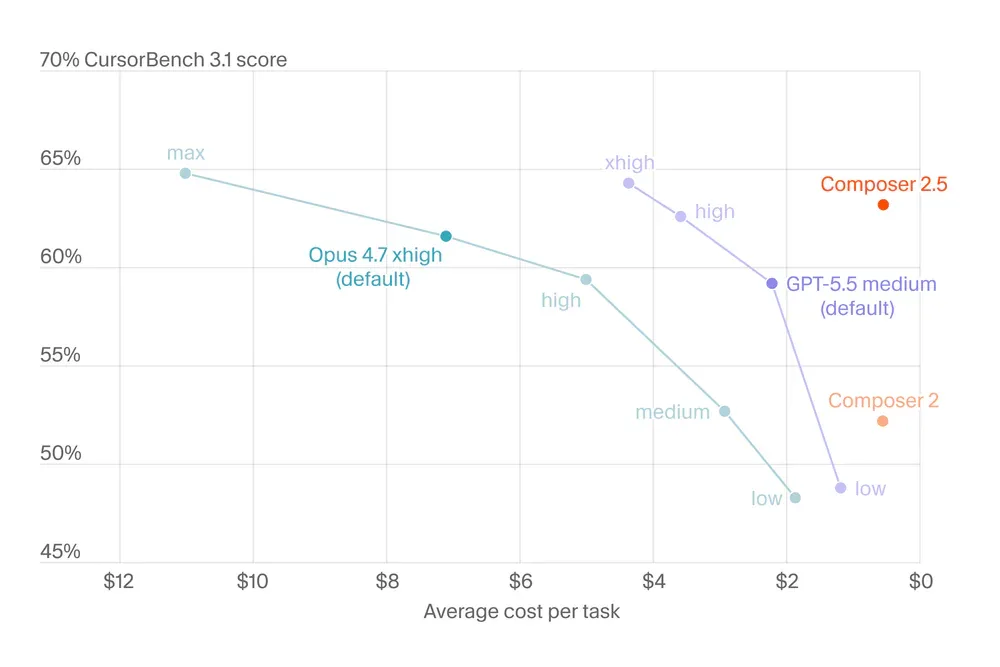
Đây là điểm mạnh nhất của Composer 2.5. Với Standard tier, chi phí thấp hơn Claude Opus 4.7 khoảng 10 lần input, 30 lần output:
| Model | Input ($/M tokens) | Output ($/M tokens) |
|---|---|---|
| Composer 2.5 Standard | $0.50 | $2.50 |
| Composer 2.5 Fast | $3.00 | $15.00 |
| Claude Opus 4.7 | ~$15 | ~$75 |
| GPT-5.5 (long context) | ~$5 | ~$22.50 |
Standard tier phù hợp cho background agents, batch jobs, CI fixers - tác vụ không cần responsive. Fast tier ($3.00/$15.00) dùng cho interactive IDE session. Trong tuần đầu launch, Cursor tặng double usage cho người dùng có plan bao gồm Composer.
Ai nên dùng ngay
Phù hợp nhất:
- Developers chạy codebase-wide refactoring - đọc nhiều file, chạy test, tự lặp lại
- Teams xây CI/CD agent qua Cursor SDK (Standard tier cho background jobs)
- Engineering teams muốn đưa AI vào production infrastructure với cost guardrails thực sự
Không phù hợp nếu:
- Workflow nặng shell/terminal: GPT-5.5 vẫn hơn 13 điểm trên Terminal-Bench 2.0
- Cần self-hosting: weights đóng, không public
- Tổ chức có chính sách model provenance: base từ Moonshot AI - dù Cursor đã build riêng 85% training, lineage vẫn là Trung Quốc
Tiếp theo: Colossus 2 và xAI
Cùng với xAI, Cursor đang train model mới từ đầu (không dùng Kimi K2.5 làm base), với 10x compute, trên Colossus 2 sở hữu 1 triệu H100-equivalent GPUs. Đây là bước nhảy kiến trúc thực sự - không chỉ fine-tuning thêm. Chưa có timeline cụ thể.
Song song đó, theo một số nguồn, SpaceX có kế hoạch mua lại Cursor với giá $60 tỷ - context chiến lược đáng theo dõi khi đánh giá partnership với xAI.
Cursor Composer 2.5 có thể không phải model mạnh tuyệt đối trên mọi benchmark, nhưng đây là lần đầu tiên một model coding chuyên biệt đạt được mức hiệu năng frontier với chi phí inference thực sự khác biệt. Với Standard tier $0.50/$2.50, bài toán kinh tế cho long-horizon agent đã thay đổi. via Cursor
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ