
- Context Engineering không phải Prompt Engineering: thay vì nghĩ "hỏi như thế nào", bạn phải nghĩ "Agent thấy gì trước khi hỏi" - gồm 4 lớp: system prompt, external data, implicit data và feedback loop.
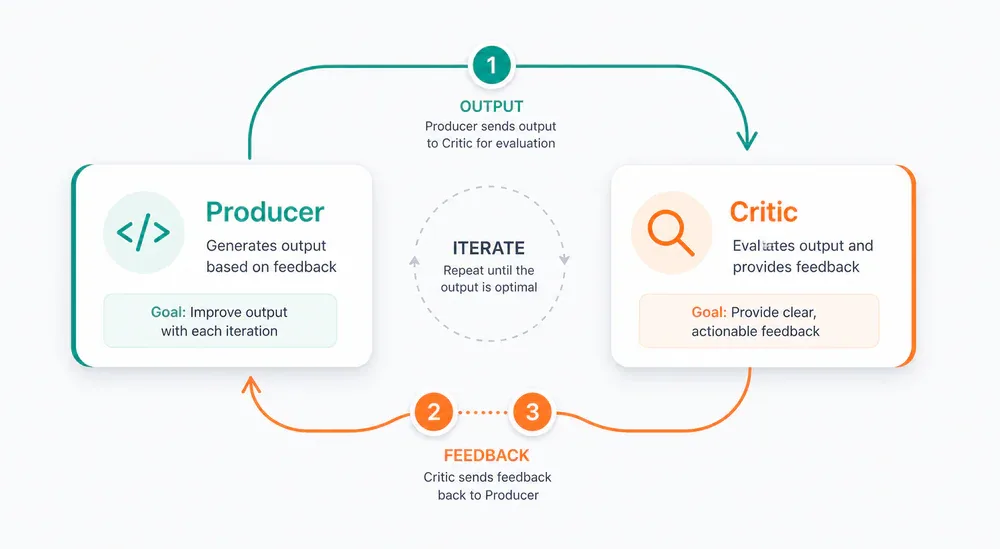
- Reflection Pattern dùng 2 Agent riêng biệt (Producer + Critic) với system prompt khác nhau - cùng một LLM tự review bản thân sẽ luôn nói "ổn rồi".
TL;DR
Đây là phần 2 trong series phân tích "Agentic Design Patterns" của Antonio Gullí (Springer 2025). Phần 1 đã giải thích 4 cấp độ Agent và tại sao hầu hết thứ được gọi là "AI Agent" thực ra là Level 0. Phần này đi vào hai concept kỹ thuật quan trọng nhất quyển sách: Context Engineering và Reflection Pattern.
Nếu phải chọn một điều để mang về từ 472 trang sách này, đó là: Prompt Engineering quản lý bạn hỏi gì. Context Engineering quản lý Agent thấy gì. Hai thứ hoàn toàn khác nhau, và cái thứ hai mới là thứ quyết định Agent của bạn có hoạt động được trong môi trường thực tế hay không.
Context Engineering - Khái Niệm Bị Đánh Giá Thấp Nhất
Prompt Engineering đã trở thành một kỹ năng phổ biến từ 2022-2023. Bạn học cách viết prompt rõ ràng, thêm few-shot examples, dùng chain-of-thought, đặt role cho model. Những kỹ thuật này hoạt động tốt cho các tác vụ đơn giản, một lượt.
Nhưng khi bạn xây Agent - thứ cần nhớ context qua nhiều bước, dùng tool, lập kế hoạch và tự điều chỉnh - Prompt Engineering bắt đầu vỡ. Vấn đề điển hình:
Prompt ngày càng phình to vì bạn cố nhồi mọi thứ vào
Model quên chi tiết từ đầu conversation khi context dài ra
Instruction cho tool bị chôn vùi trong đống text, model bỏ qua
Hallucination tăng khi context không có cấu trúc
Gullí gọi hiện tượng này là "context rot": khi context quá dài và không được lọc, attention của model bị phân tán, accuracy giảm. Thêm nhiều thông tin không giúp ích - thêm đúng thông tin mới là điều quan trọng.
Context Engineering giải quyết đúng vấn đề này. Định nghĩa trong sách: không phải nhồi thông tin, mà là tinh chọn, cắt bớt và đóng gói context. Câu sách mà tác giả tweet nhấn mạnh: "Để AI đạt độ chính xác cao nhất, cần cho nó context ngắn, tập trung và sắc bén."
Gullí chia Context Engineering thành 4 lớp:
Lớp 1 - System Prompt: Định nghĩa Agent là ai, tone ra sao, ranh giới là gì. Đây là lớp duy nhất hầu hết mọi người viết. Cần thiết nhưng chưa đủ.
Lớp 2 - External Data: Documents được RAG retrieve, return value từ tool calls, dữ liệu API real-time. Đây là điểm mà phần lớn developer gặp khó: biết cần feed data vào, nhưng không biết feed như thế nào để không làm model bị overwhelmed. Best practice của sách: chỉ đưa vào phần dữ liệu thực sự cần thiết cho bước tiếp theo, không dump toàn bộ.
Lớp 3 - Implicit Data: Thông tin Agent nên biết mà user không nói ra - user identity, interaction history, environment state, mối quan hệ giữa các entities. Ví dụ từ sách: user nói "gửi email cho John xác nhận cuộc họp ngày mai", Agent cần tự biết cuộc họp ngày mai là gì, John là ai trong calendar. Không phải user cần giải thích, Agent phải tự inference.
Lớp 4 - Feedback Loop: Agent tự đánh giá chất lượng output sau mỗi lần chạy, điều chỉnh context strategy cho lần kế tiếp. Sách gọi đây là "automated context optimization" - Google Vertex AI Prompt Optimizer là implementation thực tế của concept này.
Lớp 4 là điểm phân biệt rõ nhất giữa Level 1 và Level 2 Agent: Level 1 dùng tool nhưng không tự cải thiện qua thời gian. Level 2 có feedback loop - mỗi lần chạy là một lần học.
Reflection Pattern - 2 Agent Tốt Hơn 1
Đây là pattern mà yanhua1010 đánh giá là có giá trị thực chiến cao nhất trong toàn bộ quyển sách. Và sau khi đọc qua implementation, khó mà phản bác.
Ý tưởng cơ bản nghe đơn giản: Agent làm xong việc, tự review lại, phát hiện vấn đề thì tự sửa. Nhưng cách implement mới là điều quan trọng.
Sách nói rõ: Producer và Critic phải là hai Agent khác nhau, với hai system prompt khác nhau. Lý do: cùng một persona review chính nó sẽ luôn có blind spot. Bạn để cùng một LLM viết code rồi review code đó, xác suất cao nó sẽ nói "code này ổn". Không phải LLM dối - là vì nó không thể thoát ra khỏi framing của chính nó.
Ví dụ cụ thể từ sách:
Producer prompt: "Bạn là Python developer. Viết một function tính giai thừa, xử lý edge cases và exceptions."
Critic prompt: "Bạn là senior engineer khó tính. Review từng dòng code, kiểm tra bug, style, edge cases bị bỏ sót và chỗ có thể cải thiện. Nếu code hoàn hảo thì output CODE_IS_PERFECT, nếu không thì liệt kê toàn bộ vấn đề."
Rồi chạy trong một loop:
Producer viết code
Critic review
Producer sửa theo feedback
Critic review lại
Lặp đến khi Critic output CODE_IS_PERFECT hoặc đạt max iteration
Pattern này không chỉ dùng cho code. Viết bài, lập kế hoạch, tóm tắt tài liệu, giải bài toán logic - Producer-Critic model đều áp dụng được. Sách liệt kê 7 ứng dụng khác nhau.
Chi Phí và Best Practices
Gullí không bỏ qua phần thường bị lờ đi trong hầu hết tutorial: Reflection có chi phí thực tế.
Mỗi reflection cycle = một LLM call mới. Càng nhiều iteration, càng tốn tiền. Quan trọng hơn: conversation history phình ra theo từng vòng - các phiên bản cũ và feedback của Critic chiếm dần context window, làm giảm không gian reasoning thực sự có thể dùng được.
Best practice từ sách:
Đặt max iteration cứng - sách dùng 3. Không để loop chạy vô hạn
Stop ngay khi Critic hài lòng - không cần chạy đủ 3 vòng nếu vòng 2 đã pass
Không đuổi theo hoàn hảo - 3 vòng với chất lượng tốt tốt hơn 10 vòng với diminishing returns
Điều này nghe hiển nhiên nhưng trong thực tế ít được chú ý. Nhiều implementation Reflection đang chạy loop không giới hạn hoặc đặt max quá cao (10, 20 lần), vừa tốn tiền vừa không cải thiện thêm được gì.
Một lưu ý nữa từ sách: với Reflection, dùng model mạnh hơn cho Critic thường cho kết quả tốt hơn nhiều. Producer có thể là model nhỏ hơn, Critic nên là model có khả năng reasoning tốt nhất bạn có thể afford.
Kết - Phần 2
Context Engineering và Reflection Pattern là hai concept mà ai đang xây AI Agent nghiêm túc đều cần hiểu rõ. Context Engineering trả lời câu hỏi "Agent cần biết gì để hoạt động đúng" - không phải nhiều hơn mà là đúng hơn. Reflection Pattern trả lời câu hỏi "làm thế nào để Agent tự cải thiện output" - câu trả lời là cần hai Agent với hai góc nhìn độc lập.
Phần 3 (phần cuối) sẽ cover: 6 Multi-Agent communication topologies, Memory 3-tier model, 5 dự đoán về tương lai Agent (trong đó có một prediction cực kỳ táo bạo), và 3 việc bạn có thể làm ngay sau khi đọc xong.