
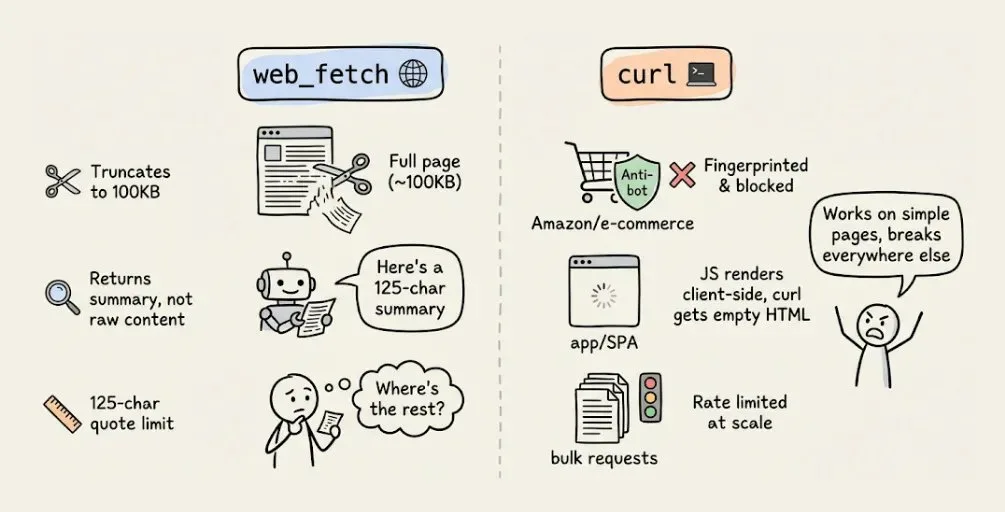
- web_fetch của Claude Code không trả raw content - nó chạy qua Haiku và chỉ trả về summary với giới hạn 125 ký tự.
- Bright Data fix vấn đề web scraping.
- InsForge fix vấn đề backend integration.
- Cả hai tool đều open-source và có thể cài trong 1 lệnh.
TL;DR
Claude Code có hai context gap mà không CLAUDE.md, subagent hay rule file nào fix được. Cả hai đều fail theo cùng một cách: agent không thấy những gì nó cần, rồi đốt token cố gắng tìm. Bright Data fix vấn đề web scraping. InsForge fix vấn đề backend integration. Cả hai đều open-source.
Hai điểm mù của Claude Code
Điểm mù 1 - Web scraping. Khi Claude Code gọi web_fetch, tool này không trả raw content. Nó chạy trang qua Claude Haiku với một user prompt, rồi trả về phần trả lời của Haiku - bị giới hạn 125 ký tự quote. Bạn không thể dùng nó để extract full tutorial, product spec, hay nội dung thread.
Còn curl? Trả raw HTML nhưng bị chặn bởi anti-bot protection trên Amazon, LinkedIn, phần lớn e-commerce. Không render được JavaScript SPA. Fail ở scale vì rate limiting. Cả hai đều truncate ở ~100KB.
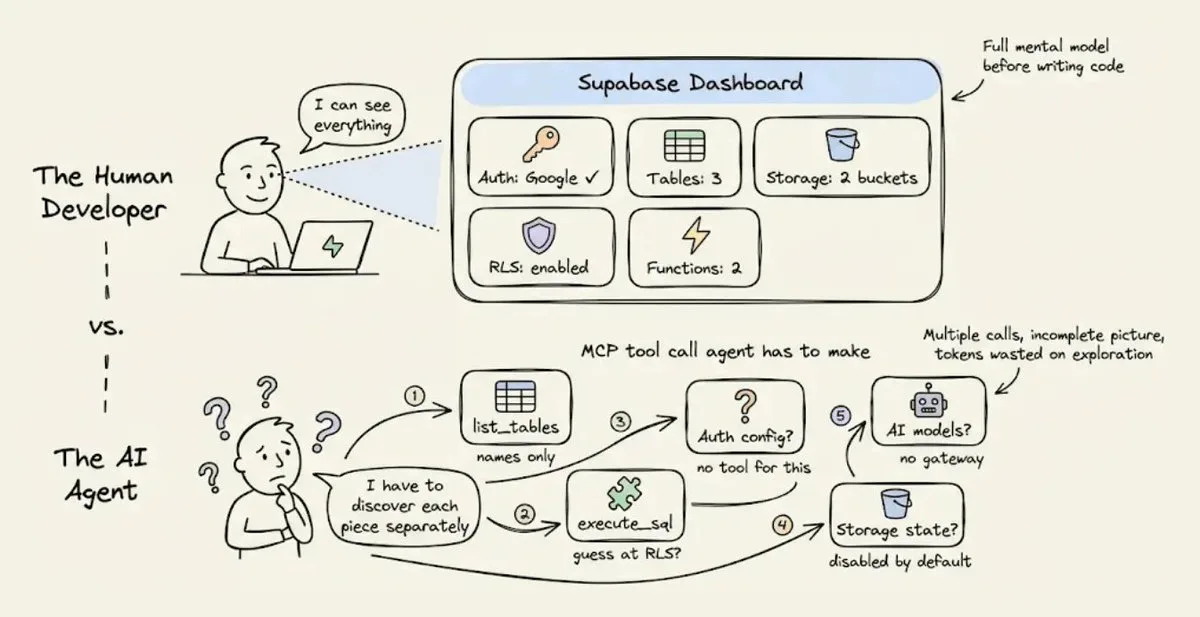
Điểm mù 2 - Backend integration. Khi Claude Code nói chuyện với Supabase qua MCP, nó phải khám phá state qua nhiều call riêng lẻ (list_tables, execute_sql, list_extensions), mỗi call chỉ trả về partial view. Auth provider config không queryable được. Khi có lỗi, error message không phân biệt được platform-level hay code-level rejection, khiến agent bước vào retry loop đốt token với mỗi lần thử. Trong một test thực tế, một RAG app xây trên Supabase tiêu 10.4M token và cần 10 lần fix thủ công.
Dưới nắp capô: web_fetch thực sự làm gì
Pipeline của web_fetch hoạt động theo 5 bước:
Validate và normalize URL (giới hạn ~2000 ký tự)
Domain safety check (deny-list + robots.txt)
Fetch với max 10MB, truncate về 100KB Markdown
Convert HTML sang Markdown qua Turndown library
LLM pass qua Haiku 3.5 với empty system prompt - trả về summary, không phải raw content
Kết quả là model chính nhận được câu trả lời đã được filter, không phải source material đầy đủ. Với một trang 100KB, bạn đang tốn ~25,000 token chỉ để nhận một bản tóm tắt. Content quan trọng mất đi trước khi Claude thậm chí nhìn thấy nó.
Bright Data fix vấn đề web scraping
Bright Data skill (open-source) thêm scraping infrastructure xử lý mọi thứ mà web_fetch và curl không làm được.
Agent nhận được một four-tier fallback tự động escalate theo yêu cầu của target site:
Native fetch
curl
Browser automation
Residential proxy network với automatic CAPTCHA solving
Nhưng capability hữu ích hơn cho agent workflow là structured data extraction. Thay vì raw HTML mà agent phải parse, Bright Data cung cấp pre-built extractor cho 40+ platform - Amazon, LinkedIn, Instagram, TikTok, YouTube, Reddit - trả về clean JSON với các field cụ thể như giá sản phẩm, review score, profile data, post content.
npx skills add brightdata/skillsLệnh này cài nhiều skill: scraping, search, structured data feeds, MCP orchestration (60+ tools), SDK best practices, và bdata CLI. Bright Data cũng có free tier với 5,000 MCP request/tháng - đủ để thử trước khi upgrade.
Khi nào cần Bright Data thay vì native tools? Với Reddit thread (rate limiting aggressive), Amazon product page (anti-bot detection), LinkedIn profile (browser fingerprinting), và JavaScript SPA (cần full browser render mới load được content) - đây là những nguồn mà native tools thất bại.
InsForge fix vấn đề backend integration
Cùng một RAG app tiêu 10.4M token trên Supabase chỉ tiêu 3.7M token trên InsForge với zero error. Chi phí giảm từ $9.21 xuống $2.81. Kết quả được chia sẻ bởi AI engineer Avi Chawla ngày 21/4/2026.
InsForge (open-source, Apache 2.0) hoạt động như backend context engineering layer cho agent. Thay vì để agent tự khám phá state qua nhiều call, InsForge cung cấp đúng infrastructure pattern mà agent cần ngay từ đầu.
# Bước 1: Cài 4 Skills (documentation + diagnostic layer)
npx skills add insforge/insforge-skills
# Bước 2: Link CLI với project (execution layer)
npx @insforge/cli link --project-id <project-id>Bốn Skills được cài:
insforge - SDK patterns
insforge-cli - infrastructure commands
insforge-debug - failure diagnostics (phân biệt platform-level vs code-level error)
insforge-integrations - third-party auth providers
Tổng metadata cost khi khởi động session: ~714 token - rất nhỏ so với lợi ích giảm được.
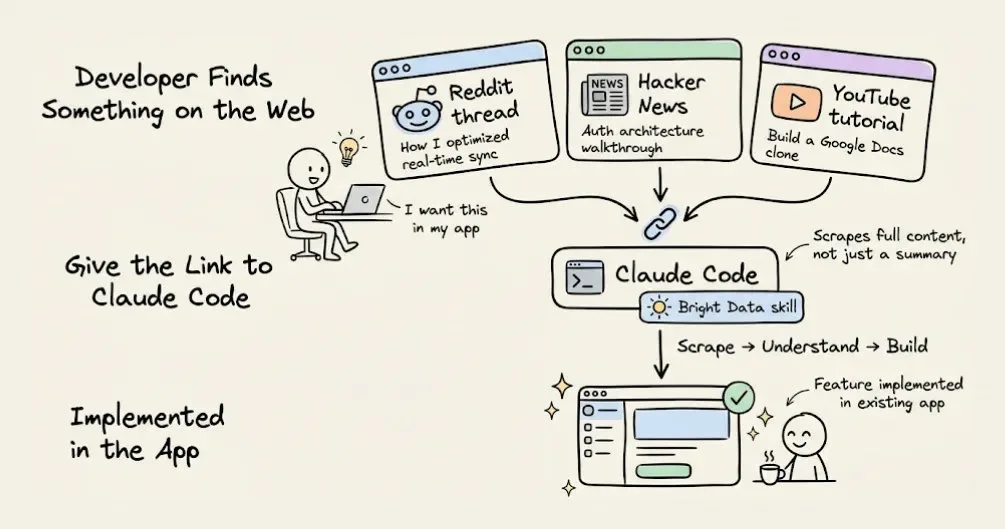
Thực tế: Clone Google Docs từ một prompt
Với cả hai skill, workflow trở thành:
Cung cấp link YouTube tutorial 10 tiếng cho Claude Code
Bright Data scrape full video content (transcript, metadata, structured description)
Claude dùng content đó làm build spec
InsForge xử lý toàn bộ backend trong một shot: Google OAuth, database schema với RLS, storage, edge functions, model gateway cho GPT-4o chat
Kết quả: Google Docs clone hoạt động với real-time editing, Google OAuth, và AI-powered document chat - từ một prompt duy nhất, zero error.
Workflow này không giới hạn ở tutorial. Bất kỳ technical content nào trên web đều có thể thành build spec:
Reddit thread mô tả cách optimize real-time sync
Hacker News discussion về auth architecture
Product page của competitor có feature đáng replicate
So sánh trước - sau
Metric | Vanilla (Supabase MCP) | InsForge |
|---|---|---|
Token tiêu thụ | 10.4M token | 3.7M token (-64%) |
Chi phí | $9.21 | $2.81 (-69%) |
Lỗi cần fix tay | 10 lần | 0 |
Backend setup | Nhiều call, partial view | One-shot |
Khi nào cần dùng
Với web sources cơ bản (trang tĩnh, không có anti-bot, không cần JavaScript render), native tools vẫn đủ dùng. Bright Data cần thiết khi target site chủ động chặn scraping - Reddit, Amazon, LinkedIn, và các JavaScript SPA.
Với backend integration, InsForge hữu ích nhất khi bạn build app có nhiều backend service liên kết (auth + database + storage + edge functions). Chi phí 714 token metadata đổi lại 3x ít token toàn session và zero retry loop.
Anthropic ra mắt Agent Skills (beta) vào tháng 10/2025. Cả hai skill đều là một phần của hệ sinh thái open agent skills - tương thích với 40+ coding agent (Claude Code, Cursor, Windsurf).
Bright Data Skills repo: github.com/brightdata/skills
InsForge repo: github.com/InsForge/InsForge
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ